







- GAN
GAN 有两个网络,一个是 generator,一个是 discriminator,通过两个网络互相对抗来达到最好的生成效果。
公式:
![]()
先固定 G,来求解最优的 D


对于一个给定的 x,得到最优的 D 如上图,范围在 (0,1) 内,把最优的 D 带入
![]()
可以得到

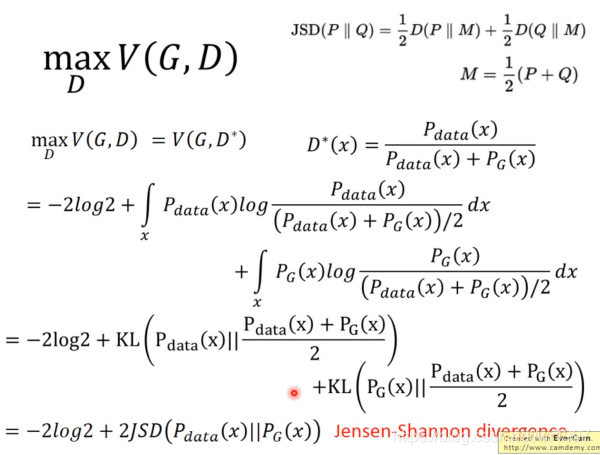
JS divergence 是 KL divergence 的对称平滑版本,表示了两个分布之间的差异
现在我们需要找个 G,来最小化
![]()
观察式子可以发现,当 PG(x)=Pdata(x) 时,G 是最优的。
GAN的训练:
两个网络交替训练,起初有一个G0,D0,先训练D0找到xxxx,然后固定D0开始训练G0,
设定两个loss:一个D的loss,一个G的loss。

如图是一个单向GAN
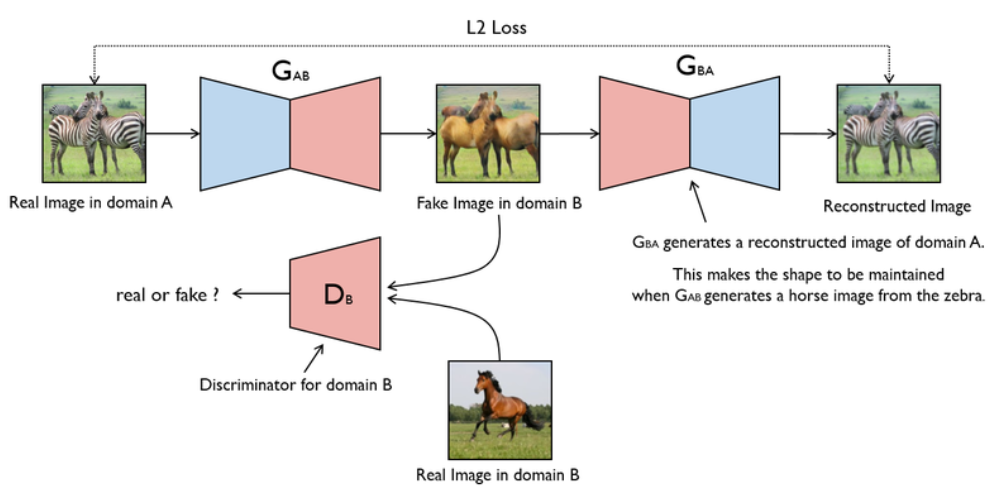
训练这个单向GAN需要两个loss:生成器的重建Loss和判别器的判别Loss。
重建Loss:希望生成的图片Gba(Gab(a))与原图a尽可能的相似。
![]()
判别Loss:生成的假图片和原始真图片都会输入到判别器中。公式为0,1二分类的损失。
![]()
一句话表述GAN
网络中有生成器G(generator)和鉴别器(Discriminator)。
有两个数据域分别为X,Y。G 负责把X域中的数据拿过来尽可能模仿成真实数据并把它们藏在真实数据中,而 D 就尽可能地要把伪造数据和真实数据分开。经过二者的博弈以后,G 的伪造技术越来越厉害,D 的鉴别技术也越来越厉害。直到 D 再也分不出数据是真实的还是 G 生成的数据的时候,这个对抗的过程达到一个动态的平衡。
2. CycleGAN
(ICCV17)
本质上是两个镜像对称的GAN,构成了一个环形的网络。
两个GAN共享两个生成器G和F,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。
(采用两个生成器,是避免所有的x都被映射到同一个Y上,采用两个,既能满足X->Y的映射,也能满足Y->X的映射。这一点其实就是变分自编码器VAE的思想。)
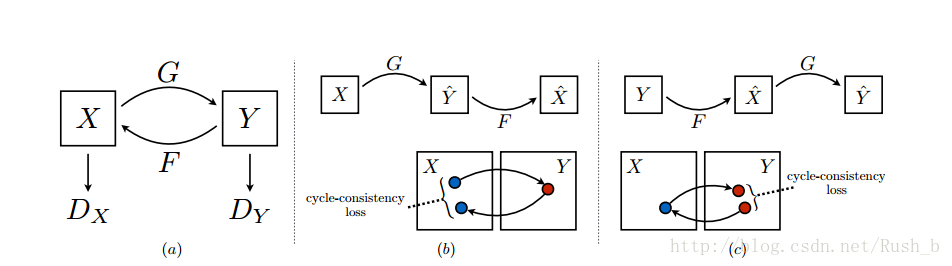
对抗损失
下图是均方误差损失表示:(这是判别器Y对X->Y的映射G的损失,判别器X对Y->X映射的损失也非常类似,这两个是对抗损失)
![]()
循环损失
如下是两个生成器的循环损失,这里其实是L1损。因为网络需要保证生成的图像必须保留有原始图像的特性,所以如果我们使用生成器GenratorA-B生成一张假图像,那么要能够使用另外一个生成器GenratorB-A来努力恢复成原始图像。此过程必须满足循环一致性。
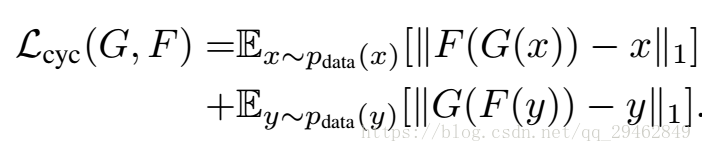
总损失
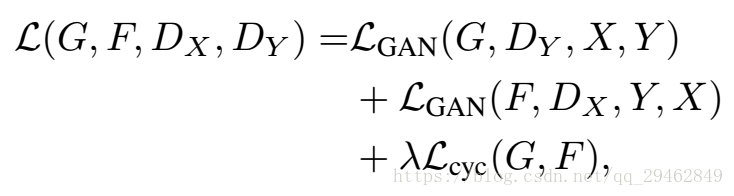
优化
对总损失进行优化,先优化D然后优化G和F,这一点和GAN类似
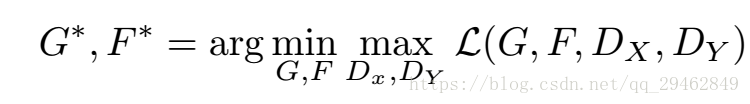
一句话描述:
CycleGAN的目标是学习映射G: X→Y,使用对抗损失无法区分G(X)和Y的分布。所以我们又提出了成对的方向映射F:Y→X,并介绍了cycle consistency 损失来增强使得F(G(X))≈X。(这样可以不要让所有的x都映射到一个y中了。)CycleGAN的创新点就在于其能够在没有成对训练数据的情况下,将图片内容从源域迁移到目标域。CycleGAN在训练时,只需要将源域的图片和目标域的图片作为输入即可,这里并不要求源域跟目标域的图像内容是匹配的。CycleGAN 解决了从一个领域到另一个领域没有成对数据的图像转换问题。
VAE
https://www.sohu.com/a/226209674_500659
该链接文章对于原文清晰分析

- StarGAN
(2018cvpr)
解决图像转换一对多的问题,

左图为一对一图片转换所需的生成器,starGAN如右图。
StarGAN 的简单介绍,主要包含判别器 D 和生成器 G 。(a)D 对真假图片进行判别,真图片判真,假图片判假,真图片被分类到相应域。(b)G 接受真图片和目标域标签并生成假图片;(c)G 在给定原始域标签的情况下将假图片重建为原始图片(重构损失);(d)G 尽可能生成与真实图像无法区分的图像,并且通过 D 分类到目标域。
贡献:
1. StarGAN只要一个G和一个D实现多领域转换
2. 提供一种掩码向量方法,使StarGAN能够控制所有可用的域标签
3. 在人脸属性转移和表情改变方面StarGAN效果很好
对抗loss:

上图中 Discriminator 需要去最大化 D(x) (x 为 Generator 产生的图片) 的 score,意思是 D 需要尽可能正确地识别 x。而 G 需要最小化 1-D(G(x, c)),意思是 G 需要产出尽可能真实的图片使得 D(G(x, c)) 越大越好。
Domain Classification Loss(cls):
对于给定的输入图像x和目标域标签c,我们的目标是将x转换为输出图像y,并将其正确地分类为目标域c。为了达到这个条件,添加了一个辅助分类器去训练 D。在D的top中加入辅助分类器,域分类器loss在优化D和G时都会用到,作者将这一损失分为两个方向,分别用来优化G和D。在G和D中都各加一个分类loss, 一个是真实图片的域分类损失用来优化D,另一个是fake图片的域分类损失来优化G。
(优化D)D的:
![]()
(优化G)G的:
![]()
通过最小化该loss可让图片归类到domain c
在一般情况下需要现将 D 训练一段时间之后才能开始训练 G,因为在 D 效果很差的情况下 G 产生的数据无法分辨真假。
Reconstruction Loss
通过最小化对抗损失与分类损失,G努力尝试做到生成目标域中的现实图片。但是这无法保证学习到的转换只会改变输入图片的域相关的信息而不改变图片内容。所以加上了周期一致性损失
Rec_loss: 在最小化上述两种损失的情况下并不能保证在图片进行 translation 的时候只改变与领域有关的部分而保存其他部分。为解决这个问题,引入 Reconstruction Loss, 目的在于使 inputImage 和重建出来的 image (利用 fakeImage 与 origin-domain 产生出来的图片)越相近越好。
如下图所示,x 为 inputImage,c 为 target-domain, c` 为 origin-domain。
![]()
重构loss,c是目标域,c撇是原域,可以看出经过两次GAN回到了原始图像,是不是很像cycleGAN呢,嗯
完整的loss:

其中 ![]() 和
和![]() 是控制分类误差和重构误差相对于对抗误差的相对权重的超参数。在所有实验中设置
是控制分类误差和重构误差相对于对抗误差的相对权重的超参数。在所有实验中设置![]()
在实际操作上,作者将对抗损失换成了WGAN的对抗损失: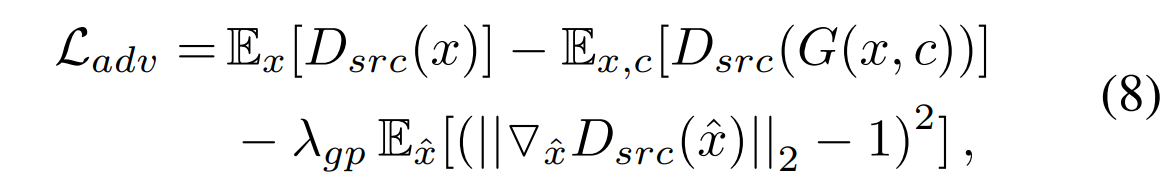
starGan适用于多数据集间的转换。这样就有一个问题,比如另一个数据集没有需要的标签,因为在重构loss里需要域双方都有同类标签,那么该怎么办呢?作者提出了解决办法。
Mask Vector:

其中ci代表图像在第i组数据集的属性经过编码后得到的结果,n为数据集数目(ci可以是one-hot也可以是2分类)。文章中仅涉及两个数据集,n=2。m为该图像所属数据集的编号经过One-hot编码后得到的结果。

在多个 dataset 的情况下提出 mask vector,mask vector 是一个 one-hot vector,表示的为当前提取的数据来源,大小为 dataset 的数量,例如 Celeba,RaFD 两个数据集,若当前提取的为 Celeba 的数据那么 RaFD 的 label 都将被置0。
训练时,生成器中加入标签c,通过这样做,生成器学会忽略未指定的标签,这些标签是零向量,并集中在给定的不为0的标签上,通过在CelebA和RaFD之间交替,判别器学习两个数据集的所有鉴别特征,并且生成器学习控制两个数据集中的所有标签。
对D训练
(a)D对真假图片进行判别,真图片判真,假图片判假,真图片被分类到相应域
对G训练
(b)真图片+目的标签c进入G生成假图片
(c)假图片+原始标签c撇进入G又回去生成重构图片(重构loss)
(d)D对假图片进行判别,判假图片为真
一句话描述:
starGAN顾名思义就是星型GAN结构,其解决的主要问题为 multi-domain 的 image-to-image 转换。相比于传统的拥有 k 个 domain 的多领域图片转换需要训练 k(k-1) 个 generator ,效率极其低下,也无法充分地利用到训练数据,同时传统的解决方法也无法衔接多个数据集的 domains。基于上述问题,starGAN 被提出,starGAN 的基本思想为将 inputImage 和 target domain (一般为随机产生,使用binary 或者 one-hot vector 表示)一起作为 Generator 的输入得到 fakeImage,再将 fakeImage 和 origin domain 的值作为同一个 Generator 的输入得到 reconstructed image ,starGAN 希望的是 reconstructed image 和 inputImage 之间越接近越好。
4.cycleGAN-VC
CycleGAN-VC:使用周期一致的对抗网络进行并行无数据语音转换
该方法可以学习从源语音到目标语音的映射,而无需依赖并行数据。所提出的方法特别值得注意,因为它是通用且高质量的,并且无需任何额外的数据,模块或对齐过程即可工作。
我们的方法称为CycleGAN-VC,它使用具有门控卷积神经网络(CNN)[4]和身份映射的周期一致对抗网络(CycleGAN)
训练过程:

在CycleGAN中,使用对抗损失和周期一致性损失同时学习正向和反向映射(图1(a)(b))。这使得可以从非并行数据中找到最佳的伪对。此外,对抗性损失可以基于不可区分性而使转换后的语音接近目标语音,而无需明确的密度估计。这样可以避免由统计平均引起的过度平滑,这种平滑发生在许多传统的基于统计模型的显式表示数据分布的VC方法中。
循环一致性损失对映射的结构施加了约束。但是,仅保证映射始终保留语言信息是不够的。为了鼓励在不依赖其他模块的情况下保留语言信息,我们引入了一个标识映射损失,它鼓励生成器找到保留输入和输出之间组成的映射(图1(c)(d))。
图1CycleGAN-VC的培训过程。GX→Y是将X转换为Y的正向生成器。GY→X是将Y转换为X的逆生成器。DX和DY分别是X和Y域中的标识符。(a)(b)我们使用对抗性损失和周期一致性损失从未配对的数据中找到最佳伪对。(c)(d)此外,我们使用身份映射损失来保留语言信息。
语音的重要特征之一是它具有顺序和层次结构,例如浊音或清音段以及音素或语素。表示这种结构的有效方法是使用RNN,但是由于并行实现的难度,因此对计算的要求很高。取而代之的是,我们使用门控CNN配置一个CycleGAN,它不仅允许对顺序数据进行并行化,而且还可以实现语言建模[4]和语音建模[6]的最新技术。在门CNN中,门线性单元(GLU)用作激活函数。GLU是一种数据驱动的激活功能,并且门控机制允许根据先前的层状态有选择地传播信息。我们在图2中说明了生成器和鉴别器的网络架构。
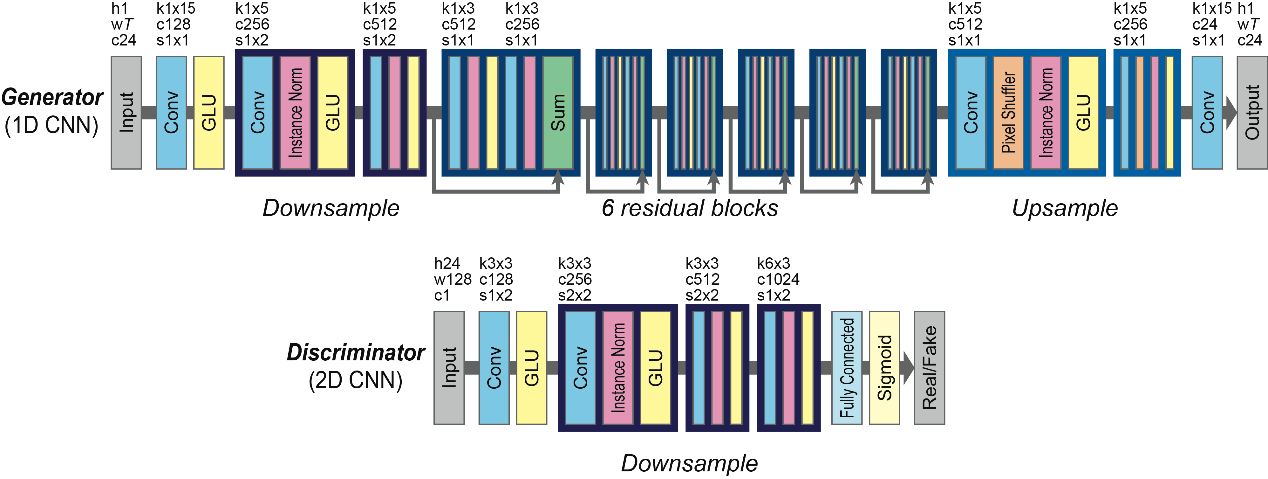
图2.生成器和鉴别器的网络架构。在输入或输出层中,h,w和c分别表示高度,宽度和通道数。在每个卷积层中,k,c和s分别表示内核大小,通道数和步幅大小。由于生成器是完全卷积的,因此它可以接受任意长度T的输入。
CycleGAN-VC使用一维(1D) CNN作为生成器,在保留时间结构的同时,捕捉整个关系和特征方向。这可以看作是逐帧模型的直接时间扩展,该模型只捕获每帧的这些特性的关系。为了在保持输入结构的同时有效地捕获大范围的时间结构,该生成器由下采样层、残差层和上采样层组成
另一个值得注意的地方是CycleGAN-VC使用一个门控CNN来捕捉声学特征的顺序和层次结构
CNN中处理的是什么?
[27] T. Kaneko, H. Kameoka, N. Hojo, Y. Ijima, K. Hiramatsu, and K. Kashino, “Generative adversarial network-based postfilter for statistical parametric speech synthesis,” in Proc. ICASSP, 2017, pp. 4910–4914.根据这篇论文来看,是光谱纹理(spectral texture)。光谱纹理(spectral texture)–> Mel-cepstral系数(MCEP)
CycleGAN-VC使用2D CNN作为鉴别器来聚焦于2D结构(即,2D光谱纹理)。更精确地说,如图3(a)所示,考虑到输入的整体结构,在最后一层使用全连通层来确定真实感。这样的模型称为FullGA。
Instance Norm层:可以理解为对数据做一个归一化的操作。
GLU:在门控CNN中,门控线性单元(GLUs)被用作一个激活函数,GLU是一个数据驱动的激活函数,并且门控机制允许根据先前的层状态选择性地传播信息。(为什么要用激活函数?如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。)
门控CNN思想:模拟lstm的是否遗忘门,或者说判断权重的思想。再做一个和CNN卷积一样参数的filter, 取值0-1,判断这个序列的特征哪些应该被关注,哪些应该被忽略。
损失:
LOSS:CycleGAN- vc使用了一个对抗损失[31]和循环一致性损失[39]。此外,为了鼓励语言信息的保存,CycleGAN-VC还使用了身份映射损失[37]。
对抗性损失:为了使转换后的特征与目标y难以区分,使用对抗性损失:
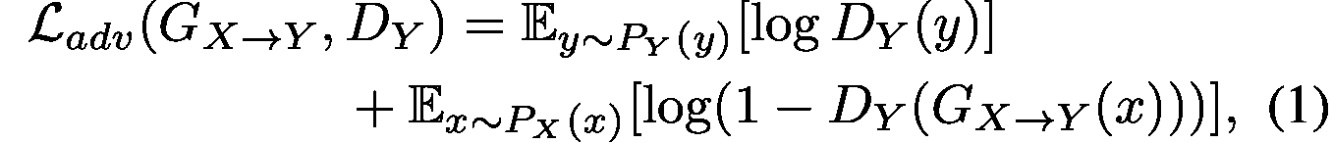
鉴别器试图通过最大化这种损失来寻找实数和转换特征之间的最佳决策边界,而生成器试图通过最小化这种损失来生成可以欺骗的特征。
循环一致性损失:对抗性损失只限制GX→Y (x)服从目标分布,不保证输入输出特征的语言一致性。为了进一步规范映射,使用循环一致性损失:
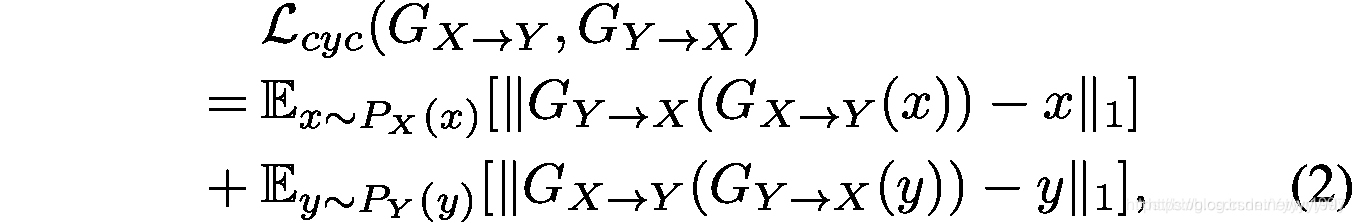
同时学习正反向映射以稳定训练。这种损失促使GX→Y, GY→X通过循环变换找到(X, Y)的最优伪对,如图1(a)所示。
标识映射损失:为了进一步鼓励保存输入,使用标识映射损失: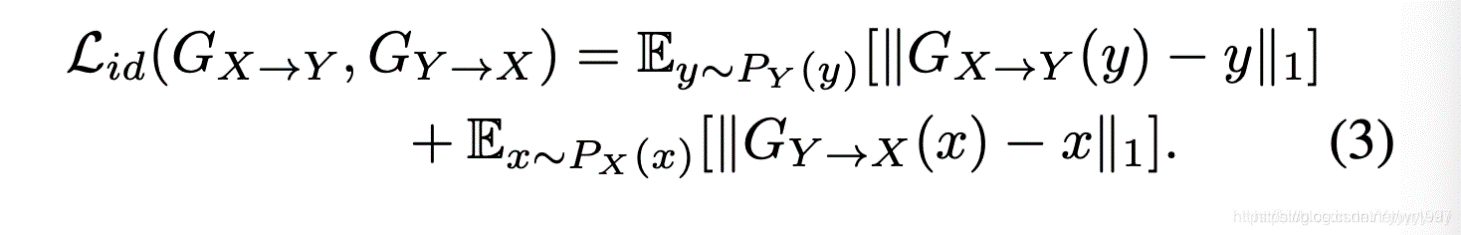
文章使用语音转换挑战2016(VCC 2016)数据集 [7]评估了我们的方法。
为了在非平行条件下评估我们的方法,我们将训练集分为两个没有重叠的子集。
前半部分的81个句子用作源,其他81个句子用于目标。
这意味着CycleGAN-VC是在不利条件下训练的(非并行且数据量的一半)。转换后的语音的质量也可以与基于高斯混合模型的并行VC方法获得的质量相媲美。我们在下面提供语音样本。
5.StarGAN-VC
StarGAN-VC是一种使用称为StarGAN的生成对抗网络(GAN)的变体进行非并行多对多语音转换(VC)的方法。我们的方法特别值得注意,因为它(1)不需要并行发声,转录或时间对齐程序来进行语音生成器训练;(2)使用单个生成器网络同时学习跨不同属性域的多对多映射(3 )能够足够快地生成转换后的语音信号以允许实时实现,并且(4)仅需要几分钟的训练示例即可生成合理逼真的语音。
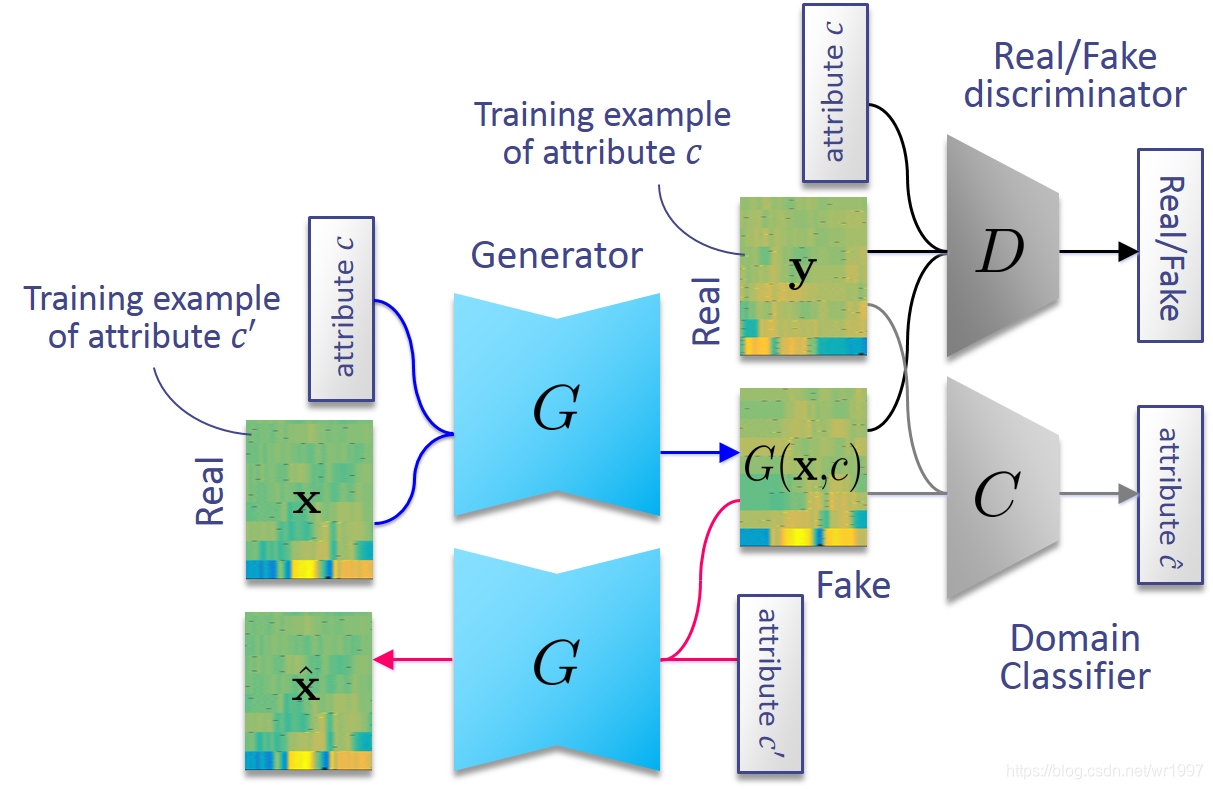
- StarGAN-VC加入了一致性损失(identity loss)
- StarGAN-VC将分类器独立出来
- StarGAN-VC在生成器和判别中都有连接说话人特征向量的操作
- StarGAN-VC使用了GLU激活层
之前提出了一种使用称为循环一致性GAN(CycleGAN)的GAN变体的非并行VC方法,该方法最初是作为使用不成对的训练示例来翻译图像的方法而提出的。虽然CycleGAN-VC仅学习一对一映射,但StarGAN-VC能够使用单个编解码器类型的生成器网络G同时学习多对多映射,其中生成器输出的属性由辅助输入控制c。在这里,Ç表示一个属性标签,表示为一个热向量的串联,每个向量在特定类别的类的索引处用1填充,在其他地方用0填充。例如,如果我们将说话者身份视为唯一的属性类别,则 c将表示为单个“一键通”向量,其中每个元素与另一个说话者相关联。现在,我们希望使G(x,c)像真实语音特征一样真实,并适当地属于属性c。为此,我们引入了一个实/假鉴别符D,它的作用是对输入是真还是假进行分类,以及域分类器C,其作用是预测输入所属的类。通过使用d和Ç,ģ可以以这样的方式被训练G(X,C)被误分类为通过实际的语音特征序列d和正确地分类为属于属性Ç由Ç。我们还将循环一致性损失用于生成器训练,以确保每对属性域之间的映射将保留语言信息。
StarGAN-VC使用对抗性损失进行生成器训练,以鼓励生成器输出与真实语音无法区分,并确保每对属性域之间的映射将保留语言信息。值得注意的是, StarGAN-VC在测试时不需要任何关于输入语音属性的信息。

















 2054
2054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









