







类PPOConfig继承于PPOConfig
class PPOConfig(AlgorithmConfig):algo = (
PPOConfig()
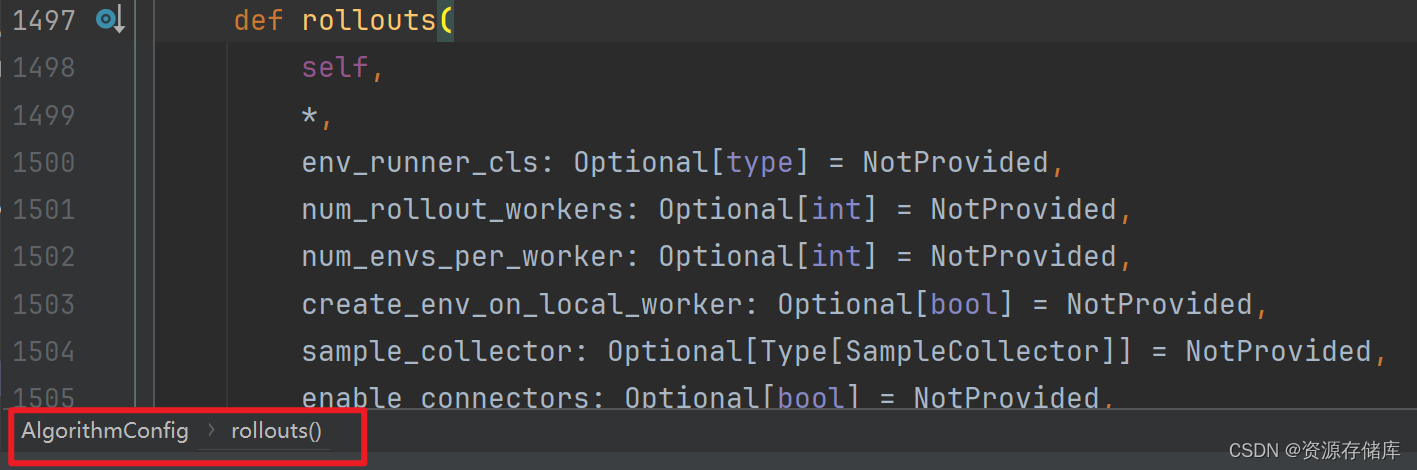
.rollouts(num_rollout_workers=1)
.resources(num_gpus=0)
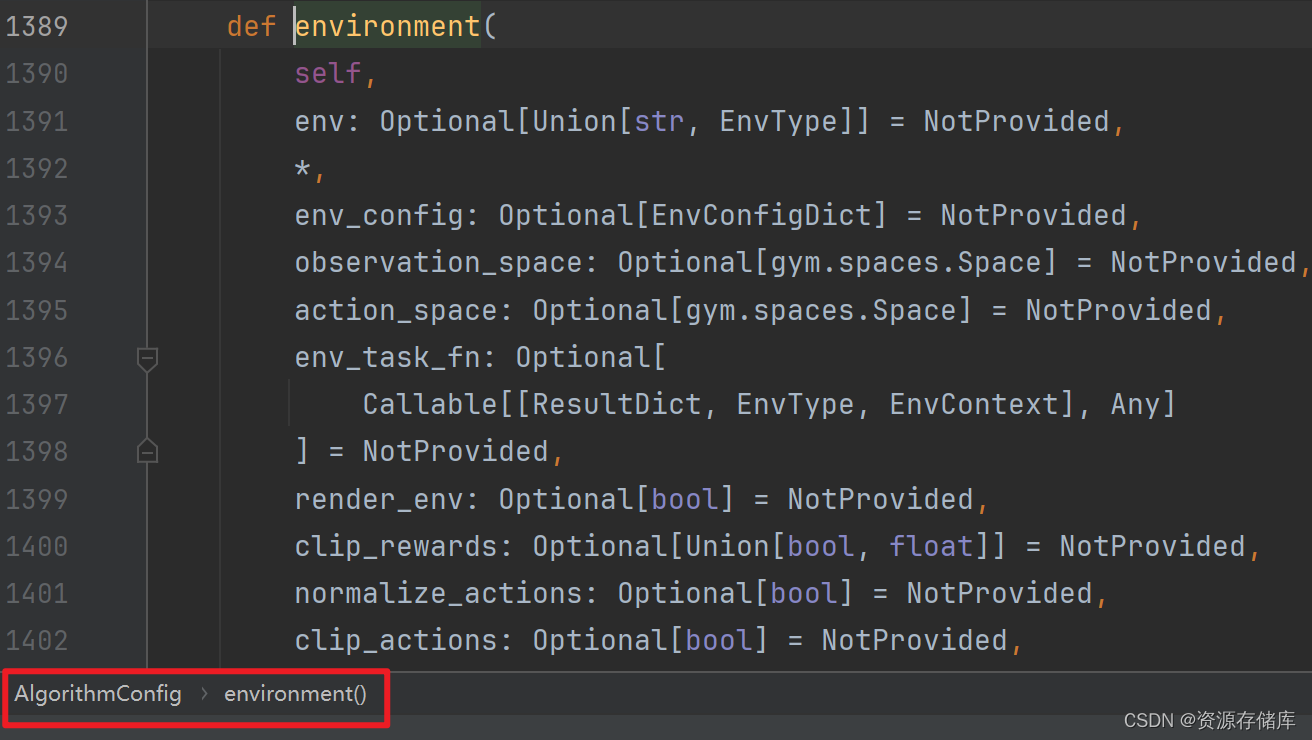
.environment(env="CartPole-v1")
.build()
)

class PPOConfig(AlgorithmConfig):
"""Defines a configuration class from which a PPO Algorithm can be built.
.. testcode::
from ray.rllib.algorithms.ppo import PPOConfig
config = PPOConfig()
config = config.training(gamma=0.9, lr=0.01, kl_coeff=0.3,
train_batch_size=128)
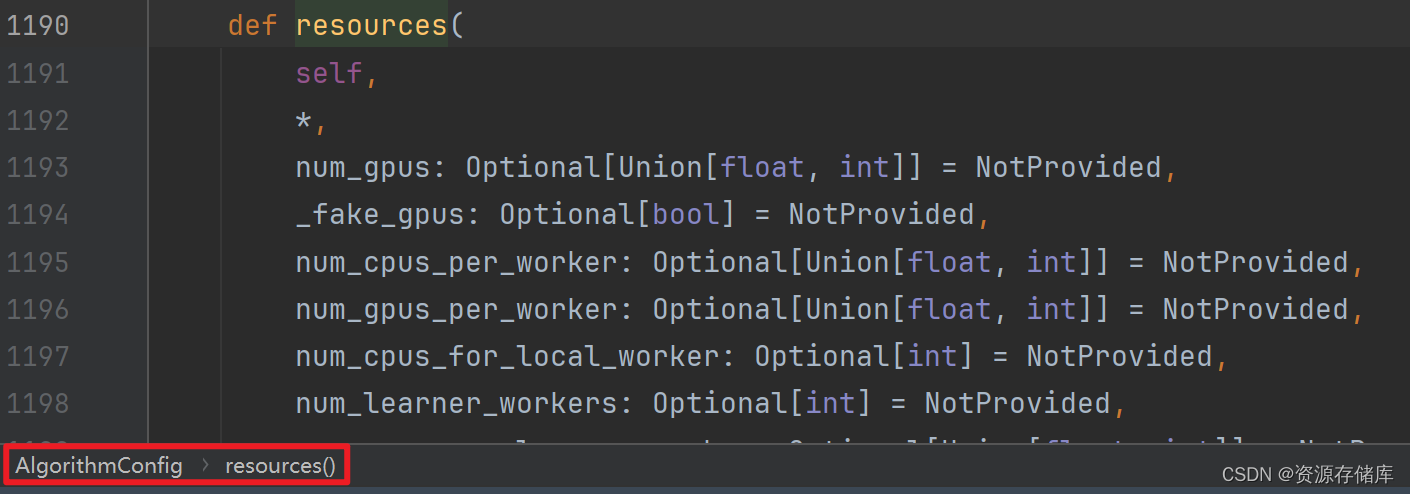
config = config.resources(num_gpus=0)
config = config.rollouts(num_rollout_workers=1)
# Build a Algorithm object from the config and run 1 training iteration.
algo = config.build(env="CartPole-v1")
algo.train()
.. testcode::
from ray.rllib.algorithms.ppo import PPOConfig
from ray import air
from ray import tune
config = PPOConfig()
# Print out some default values.
# Update the config object.
config.training(
lr=tune.grid_search([0.001 ]), clip_param=0.2
)
# Set the config object's env.
config = config.environment(env="CartPole-v1")
# Use to_dict() to get the old-style python config dict
# when running with tune.
tune.Tuner(
"PPO",
run_config=air.RunConfig(stop={"training_iteration": 1}),
param_space=config.to_dict(),
).fit()
.. testoutput::
:hide:
...
"""
def __init__(self, algo_class=None):
"""Initializes a PPOConfig instance."""
super().__init__(algo_class=algo_class or PPO)
# fmt: off
# __sphinx_doc_begin__
self.lr_schedule = None
self.lr = 5e-5
self.rollout_fragment_length = "auto"
self.train_batch_size = 4000
# PPO specific settings:
self.use_critic = True
self.use_gae = True
self.lambda_ = 1.0
self.use_kl_loss = True
self.kl_coeff = 0.2
self.kl_target = 0.01
self.sgd_minibatch_size = 128
# Simple logic for now: If None, use `train_batch_size`.
self.mini_batch_size_per_learner = None
self.num_sgd_iter = 30
self.shuffle_sequences = True
self.vf_loss_coeff = 1.0
self.entropy_coeff = 0.0
self.entropy_coeff_schedule = None
self.clip_param = 0.3
self.vf_clip_param = 10.0
self.grad_clip = None
# Override some of AlgorithmConfig's default values with PPO-specific values.
self.num_rollout_workers = 2
self.model["vf_share_layers"] = False
# __sphinx_doc_end__
# fmt: on
# Deprecated keys.
self.vf_share_layers = DEPRECATED_VALUE
self.exploration_config = {
# The Exploration class to use. In the simplest case, this is the name
# (str) of any class present in the `rllib.utils.exploration` package.
# You can also provide the python class directly or the full location
# of your class (e.g. "ray.rllib.utils.exploration.epsilon_greedy.
# EpsilonGreedy").
"type": "StochasticSampling",
# Add constructor kwargs here (if any).
}
@override(AlgorithmConfig)
def get_default_rl_module_spec(self) -> SingleAgentRLModuleSpec:
from ray.rllib.algorithms.ppo.ppo_catalog import PPOCatalog
if self.framework_str == "torch":
from ray.rllib.algorithms.ppo.torch.ppo_torch_rl_module import (
PPOTorchRLModule,
)
return SingleAgentRLModuleSpec(
module_class=PPOTorchRLModule, catalog_class=PPOCatalog
)
elif self.framework_str == "tf2":
from ray.rllib.algorithms.ppo.tf.ppo_tf_rl_module import PPOTfRLModule
return SingleAgentRLModuleSpec(
module_class=PPOTfRLModule, catalog_class=PPOCatalog
)
else:
raise ValueError(
f"The framework {self.framework_str} is not supported. "
"Use either 'torch' or 'tf2'."
)
@override(AlgorithmConfig)
def get_default_learner_class(self) -> Union[Type["Learner"], str]:
if self.framework_str == "torch":
from ray.rllib.algorithms.ppo.torch.ppo_torch_learner import (
PPOTorchLearner,
)
return PPOTorchLearner
elif self.framework_str == "tf2":
from ray.rllib.algorithms.ppo.tf.ppo_tf_learner import PPOTfLearner
return PPOTfLearner
else:
raise ValueError(
f"The framework {self.framework_str} is not supported. "
"Use either 'torch' or 'tf2'."
)
@override(AlgorithmConfig)
def training(
self,
*,
lr_schedule: Optional[List[List[Union[int, float]]]] = NotProvided,
use_critic: Optional[bool] = NotProvided,
use_gae: Optional[bool] = NotProvided,
lambda_: Optional[fl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1659
1659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











