







目前 3D 学习中,物体或场景的表示包括显式表示与隐式表示两种,主流的显式表示包括基于 voxel、基于 point cloud、和基于 polygon mesh 三种,隐式表示包括基于 Occupancy Function [1]、和基于 Signed Distance Functions [2] 两种。下表简要总结了各种表示方法的原理及其相应优缺点。

1.1 Voxel
表示图像:

表示原理:体素用规则的立方体表示 3D 物体,体素是数据在三维空间中的最小分割单位,类似于 2D 图像中的像素。
优缺点:
+ 规则表示,容易送入网络学习
+ 可以处理任意拓扑结构
- 随着分辨率增加,内存呈立方级增长
- 物体表示不够精细
- 纹理不友好
1.2 Point Cloud
表示图像:

表示原理:点云将多面体表示为三维空间中点的集合,一般用激光雷达或深度相机扫描后得到点云数据。
优缺点:
+ 容易获取
+ 可以处理任意拓扑结构
- 缺少点与点之间连接关系
- 物体表示不够精细
- 纹理不友好
1.3 Polygon Mesh
表示图像:

表示原理:多边形网格将多面体表示为顶点与面片的集合,包含了物体表面的拓扑信息。
优缺点:
+ 高质量描述 3D 几何结构
+ 内存占有较少
+ 纹理友好
- 不同物体类别需要不同的 mesh 模版
- 网络较难学习
1.4 Occupancy Function
表示图像:
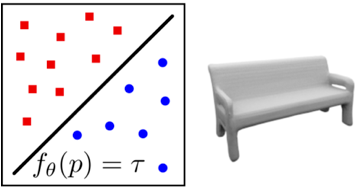
表示原理:occupancy function 将物体表示为一个占有函数,即空间中每个点是否在表面上。
优缺点:
+ 可以精细建模细节,理论上分辨率无穷
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构
1.5 Signed Distance Function
表示图像:
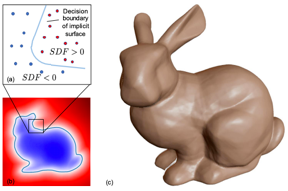
表示原理:SDF 将物体表示为符号距离函数,即空间中每个点距离表面的距离。
优缺点:
+ 可以精细建模细节,理论上分辨率无穷
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构
Reference:
[1] Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR, 2019.
[2] DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In CVPR, 2019.

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









