






首个端对端的针对像素级预测的全卷积网络 (这里的全卷积是指把分类网络中的全连接层替换成卷积层)

2.
FCN32s正向推理以及反向学习的过程 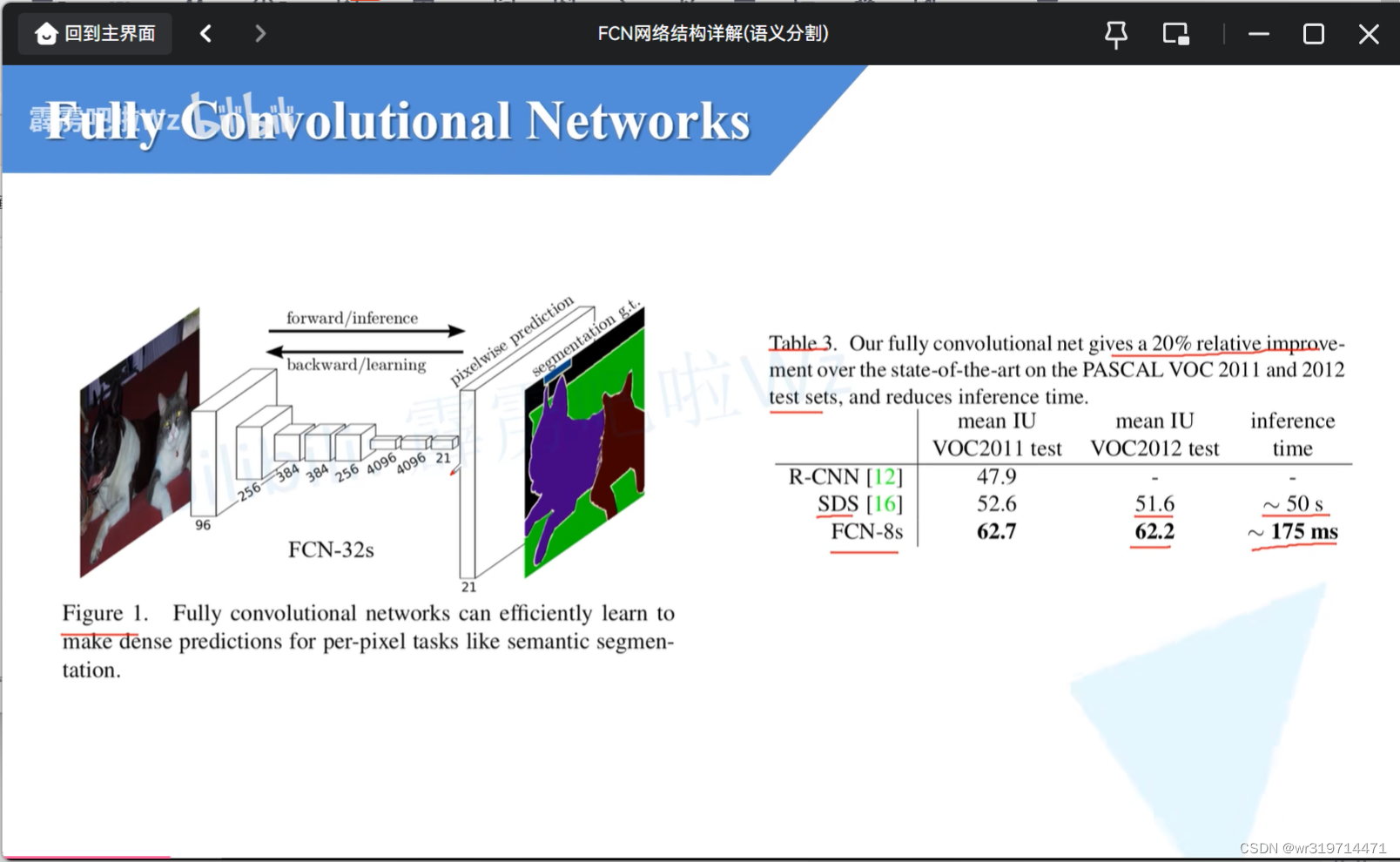
经过一系列卷积下采样得到特征层
(得到的特征层深度是21,因为当年使用的数据集主要是pascalvoc,其中有20个类别加上背景就是21)
接着经过上采样就得到和原图同样大小的特征图(但深度为21)
这里所得到的特征图,每一个pixel在channel范围上一共有21个值,对这值进行softmax处理,就可以得到该像素针对每一个类别的预测概率,那么就可以取概率最大的类别作为该像素的预测类别
3.
convolutionalization(卷积化)过程
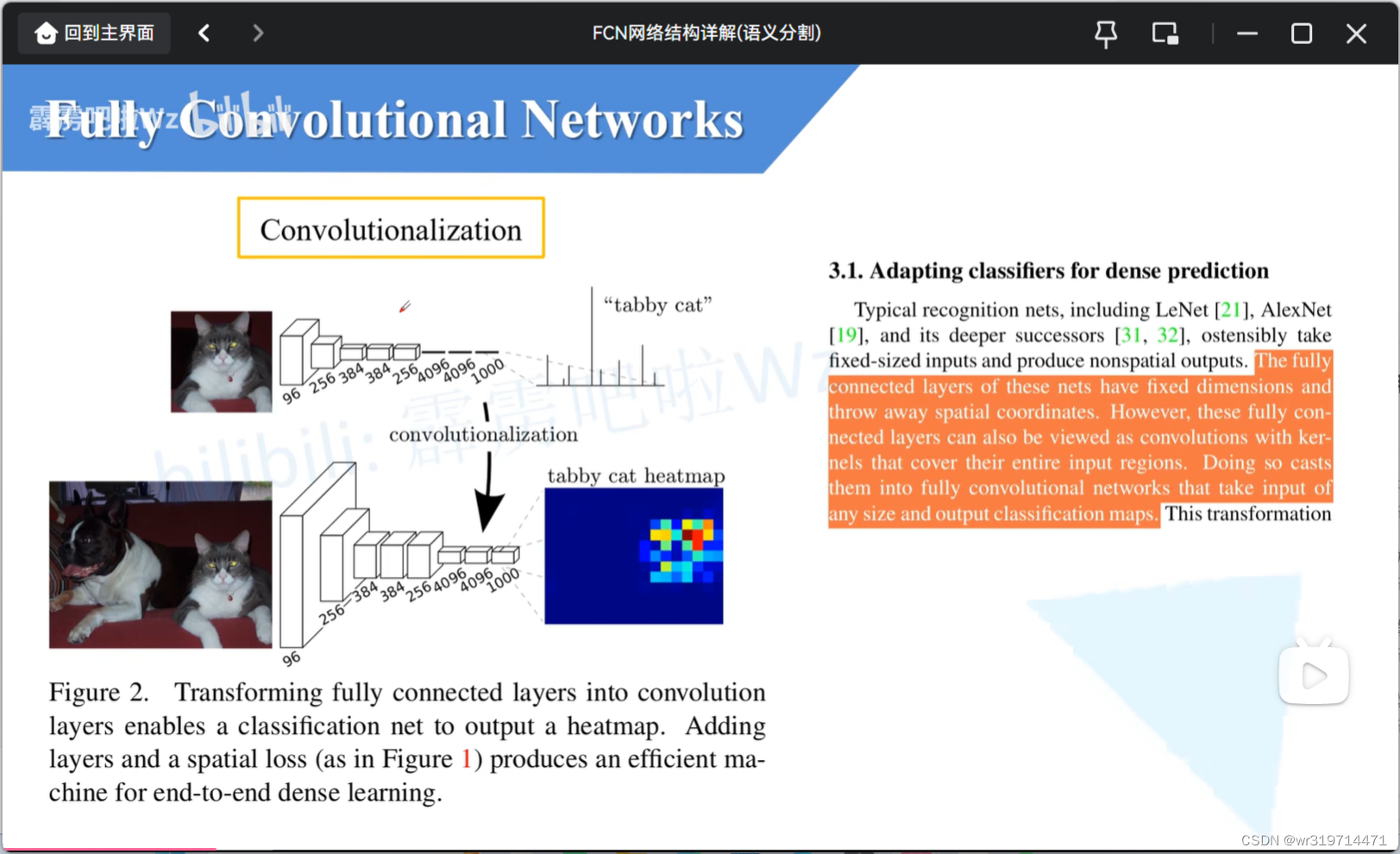
第一个网络图中,4096 4096 1000就是全连接层
比如输入一张图片经过此分类网络就会得到一个针对一千个类别的预测值,在经过softmax处理就可以得到每一个类别的概率
对于全连接层,我们要求的输入节点的个数是固定的,如果在训练过程中,他的输入节点个数发生变化,就回报错
所以在平时训练分类网络时,输入网络图片的大小是固定的(后面很多网络会使用全局池化层)
###如果把这里的全连接层全部改为全连接层,对网络输入的大小就没有什么限制了
所以作者就想办法把全连接层的权重转化到卷积层中
此时对输入图片的大小就没有那么严格的限制了,而此时输出也会发生一定的变化
(第一个网络得到的是长度为1000的向量,第二个网络若输入图像大于224*224,那么得到的特征层的高度和宽度是大于1的,那么他对应与每个channel的数据就是2d的了,也就刻意将他可视化为一张图片的形式)
这里我们可以将对应于tabbycat类别所对应的channel的数据给提取出来,将他可视化为heatamap形式,那么就可以得到一张heatmap图
************************************************************************************************************** 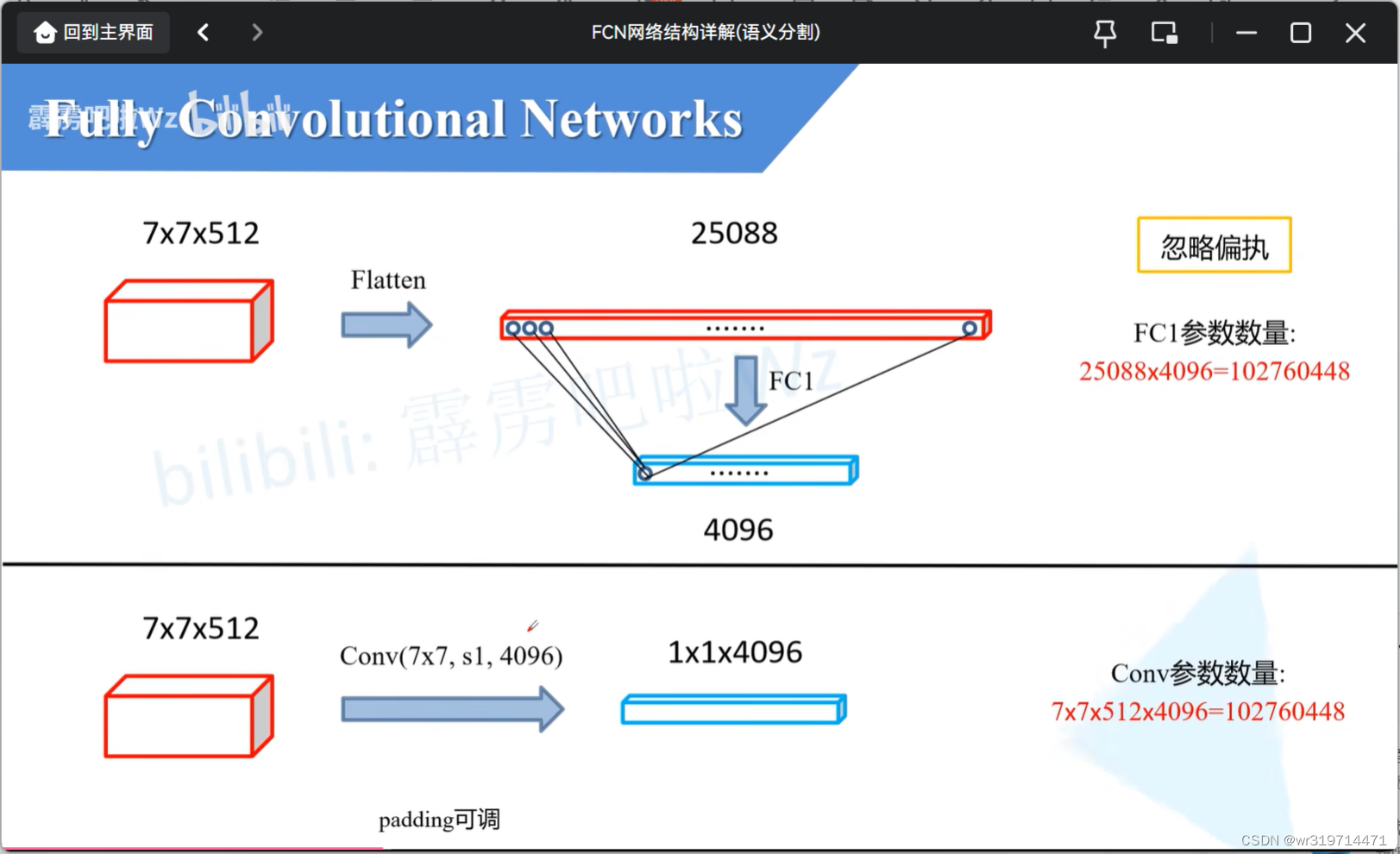
上:
在分类网络中首先会进行展平处理,变成长度为25088个节点的向量 ,通过全连接层1后会得到向量长度为4096的向量,对于全连接层1,输出的每个节点要与输入的每个节点进行全连接,一个节点的参数是7*7*512
下:根据需求去调整padding
采用大小为7*7,步距为1,4096个卷积核的卷积层
一个卷积核所对应的 参数也是7*7*512
由于卷积过程中也是卷积核与输入特征矩阵相应位置上相乘再相加,和全连接过程是一样的
一个卷积核与一个节点的参数是一样的,计算方式也是一样的
因此我们可以将全连接层中的每一个节点所对应的所有权重进行一个reshape处理,那么就可以直接给我们的卷积层使用了
图中的两个蓝条的数值是一摸一样的,只不过第一个没有高度宽度信息,第二个有
4.
回顾vgg16
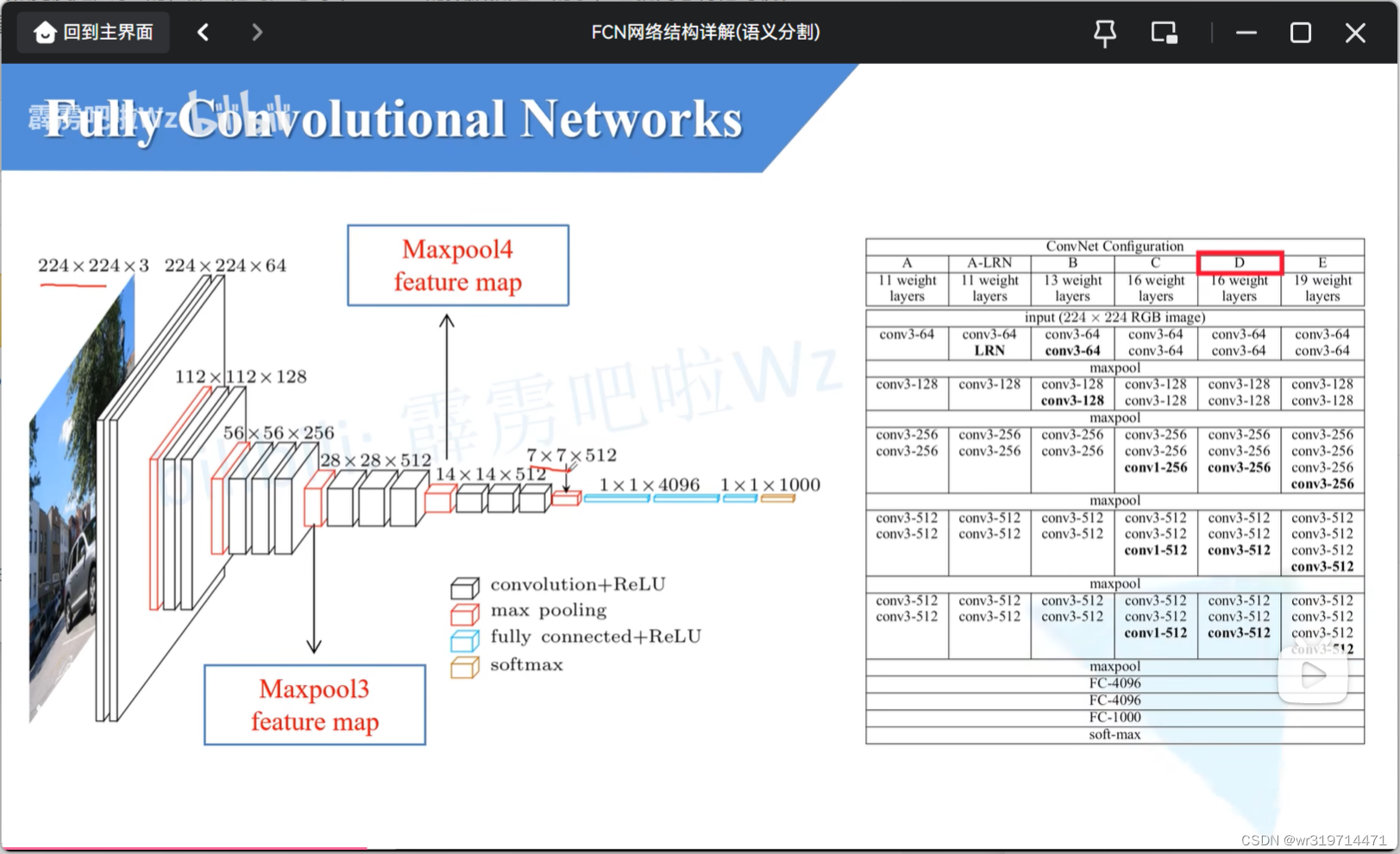
从224*224到7*7下采样了32倍
5.
结构

这幅图简要给出了fcn网络的结构,但这里忽略了所有的卷积层
数字的含义
fcn-32s:将预测结果上采样了32倍还原回了原图大小(上采样倍率为32的模型)
其他也是如此
**详细结构

源码中在backbone(特征提取部分)的第一个卷积层处,将padding设置为100,为了让fcn网络适应不同大小的图片
如果不进行100padding如果输入图片的大小小于192*192,经过vgg的backbone后高和宽就小于7了,此时经过fc6时会报错
如果输入图片高和宽都小于32,对于分类网络我们通常会将图像高和宽都下采样32倍,那还没通过backbone就报错了
而现在没有必要padding100了,我们现在很少有小于32*32的情况
在fc6中padding3就可以处理大部分了
对vgg中的前两个全连接层进行了convolutionalization处理变成了图中fc6,7
我们通过分类网络会将图片的高和宽下采样32倍,所以通过backbone后,高和宽变为32分之一,深度为512(对于vgg16)
经过fc6,7后特征矩阵的高和宽是不会变化的
之后卷积核个数为分类类别的个数num_cls(包含背景)比如Pascalvoc的num_cls是21
接下来经过一个转置卷积,步距为32,也就是上采样32倍 ,恢复为原图的大小
h*w*num_cls也就是对于每个pixel(像素)有num_cls个参数,经过softmax处理就可以得到他的预测类别了
双线性差值bilinear interpolation:
在原论文中源代码中时使用双线性插值的参数初始化转置卷积的参数
源码中 这里的的转置卷积的学习参数被冻结住了(动不动差别不大),意味着他就是一个简单的双线性插值,完全可以不适用转置卷积,直接使用双线性插值的方法,还原回原图大小
fcn-16s
前四个模块是没有变化的
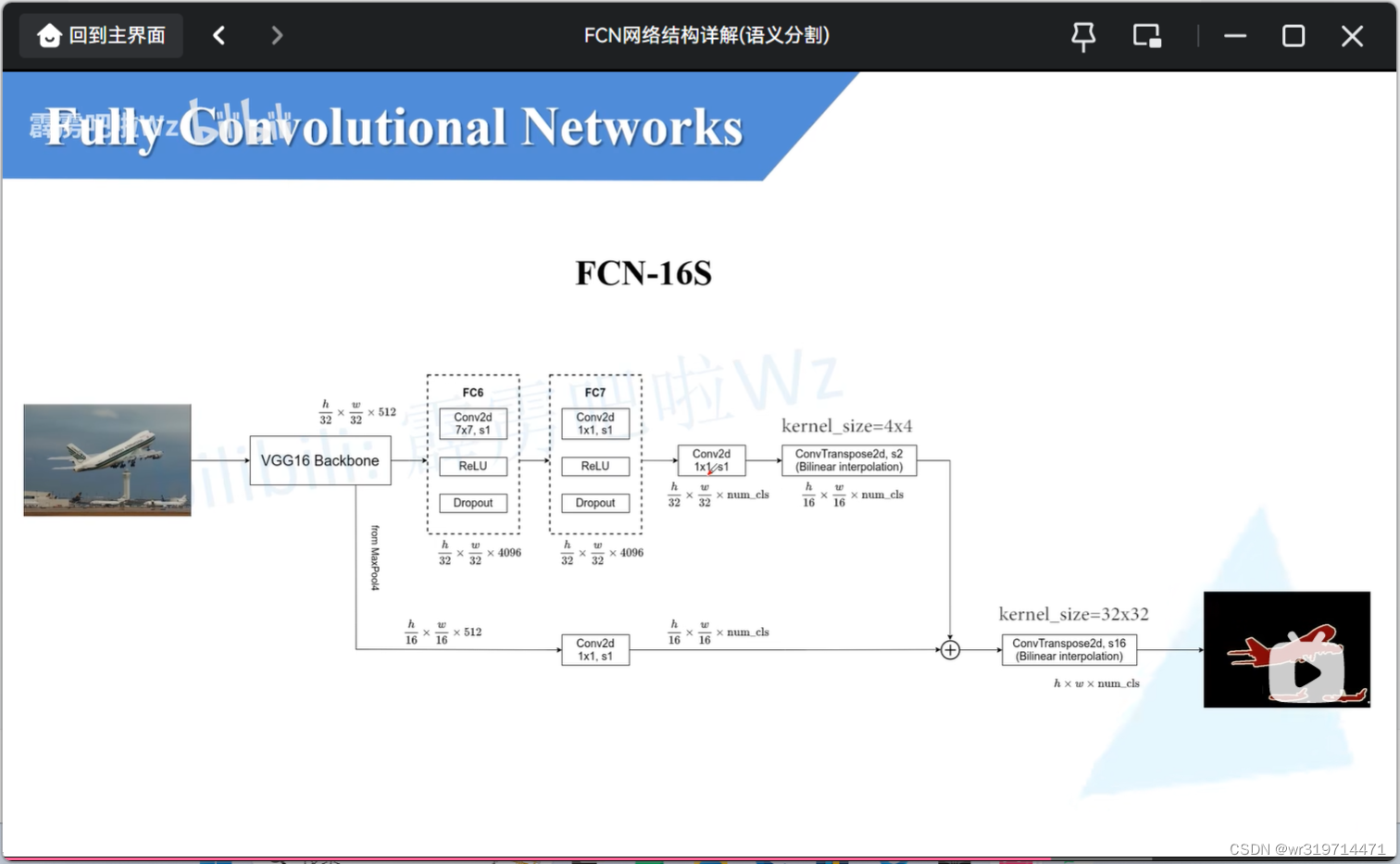
这里会使用到maxpool4所输出的特征图(高宽为原图的16分之一)
转置卷积的上采样率为2倍
相加操作之后进行转置卷积上采样16倍,就能得到原图大小了
fcn-8s
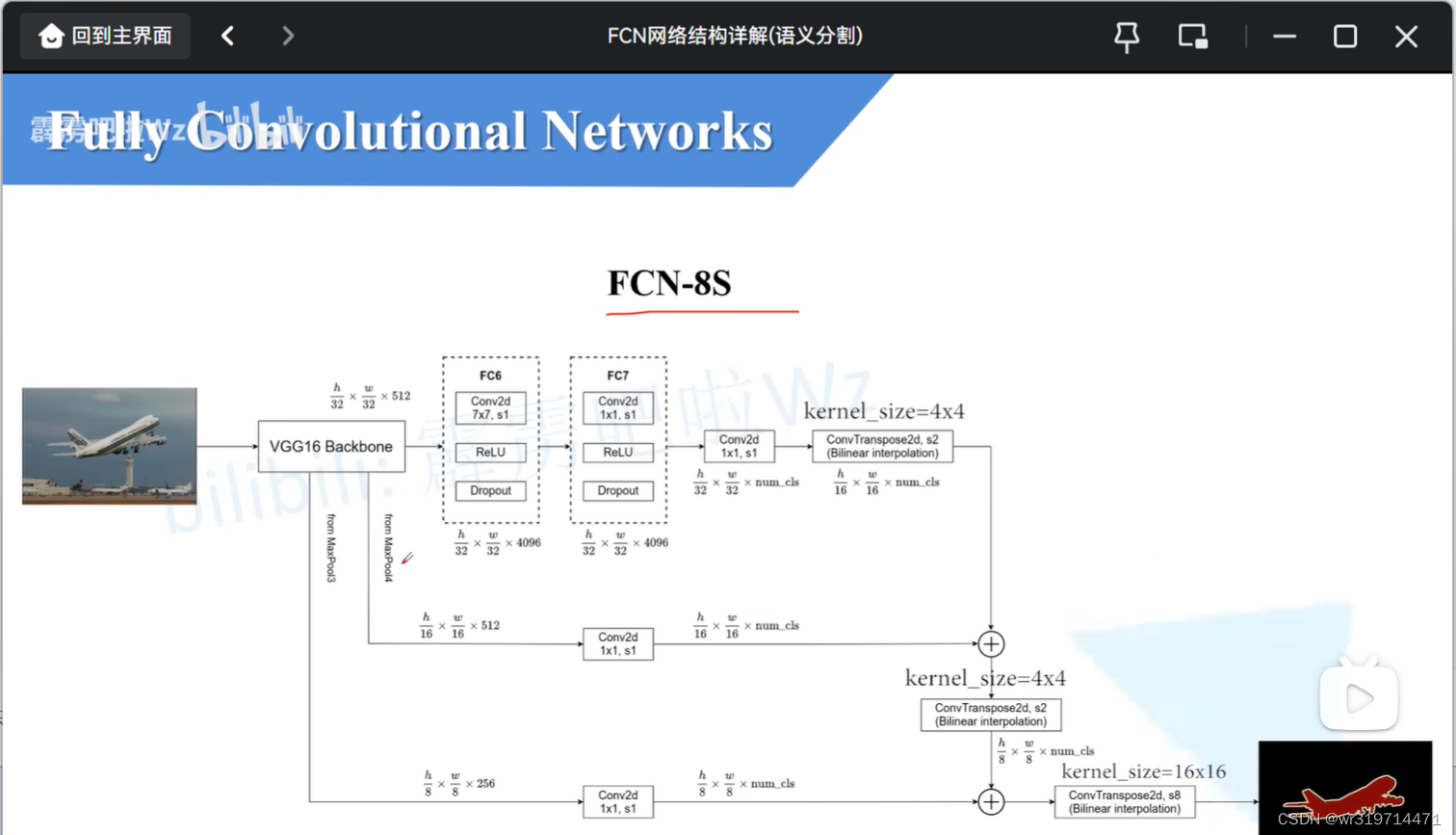
这里的相加都是特征层在相同位置的元素进行相加
6.
损失计算
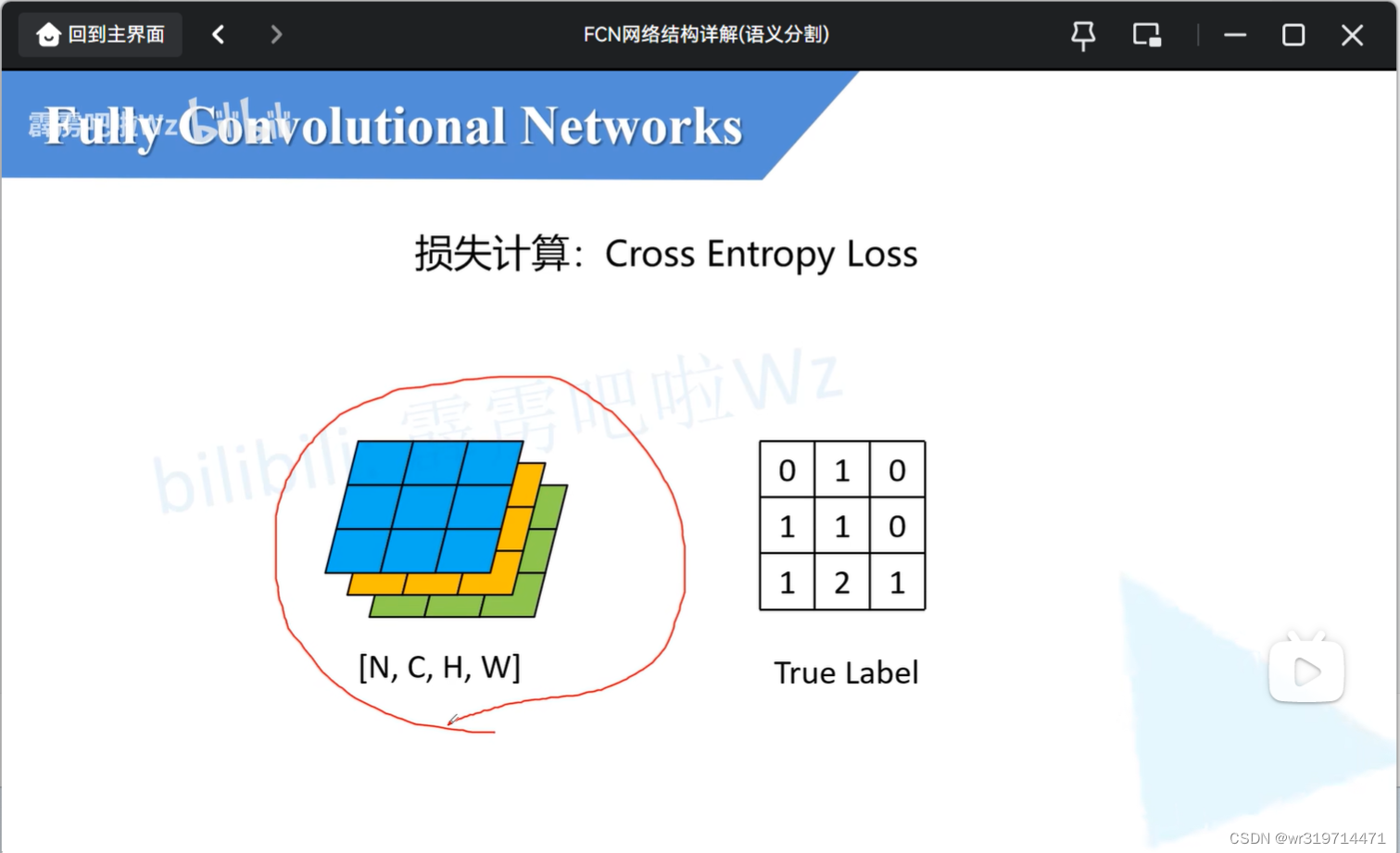
左侧为预测还原为原图大小的特征图(这里高宽的cls都为3),也就是每个pixel在深度上有三个参数(对pixel在深度方向上进行softmax处理,就可以得到每一个类别的概率)
对于每一个pixel的预测值,我们可以对应他的truelabel计算出交叉熵损失,将所有损失进行一个求平均的操作,得到最终的损失















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









