






1.
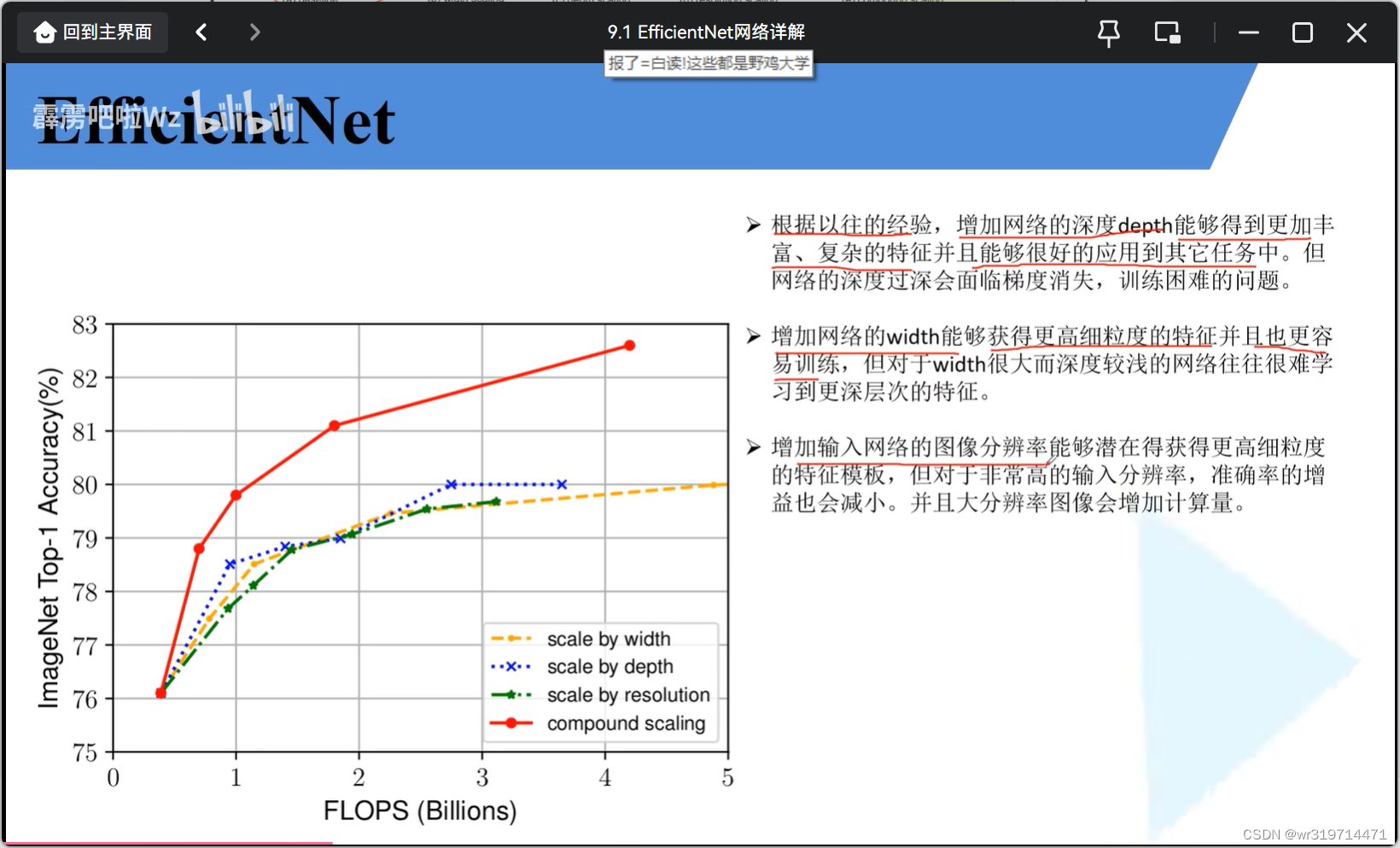
论文中用网络搜索技术去同时探索分辨率,深度,宽度的合理配置
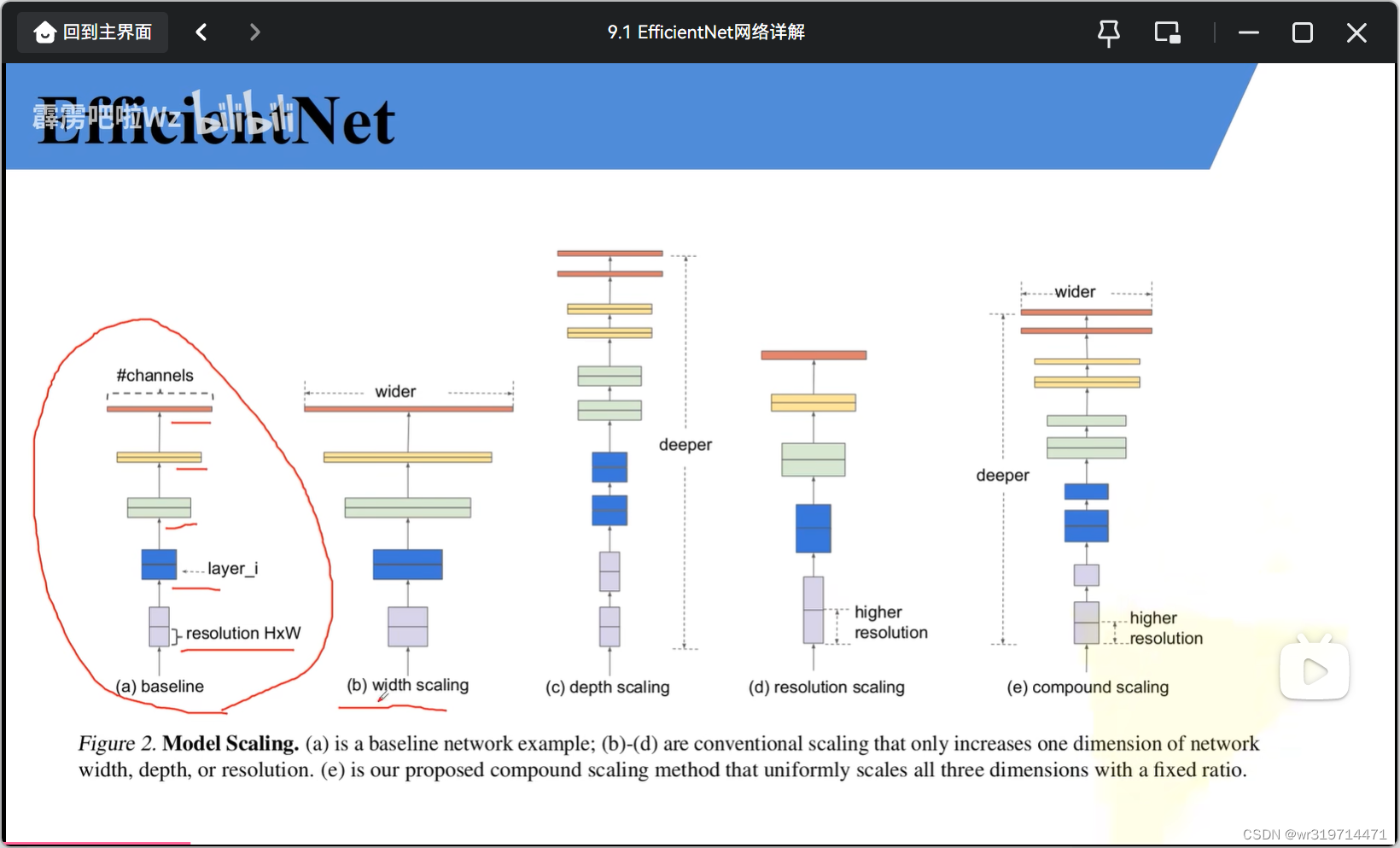
图a是传统的网络模型 (resolution是输入的图像,layer是层结构)
图b在图a的基础上增大了网络的宽度(特征矩阵的channel)(每个卷积层使用更多的卷积核)
图c增加网络的深度(layer个数更多)
图d增加网络的分辨率(每个特征矩阵的高和宽都会出增加)
图e全部增加
2.EfficientNet-B0网络结构(通过网络搜索技术得到)
分辨率是输入特征矩阵的分辨率,这里的步距是每个stage(可由分辨率信息得到)的第一层,其他均为1
channel对应每个stage输出特征矩阵
layer是将operator重复多少次
表中的卷积层后默认都跟有bn以及swish激活函数
3. MBconv (和mobilenet v3的block基本一样)
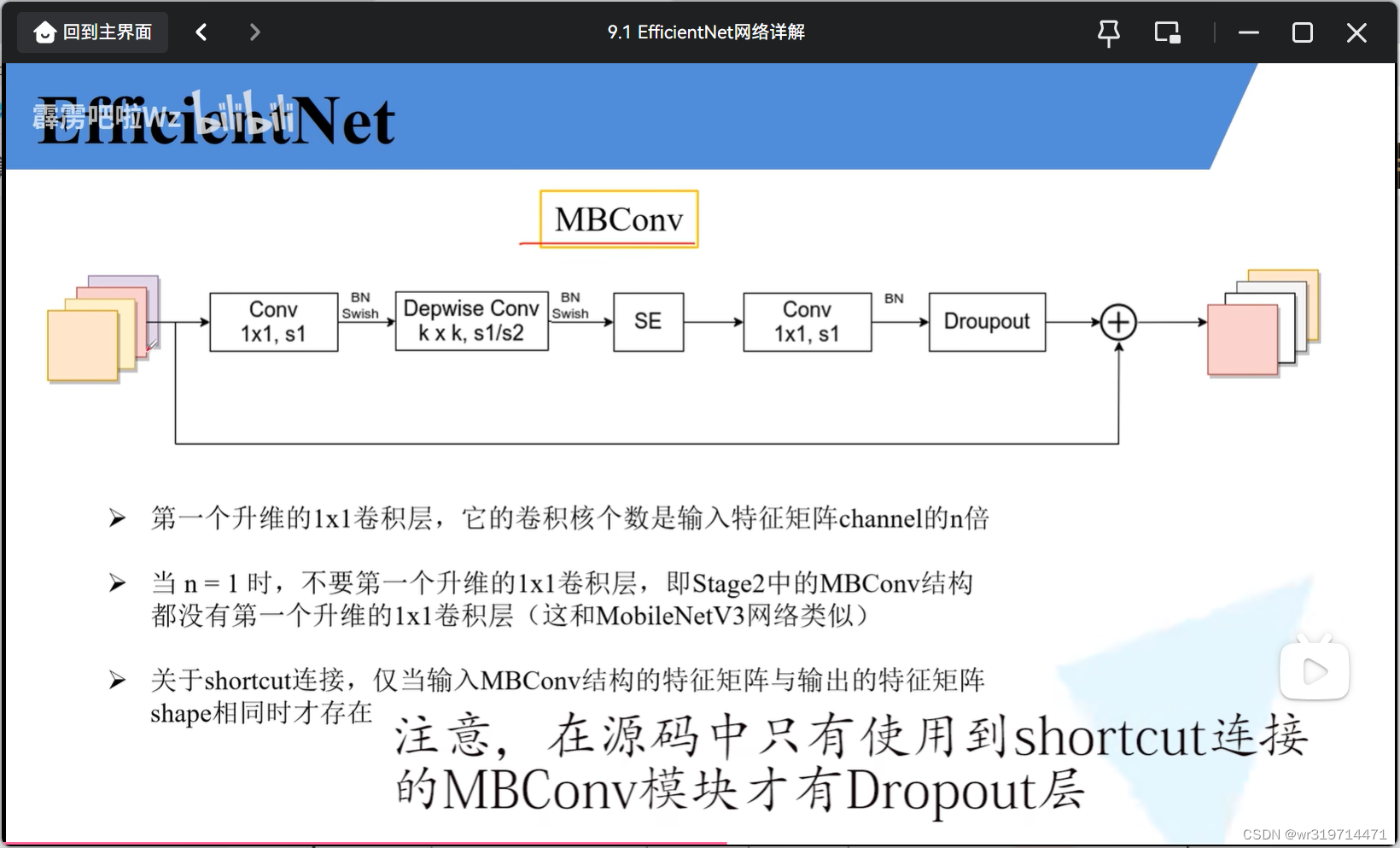
1*1卷积进行升维,dw卷积大小为k*k(3或5)(步距可能为1或2,就是上表给出的步距),se模块,1*1卷积进行降维
注意:在源码中只有使用到shortcut连接的MBconv才有dropout层
结构图中MBconv后面的数字就是n,倍率因子,MBconv中升维到原来的多少倍
降维卷积层的卷积核个数与上表给出的channel保持一致
se模块(注意力机制)
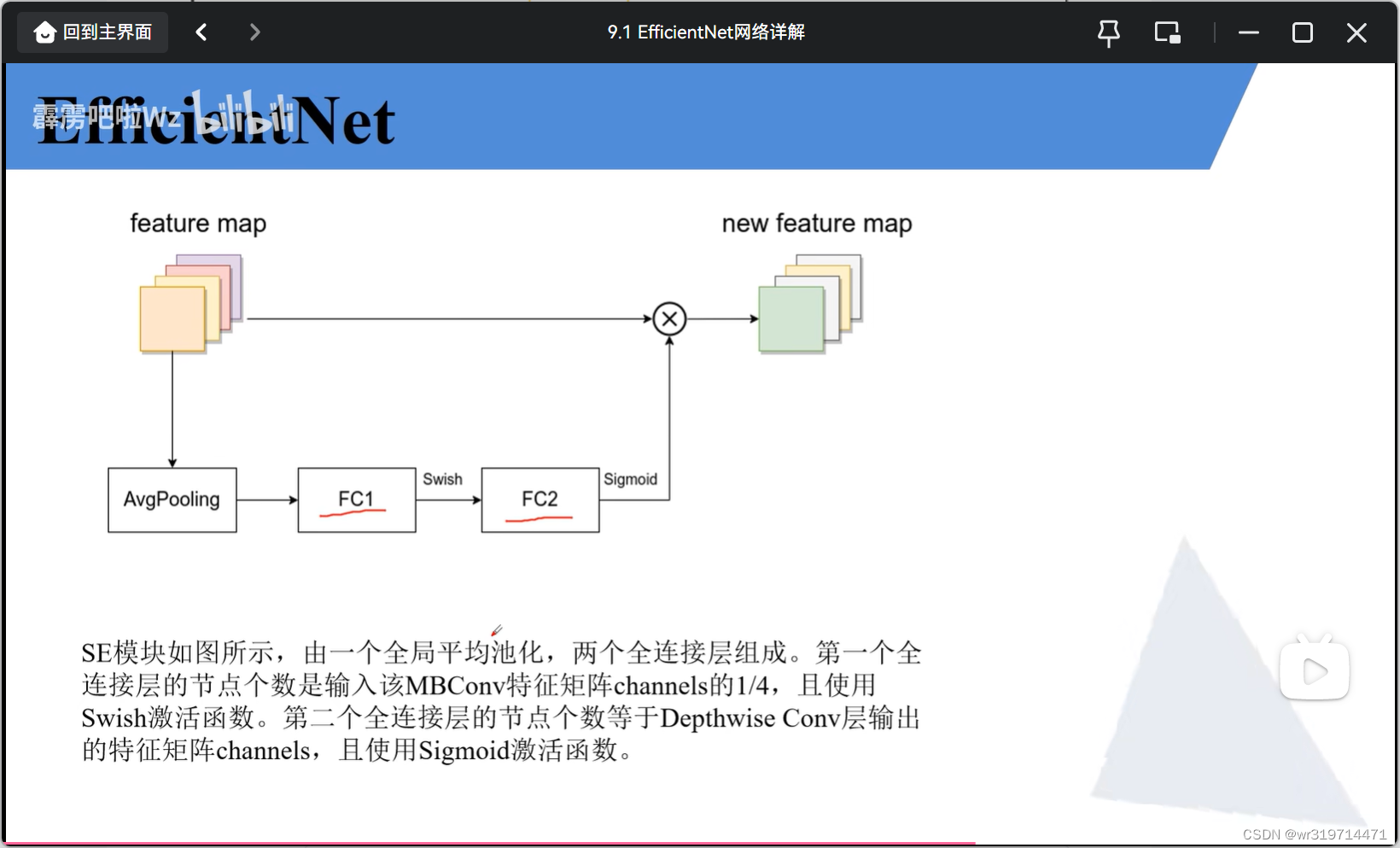
fc1的节点个数是输入MB模块的channel的四分之一
4.EfficientNet B0到B7(倍率因子针对B0)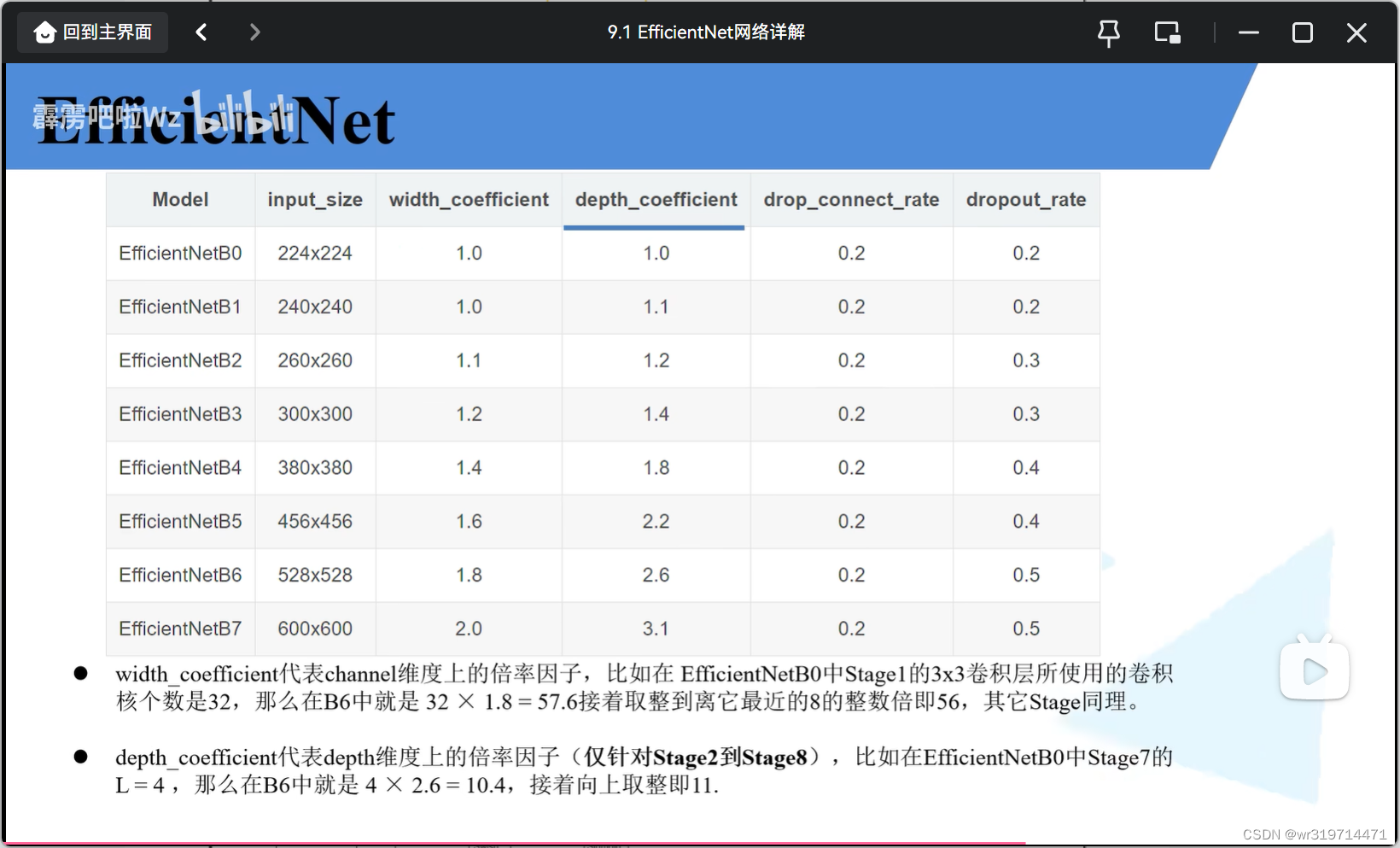
width_coefficient网络宽度(channel)倍率因子
depth_coefficient网络深度倍率因子(针对stage2到8)(layers*倍率因子)
drop_connect_rate是MBconv中dropout层的失活比例,并不是所有的dropout层的随机失活比例都是0.2,将所有的Mbconv中的dropout层的随机失活比例从0一直慢慢增长到0.2
drop_rate是最后一个全连接层之前的那个dropout层的随机失活比例
#这个网络非常占gpu的显存,像b4,b5,b6,b7这些模型,图像的分辨率非常大,每一个层结构的输入输出矩阵的高和宽都要增加,对于显存占用也要增加















 9355
9355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









