







 本文介绍了一种使用Python批量下载知识星球中Word文档的方法。通过分析网页请求,利用postman测试接口,抓取文件列表,并根据file_id获取每篇文章的下载链接,实现自动化下载。
本文介绍了一种使用Python批量下载知识星球中Word文档的方法。通过分析网页请求,利用postman测试接口,抓取文件列表,并根据file_id获取每篇文章的下载链接,实现自动化下载。
加入了知识星球,星主之前发了很多的word文档,如下图
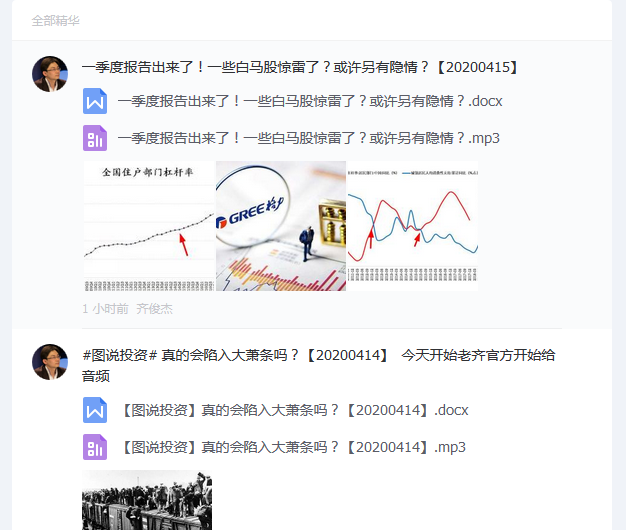
一个一个的下载太麻烦,弄个python统一爬下来。
F12看下路径和请求头,如下
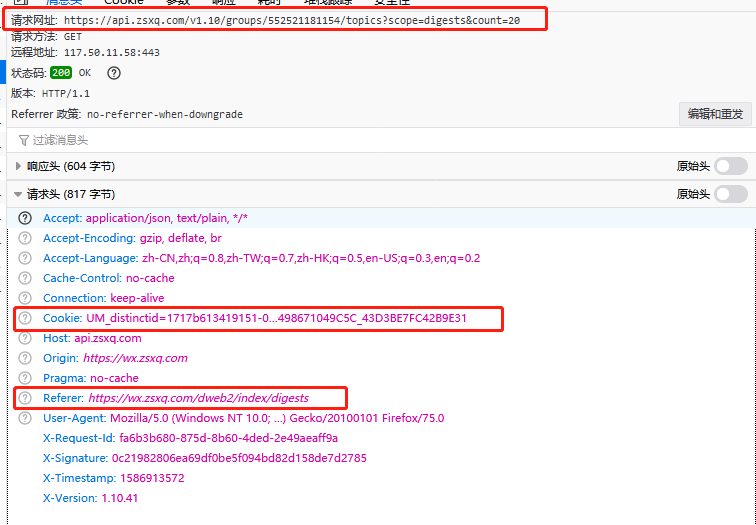
用postman请求下接口,一切正常,能返回所有json信息。
下一步是获取下拉到底部后,加载的更多信息。分析下请求,就是加了个end_time的参数,这个参数是当前页最后一篇文章的创建时间。如下图
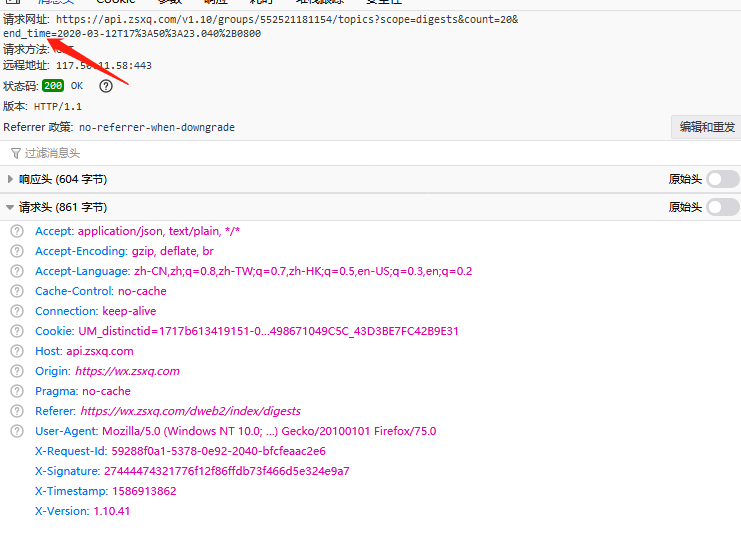
所以,只要拿到当前页的最后一篇文章的创建时间,然后再去请求下一页的内容即可。
第三部是获取下载链接。发现是根据每篇文章的file_id去请求一个方法,得到下载地址。如下图

然后请求https://api.zsxq.com/v1.10/files/88242855454112/download_url 这个地址获取下载地址,postman中请求返回如下

里面的download_url就是下载地址。
down_res = requests.get(download_url)
if down_res.status_code == 200:
with open( 'D:\\360极速浏览器下载\\temp\\'+title, 'wb') as fp:
fp.write(down_res.content)
fp.close()
搞下来就可以了。
附上源码:链接:https://pan.baidu.com/s/1issjMq-v1gaYS5cqZGuCAw
提取码:uqdz

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









