







 QTRAN是一种新型的多智能体强化学习方法,旨在不受加法/单调性限制地成功分解任何可分解任务。通过学习状态值函数,QTRAN将原始联合动作-值函数转换为易于分解的形式,同时保持相同的最优动作。与VDN和QMIX相比,QTRAN在矩阵游戏和复杂环境(如多域高斯挤压和改良捕食者-猎物)中表现出更优的性能,尤其是在那些更积极惩罚非合作行为的任务中。
QTRAN是一种新型的多智能体强化学习方法,旨在不受加法/单调性限制地成功分解任何可分解任务。通过学习状态值函数,QTRAN将原始联合动作-值函数转换为易于分解的形式,同时保持相同的最优动作。与VDN和QMIX相比,QTRAN在矩阵游戏和复杂环境(如多域高斯挤压和改良捕食者-猎物)中表现出更优的性能,尤其是在那些更积极惩罚非合作行为的任务中。
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement learning
QTRAN:学习因式分解与转换以实现合作式多智能体强化学习
Abstract 摘要
We explore value-based solutions for multi-agent reinforcement learning (MARL) tasks in the centralized training with decentralized execution (CTDE) regime popularized recently. However, VDN and QMIX are representative examples that use the idea of factorization of the joint action-value function into individual ones for decentralized execution. VDN and QMIX address only a fraction of factorizable MARL tasks due to their structural constraint in factorization such as additivity and monotonicity.
In this paper, we propose a new factorization method for MARL, QTRAN, which is free from such structural constraints and takes on a new approach to transforming the original joint action-value function into an easily factorizable one, with the same optimal actions.
QTRAN guarantees more general factorization than VDN or QMIX, thus covering a much wider class of MARL tasks than does previous methods. Our experiments for the tasks of multi-domain Gaussian-squeeze and modified predator-prey demonstrate QTRAN’s superior performance with especially larger margins in games whose payoffs penalize non-cooperative behavior more aggressively.
我们探索了最近流行的集中式训练和分散执行(CTDE)制度中多智能体强化学习(MARL)任务的基于价值的解决方案。然而,VDN 和 QMIX 是具有代表性的例子,它们使用将联合行动价值函数分解为单个函数的思想进行去中心化执行。VDN 和 QMIX 由于在因式分解中的结构约束(如可加性和单调性)而只能处理一小部分可分解的 MARL 任务。
在本文中,我们提出了一种新的MARL因式分解方法QTRAN,该方法摆脱了这种结构约束,并采用了一种新的方法,将原始的联合动作-值函数转换为易于分解的函数,并具有相同的最优作用。
QTRAN 保证了比 VDN 或 QMIX 更通用的因式分解,因此比以前的方法覆盖了更广泛的 MARL 任务。
我们对多域高斯挤压和改良捕食者-猎物任务的实验表明,QTRAN在游戏中具有卓越的性能,在收益更积极地惩罚不合作行为的游戏中,其利润率尤其大。
多智能体强化学习, 深度强化学习, 多智能体系统
1 Introduction
1 引言
Reinforcement learning aims to instill in agents a good policy that maximizes the cumulative reward in a given environment. Recent progress has witnessed success in various tasks, such as Atari games (Mnih et al., 2015), Go (Silver et al., 2016, 2017), and robot control (Lillicrap et al., 2015), just to name a few, with the development of deep learning techniques. Such advances largely consist of deep neural networks, which can represent action-value functions and policy functions in reinforcement learning problems as a high-capacity function approximator.
However, more complex tasks such as robot swarm control and autonomous driving, often modeled as cooperative multi-agent learning problems, still remain unconquered due to their high scales and operational constraints such as distributed execution.
强化学习旨在向智能体灌输一个好的策略,在给定的环境中最大化累积奖励。最近的进展见证了各种任务的成功,例如雅达利游戏(Mnih et al., 2015)、Go (Silver et al., 2016, 2017) 和机器人控制(Lillicrap et al., 2015),仅举几例,随着深度学习技术的发展。
这些进步主要由深度神经网络组成,它可以将强化学习问题中的动作-价值函数和策略函数表示为高容量函数逼近器。
然而,更复杂的任务,如机器人群控制和自动驾驶,通常被建模为合作的多智能体学习问题,由于其高规模和分布式执行等操作限制,仍然没有被征服。
The use of deep learning techniques carries through to cooperative multi-agent reinforcement learning (MARL). MADDPG (Lowe et al., 2017) learns distributed policy in continuous action spaces, and COMA (Foerster et al., 2018) utilizes a counterfactual baseline to address the credit assignment problem. Among value-based methods, value function factorization (Koller & Parr, 1999; Guestrin et al., 2002a; Sunehag et al., 2018; Rashid et al., 2018) methods have been proposed to efficiently handle a joint action-value function whose complexity grows exponentially with the number of agents.
深度学习技术的使用贯穿于协作式多智能体强化学习 (MARL)。MADDPG(Lowe等人,2017)在连续动作空间中学习分布式策略,而COMA(Foerster等人,2018)利用反事实基线来解决信用分配问题。
在基于价值的方法中,价值函数分解(Koller & Parr, 1999;Guestrin等人,2002a;Sunehag 等人,2018 年;Rashid et al., 2018) 已经提出了有效处理联合动作-值函数的方法,其复杂性随着智能体的数量呈指数级增长。
Two representative examples of value function factorization include VDN (Sunehag et al., 2018) and QMIX (Rashid et al., 2018).
VDN factorizes the joint action-value function into a sum of individual action-value functions.
QMIX extends this additive value factorization to represent the joint action-value function as a monotonic function — rather than just as a sum — of individual action-value functions, thereby covering a richer class of multi-agent reinforcement learning problems than does VDN.
However, these value factorization techniques still suffer structural constraints, namely, additive decomposability in VDN and monotonicity in QMIX, often failing to factorize a factorizable task.
A task is factorizable if the optimal actions of the joint action-value function are the same as the optimal ones of the individual action-value functions, where additive decomposability and monotonicity are only sufficient — somewhat excessively restrictive — for factorizability.
价值函数分解的两个代表性例子包括 VDN(Sunehag 等人,2018 年)和 QMIX(Rashid 等人,2018 年)。
VDN 将联合作用值函数分解为单个作用值函数的总和。
QMIX扩展了这种加性值分解,将联合动作-价值函数表示为单个动作-价值函数的单调函数,而不仅仅是一个总和,从而涵盖了比VDN更丰富的多智能体强化学习问题。
然而,这些值因式分解技术仍然受到结构性约束,即VDN中的加法可分解性和QMIX中的单调性,通常无法分解可分解的任务。
如果联合作用-价值函数的最优作用与单个作用-价值函数的最优作用相同,则任务是可分解的,其中加性可分解性和单调性仅足以(有点过度限制)可分解性。
Contribution
贡献
In this paper, we aim at successfully factorizing any factorizable task, free from additivity/monotonicity concerns. We transform the original joint action-value function into a new, easily factorizable one with the same optimal actions in both functions. This is done by learning a state-value function, which corrects for the severity of the partial observability issue in the agents.
在本文中,我们的目标是成功地分解任何可分解的任务,而不受可加性/单调性问题的影响。我们将原来的联合动作-价值函数转换为一个新的、易于分解的函数,在两个函数中具有相同的最优动作。这是通过学习状态值函数来完成的,该函数可纠正代理中部分可观测性问题的严重性。
We incorporate the said idea in a novel architecture, called QTRAN, consisting of the following inter-connected deep neural networks: (i) joint action-value network, (ii) individual action-value networks, and (iii) state-value network. To train this architecture, we define loss functions appropriate for each neural network. We develop two variants of QTRAN: QTRAN-base and QTRAN-alt, whose distinction is twofold: how to construct the transformed action-value functions for non-optimal actions; and the degree of stability and convergence speed. We assess the performance of QTRAN by comparing it against VDN and QMIX in three environments. First, we consider a simple, single-state matrix game that does not satisfy additivity or monotonicity, where QTRAN successfully finds the joint optimal action, whereas neither VDN nor QMIX does. We then observe a similarly desirable cooperation-inducing tendency of QTRAN in more complex environments: modified predator-prey games and multi-domain Gaussian squeeze tasks. In particular, we show that the performance gap between QTRAN and VDN/QMIX increases with environments having more pronounced non-monotonic characteristics.
我们将上述想法整合到一种称为QTRAN的新架构中,该架构由以下相互连接的深度神经网络组成:
(i)联合动作-价值网络,
(ii)单个动作-价值网络,
以及(iii)状态-价值网络。
为了训练这个架构,我们定义了适合每个神经网络的损失函数。我们开发了QTRAN的两种变体:QTRAN-base和QTRAN-alt,它们的区别是双重的:如何为非最优动作构造转换后的动作值函数;以及稳定性和收敛速度的程度。
我们通过将QTRAN与VDN和QMIX在三种环境中的性能进行比较来评估QTRAN的性能。
首先,我们考虑一个简单的单态矩阵博弈,它不满足可加性或单调性,其中 QTRAN 成功地找到了联合最优动作,而 VDN 和 QMIX 都不满足。
然后,我们观察到QTRAN在更复杂的环境中具有类似的理想合作诱导趋势:改进的捕食者-猎物博弈和多域高斯挤压任务。
特别是,我们发现QTRAN和VDN/QMIX之间的性能差距随着具有更明显的非单调特性的环境而增加。
Related work
相关工作
Extent of centralization varies across the spectrum of cooperative MARL research. While more decentralized methods benefit from scalability, they often suffer non-stationarity problems arising from a trivialized superposition of individually learned behavior. Conversely, more centralized methods alleviate the non-stationarity issue at the cost of complexity that grows exponentially with the number of agents.
集中化的程度在合作 MARL 研究的范围内各不相同。虽然更分散的方法受益于可扩展性,但它们经常遭受非平稳性问题,这是由于个体学习行为的微不足道的叠加而产生的。相反,更集中的方法以复杂性为代价来缓解非平稳性问题,复杂性随着智能体数量的增加呈指数级增长。
Prior work tending more towards the decentralized end of the spectrum include Tan (1993), whose independent Q-learning algorithm exhibits the greatest degree of decentralization. Tampuu et al. (2017) combines this algorithm with deep learning techniques presented in DQN (Mnih et al., 2015). These studies, while relatively simpler to implement, are subject to the threats of training instability, as multiple agents attempt to improve their policy in the midst of other agents, whose policies also change over time during training. This simultaneous alteration of policies essentially makes the environment non-stationary.
Tan ( 1993) 的独立 Q 学习算法表现出最大程度的去中心化。Tampuu et al. (2017) 将该算法与 DQN 中提出的深度学习技术相结合(Mnih et al., 2015)。这些研究虽然实施起来相对简单,但受到训练不稳定的威胁,因为多个智能体试图在其他智能体中改进他们的政策,而这些智能体的政策在训练期间也会随着时间的推移而改变。这种政策的同时变化基本上使环境变得非静止。
The other end of the spectrum involves some centralized entity to resolve the non-stationarity problem. Guestrin et al. (2002b) and Kok & Vlassis (2006) are some of the earlier representative works. Guestrin et al. (2002b) proposes a graphical model approach in presenting an alternative characterization of a global reward function as a sum of conditionally independent agent-local terms. Kok & Vlassis (2006) exploits the sparsity of the states requiring coordination compared to the whole state space and then tabularize those states to carry out tabular Q-learning methods as in Watkins (1989).
频谱的另一端涉及一些中心化实体来解决非平稳性问题。Guestrin et al. (2002b) 和 Kok & Vlassis (2006) 是一些早期的代表性作品。Guestrin et al. ( 2002b) 提出了一种图形模型方法,将全局奖励函数的替代表征呈现为条件独立智能体-局部项的总和。Kok & Vlassis ( 2006) 利用了与整个状态空间相比需要协调的状态的稀疏性,然后将这些状态表格化以执行表格 Q 学习方法,如 Watkins ( 1989)。
The line of research positioned mid-spectrum aims to put together the best of both worlds. More recent studies, such as COMA (Foerster et al., 2018), take advantage of CTDE (Oliehoek et al., 2008); actors are trained by a joint critic to estimate a counterfactual baseline designed to gauge each agent’s contribution to the shared task. Gupta et al. (2017) implements per-agent critics to opt for better scalability at the cost of diluted benefits of centralization. MADDPG (Lowe et al., 2017) extends DDPG (Lillicrap et al., 2015) to the multi-agent setting by similar means of having a joint critic train the actors. Wei et al. (2018) proposes Multi-Agent Soft Q-learning in continuous action spaces to tackle the relative overgeneralization problem (Wei & Luke, 2016) and achieves better coordination. Other related work includes CommNet (Sukhbaatar et al., 2016), DIAL (Foerster et al., 2016), ATOC (Jiang & Lu, 2018), and SCHEDNET (Kim et al., 2019), which exploit inter-agent communication in execution.
定位于中频谱的研究路线旨在将两全其美的结合在一起。最近的研究,如COMA(Foerster等人,2018年),利用了CTDE(Oliehoek等人,2008年);参与者由联合评论家训练,以估计一个反事实基线,旨在衡量每个参与者对共同任务的贡献。Gupta等人(2017)实施了每个代理的批评者,以牺牲集中化稀释的好处为代价来选择更好的可扩展性。MADDPG (Lowe et al., 2017) 将 DDPG (Lillicrap et al., 2015) 扩展到多智能体环境,通过类似的方式让联合评论家培训演员。Wei et al. ( 2018) 提出了连续动作空间中的多智能体软 Q 学习来解决相对过度泛化问题 (Wei & Luke, 2016) 并实现了更好的协调。其他相关工作包括CommNet(Sukhbaatar等人,2016),DIAL(Foerster等人,2016),ATOC(江&Lu,2018)和SCHEDNET(Kim等人,2019),它们在执行中利用代理间通信。
On a different note, two representative examples of value-based methods have recently been shown to be somewhat effective in analyzing a class of games. Namely, VDN (Sunehag et al., 2018) and QMIX (Rashid et al., 2018) represent the body of literature most closely related to this paper. While both are value-based methods and follow the CTDE approach, the additivity and monotonicity assumptions naturally limit the class of games that VDN or QMIX can solve.
另一方面,最近有两个基于价值的方法的代表性例子被证明在分析一类博弈方面有些有效。也就是说,VDN(Sunehag et al., 2018)和 QMIX (Rashid et al., 2018) 代表了与本文最密切相关的文献主体。虽然两者都是基于值的方法并遵循 CTDE 方法,但可加性和单调性假设自然限制了 VDN 或 QMIX 可以解决的游戏类别。
2 Background
2 背景
2.1 Model and CTDE
2.1 模型和 CTDE
DEC-POMDP

We take DEC-POMDP (Oliehoek et al., 2016) as the de facto standard for modelling cooperative multi-agent tasks, as do many previous works: as a tuple 𝒢=<𝒮,𝒰,�,�,𝒵,�,�,�>, where 𝒔∈𝒮 denotes the true state of the environment. Each agent �∈𝒩:={1,…,�} chooses an action ��∈𝒰 at each time step, giving rise to a joint action vector, 𝒖:=[��]�=1�∈𝒰�. Function �(𝒔′|𝒔,𝒖):𝒮×𝒰�×𝒮↦[0,1] governs all state transition dynamics. Every agent shares the same joint reward function �(𝒔,𝒖):𝒮×𝒰�↦, and �∈[0,1) is the discount factor. Each agent has individual, partial observation �∈𝒵, according to some observation function �(𝒔,�):𝒮×𝒩↦𝒵. Each agent also has an action-observation history ��∈𝒯:=(𝒵×𝒰)∗, on which it conditions its stochastic policy ��(��|��):𝒯×𝒰↦[0,1].
我们将DEC-POMDP(Oliehoek等人,2016)作为建模合作多智能体任务的事实标准,就像以前的许多工作一样:作为元组 𝒢=<𝒮,𝒰,�,�,𝒵,�,�,�> ,其中 𝒔∈𝒮 表示环境的真实状态。每个智能体 �∈𝒩:={1,…,�} 在每个时间步选择一个动作 ��∈𝒰 ,从而产生一个联合动作向量。 𝒖:=[��]�=1�∈𝒰� 函数 �(𝒔′|𝒔,𝒖):𝒮×𝒰�×𝒮↦[0,1] 控制所有状态转换动态。每个代理共享相同的联合奖励函数 �(𝒔,𝒖):𝒮×𝒰�↦ ,并且是 �∈[0,1) 折扣因子。每个智能体都有单独的、部分的观察 �∈𝒵 ,根据一些观察函数 �(𝒔,�):𝒮×𝒩↦𝒵. ,每个智能体也有一个动作观察历史 ��∈𝒯:=(𝒵×𝒰)∗ ,它以此为条件来制定随机策略 ��(��|��):𝒯×𝒰↦[0,1] 。
Training and execution: CTDE
训练和执行:CTDE
Arguably the most naïve training method for MARL tasks is to learn the individual agents’ action-value functions independently, i.e., independent Q-learning. This method would be simple and scalable, but it cannot guarantee convergence even in the limit of infinite greedy exploration. As an alternative solution, recent works including VDN (Sunehag et al., 2018) and QMIX (Rashid et al., 2018) employ centralized training with decentralized execution (CTDE) (Oliehoek et al., 2008) to train multiple agents. CTDE allows agents to learn and construct individual action-value functions, such that optimization at the individual level leads to optimization of the joint action-value function. This in turn, enables agents at execution time to select an optimal action simply by looking up the individual action-value functions, without having to refer to the joint one. Even with only partial observability and restricted inter-agent communication, information can be made accessible to all agents at training time.
可以说,MARL任务最幼稚的训练方法是独立学习单个智能体的动作-价值函数,即独立的Q-learning。这种方法简单且可扩展,但即使在无限贪婪探索的极限下也无法保证收敛。作为替代解决方案,最近的工作包括 VDN (Sunehag et al., 2018) 和 QMIX (Rashid et al., 2018) 采用集中式训练和分散执行 (CTDE) (Oliehoek et al., 2008) 来训练多个智能体。CTDE允许智能体学习和构造单个动作-价值函数,从而在单个层面进行优化,从而优化联合动作-价值函数。这反过来又使代理在执行时只需查找单个操作值函数即可选择最佳操作,而不必参考联合函数。即使只有部分可观察性和有限的智能体间通信,所有智能体都可以在训练时访问信息。
2.2 IGM Condition and Factorizable Task
2.2 IGM条件和可分解任务
Consider a class of sequential decision-making tasks that are amenable to factorization in the centralized training phase. We first define IGM (Individual-Global-Max):
考虑一类在集中训练阶段适合分解的顺序决策任务。我们首先定义 IGM(Individual-Global-Max):

Definition 1 (IGM).
For a joint action-value function �jt:𝒯�×𝒰�↦, where 𝛕∈𝒯� is a joint action-observation histories, if there exist individual action-value functions [��:𝒯×𝒰↦]�=1�, such that the following holds
| argmax𝒖�jt(𝝉,𝒖) | =(argmax�1�1(�1,�1)⋮argmax����(��,��)), | (1) |
then, we say that [��] satisfy IGM for �jt under 𝛕. In this case, we also say that �jt(𝛕,𝐮) is factorized by [��(��,��)], or that [��] are factors of �jt.
那么,我们说 [��] 满足 IGM 为 �jt 下 𝛕 。在这种情况下,我们还说 由 �jt(𝛕,𝐮) [��(��,��)] 分解 或 [��] 是 的 �jt 因数。

定义 1(IGM)。对于联合动作-价值函数 �jt:𝒯�×𝒰�↦ ,如果存在单个动作-价值函数 [��:𝒯×𝒰↦]�=1�, , 𝛕∈𝒯� 则为联合动作-观察历史,使得以下情况成立
Simply put, the optimal joint actions across agents are equivalent to the collection of individual optimal actions of each agent. If �jt(𝝉,𝒖) in a given task is factorizable under all 𝝉∈𝒯�, we say that the task itself is factorizable.
简单地说,跨智能体的最优联合作用等同于每个智能体的单个最优作用的集合。如果 �jt(𝝉,𝒖) 在给定的任务中是可分解的, 𝝉∈𝒯�, 那么我们说任务本身是可分解的。
2.3 VDN and QMIX
2.3 VDN 和 QMIX

Given �jt, one can consider the following two sufficient conditions for IGM:
给定 �jt ,可以考虑 IGM 的以下两个充分条件:
| (Additivity) (添加性) | �jt(𝝉,𝒖)=∑�=1���(��,��), | (2) | ||
| (Monotonicity) (单调性) | ∂�jt(𝝉,𝒖)∂��(��,��)≥0,∀�∈𝒩. | (3) |

VDN (Sunehag et al., 2018) and QMIX (Rashid et al., 2018) are methods that attempt to factorize �jt assuming additivity and monotonicity, respectively. Thus, joint action-value functions satisfying those conditions would be well-factorized by VDN and QMIX. However, there exist tasks whose joint action-value functions do not meet the said conditions. We illustrate this limitation of VDN and QMIX using a simple matrix game in the next section.
VDN(Sunehag等人,2018)和QMIX(Rashid等人,2018)是分别尝试对 �jt 假设可加性和单调性进行因式分解的方法。因此,满足这些条件的联合动作值函数将由 VDN 和 QMIX 很好地分解。但是,有些任务的联合动作值函数不满足上述条件。在下一节中,我们将使用一个简单的矩阵博弈来说明VDN和QMIX的局限性。
3 QTRAN: Learning to Factorize with Transformation
3 QTRAN:学习通过转换进行分解

In this section, we propose a new method called QTRAN, aiming at factorizing any factorizable task. The key idea is to transform the original joint action-value function �jt into a new one �jt′ that shares the optimal joint action with �jt.
在本节中,我们提出了一种称为 QTRAN 的新方法,旨在分解任何可分解的任务。关键思想是将原来的联合动作-值函数转换为一个新的 �jt′ 函数,该函数 �jt 与 �jt.
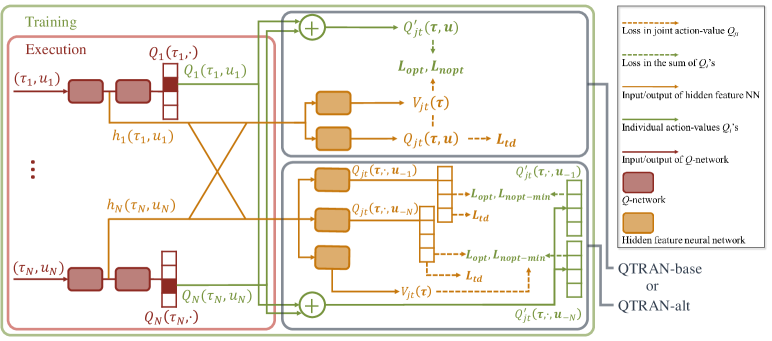
Figure 1:QTRAN-base and QTRAN-alt Architecture
图 1:QTRAN-base 和 QTRAN-alt 架构
3.1 Conditions for the Factor Functions
3.1 因子函数的条件

For a given joint observation 𝝉, consider an arbitrary factorizable �jt(𝝉,𝒖). Then, by Definition 1 of IGM, we can find individual action-value functions [��(��,��)] that factorize �jt(𝝉,𝒖). Theorem 1 states the sufficient condition for [��] that satisfy IGM. Let �¯� denote the optimal local action argmax����(��,��) and 𝒖¯=[�¯�]�=1�,. Also, let 𝑸=[��]∈,� i.e., a column vector of ��,�=1,…,�.
对于给定的联合观察 𝝉 ,考虑一个任意可 �jt(𝝉,𝒖). 分解的 然后,根据 IGM 的定义 1,我们可以找到将 �jt(𝝉,𝒖). 定理 1 分解的单个动作值函数,这些函数 [��(��,��)] 是满足 IGM 的充分条件 [��] 。让我们 �¯� 表示最佳局部作用 argmax����(��,��) 和 𝒖¯=[�¯�]�=1�, 。另外,设 𝑸=[��]∈,� i, ��,�=1,…,�. 即

Theorem 1.
A factorizable joint action-value function �jt(𝛕,𝐮) is factorized by [��(��,��)], if
| ∑�=1���(��,��)−�jt(𝝉,𝒖)+�jt(𝝉)= | 0 | 𝒖=𝒖¯, | (4a) (4a) | ||
| ∑�=1���(��,��)−�jt(𝝉,𝒖)+�jt(𝝉)= | ≥0 | 𝒖≠𝒖¯, | (4b) (4b) |
where 哪里
| �jt(𝝉) | =max𝒖�jt(𝝉,𝒖)−∑�=1���(��,�¯�). |
定理 1.可分解的联合动作-值函数 �jt(𝛕,𝐮) 由以下公式分解:

The proof is provided in the Supplementary. We note that conditions in (4b) are also necessary under an affine transformation. That is, there exists an affine transformation �(𝑸)=�⋅𝑸+�, where �=[���]∈+�×� is a symmetric diagonal matrix with ���>0,∀� and �=[��]∈,� such that if �jt is factorized by [��], then (4b) holds by replacing �� with �����+��. This is because for all �, �� cancels out, and ��� just plays the role of re-scaling the value of ∑�=1��� in multiplicative (with a positive scaling constant) and additive manners, since IGM is invariant to � of [��].
证据在补充文件中提供。我们注意到,在仿射变换下,(4b)中的条件也是必需的。也就是说,存在一个仿射变换 �(𝑸)=�⋅𝑸+�, ,其中 �=[���]∈+�×� 是一个对称对角矩阵 和 ���>0,∀� 使 �=[��]∈,� 得 如果 �jt 由 分解为 [��] ,则 (4b) 成立 替换 �� 为 �����+��. 这是因为对于所有 � , �� 抵消,并且 ��� 只是以乘法(具有正缩放常数)和加法方式重新缩放值 ∑�=1��� 的作用,因为 IGM 不变为 � [��].
Factorization via transformation
通过变换进行因式分解

We first define a new function �jt′ as the linear sum of individual factor functions [��]:
我们首先定义一个新函数 �jt′ 作为单个因子函数 [��] 的线性和:
| �jt′(𝝉,𝒖) | :=∑�=1���(��,��). | (5) |

We call �jt′(𝝉,𝒖) the transformed joint-action value function throughout this paper. Our idea of factorization is as follows: from the additive construction of �jt′ based on [��], [��] satisfy IGM for the new joint action-value function �jt′, implying that [��] are
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











