



sherpa是一个基于下一代 Kaldi 和 onnxruntime 的开源项目,专注于语音识别、文本转语音、说话人识别和语音活动检测(VAD)等功能。该项目支持在没有互联网连接的情况下本地运行,适用于嵌入式系统、Android、iOS、Raspberry Pi、RISC-V 和 x86_64 服务器等多种平台。支持流式语音处理。
https://github.com/k2-fsa/sherpa-onnx
现在很多语音识别都要收费了,之前用过免费的云知声也收费了,之前只使用过 它的TTS,还有免费的离线sdk,现在要做语音唤醒(关键词检测)。试过pocketshpinx,效果很差。偶然看到sherpa,试了试效果不错。但是官方demo没有完整代码(不是没有模型,就是没有so,jar)
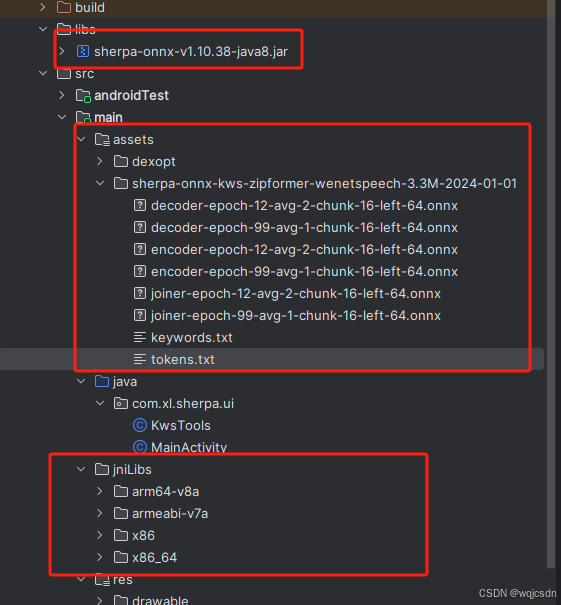
关键就这三个部分jar、assets、jni。然后就是自定义关键词
参考:
Pre-trained models — sherpa 1.3 documentation
主要就是php,会提示缺少库,安装就是了,官方的提示有点坑是这样的
sherpa-onnx-cli text2token \
--tokens sherpa-onnx-kws-zipformer-wenetspeech-3.3M-2024-01-01/tokens.txt \
--tokens-type ppinyin \
keywords_raw.txt keywords.txt把 tokens.txt 和 keywords_raw.txt都放在命令行位置下就好
sherpa-onnx-cli text2token --tokens tokens.txt --tokens-type ppinyin
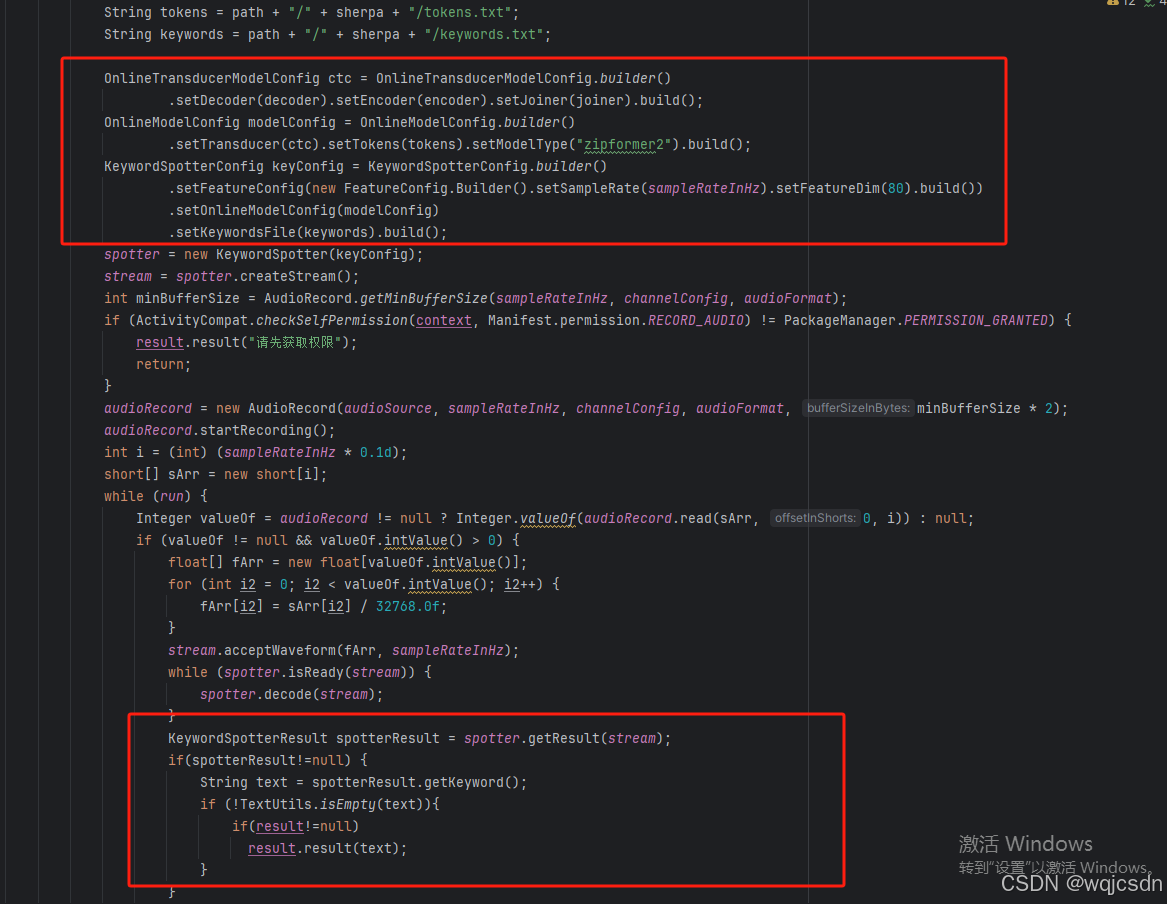
keywords_raw.txt keywords.txt代码中主要就是配置和最后录音转text

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









