









标题:FML: Face Model Learning from Videos
链接:https://arxiv.org/pdf/1812.07603
这篇论文解决的问题是如何直接从视频中学习3D人脸的表示。
本文自述最大的创新点就是提出了一个multi-frame consistency loss,主要就是基于同一个视频中,人脸的基本属性(反光率和形状)不会变化而设定的一个loss。另外,文中没有使用任何已有的先验模型(如3DMM),可以完全从零开始训练出一个可用的模型,作者使用了deformation graphs(?)来完成这一点。
作者使用了两套参数来表示一个3D人脸,首先是在帧间统一的,称之为shared identity parameters。其中包含了shape parameter(形状,alpha)和facial appearance parameter(纹理,beta)。
另外一套是帧间独立的,也即blendshape parameters(表情参数,theta),相机参数(R,t)和光照参数(gamma)。
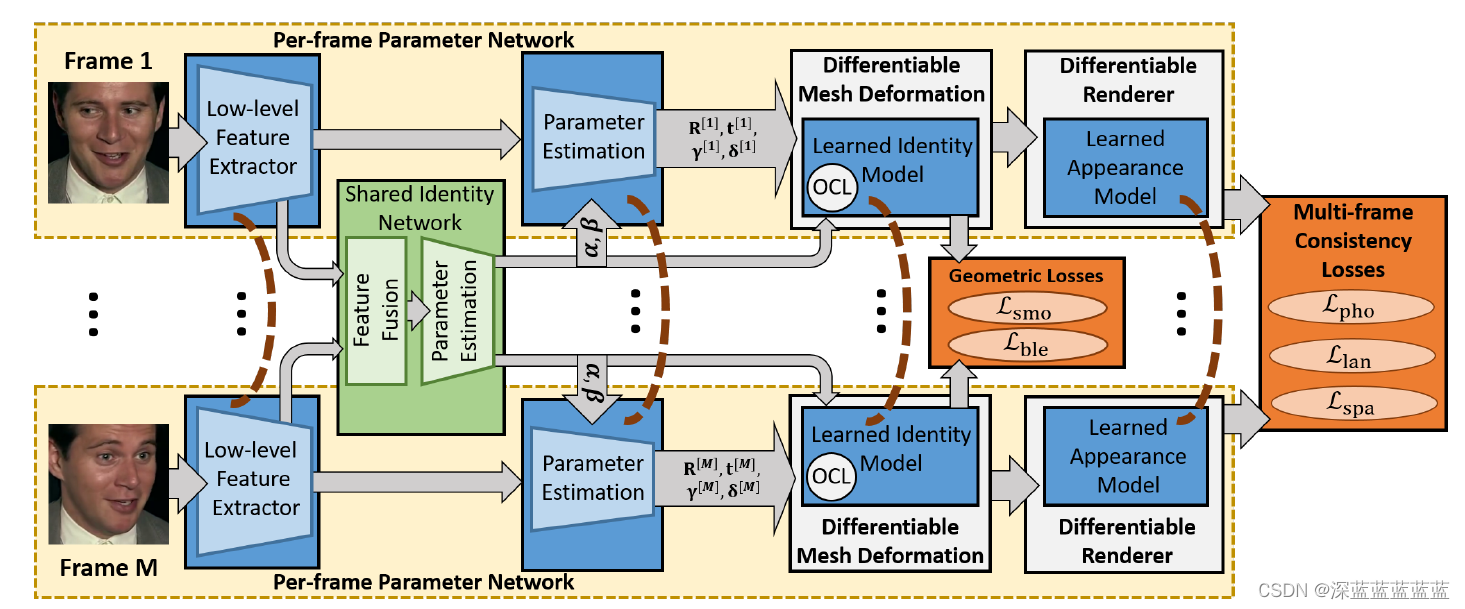
结构如图所示,视频的所有帧都会输入同一个网络。首先,对于每一帧,模型会先学习一套帧间独立参数,然后针对所有帧又会联合学习一套帧间统一的参数,之后使用一个可微分渲染器渲染出3D表示的2D映射,从而计算原始输入和渲染结果的差距。
文中提出了五个loss:
Multi-frame Photometric Consistency:身份一致性loss,也就是整个模型最重要的loss,保证了在视频中面部形状和纹理的统一。计算方法就是在帧间统一参数不变的情况下降低所有帧重构结果与原始帧的误差。
Multi-frame Landmark Consistency:特征点loss,和身份一致性loss很相似,只不过这个是先提取了landmark之后计算的。2D图片用现有的SOTA提取就好,3D的landmark是用了sliding correspondences(?)来完成的。
剩下的三个loss都属于对于参数分布的一些约束:
Geometry Smoothness on Graph-level:保证node之间的平滑
Appearance Sparsity:保证顶点间色度的平滑
Expression Regularization:保证表情参数不要太大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









