









标题:3D Gaussian Splatting for Real-Time Radiance Field Rendering
链接:https://arxiv.org/pdf/2308.04079.pdf
本文提出了一种基于3D高斯体进行场景重建的方案,并提供了高效的渲染器实现。其重建精度,训练速度和推理速度均超越之前的SOTA方案。整体的思路就是先使用传统方案(COLMAP)将多视角图像对齐,并提取稀疏点云。然后以这些点为基础构建高斯体,在训练中动态的增减高斯体的数量和半径。之后对高斯体进行渲染,获得最终的重建结果。
模型结构
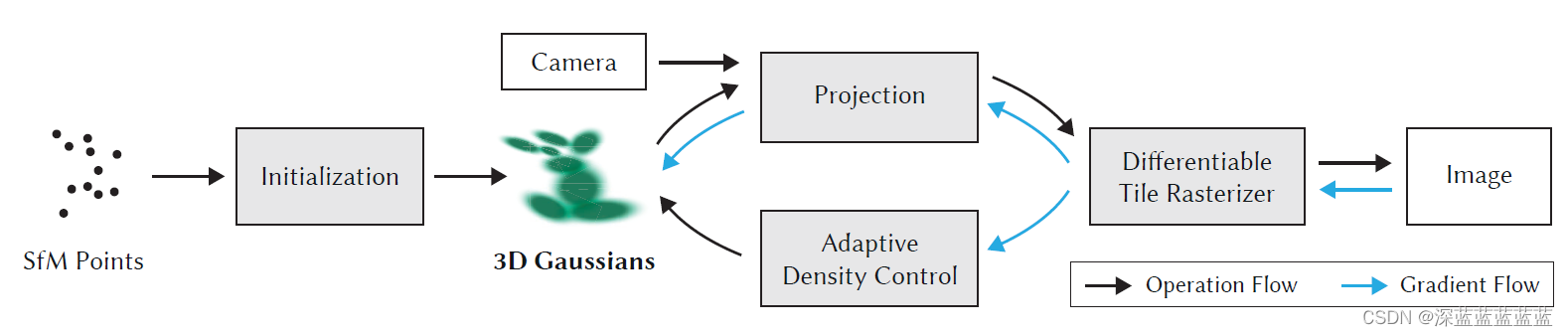
预处理
最左边的SfM Points就是用COLMAP从多视角图像中获得的初始点云。
初始化
初始点云的点的位置x就是高斯体的中心点,然后每个高斯体分配一个协方差矩阵
,和
值。其中
控制高斯体的移动,
控制高斯体在各个方向上的长短,
控制高斯体在渲染时的不透明度。
这里多一嘴,下文中有说,初始的是设置为每个方向上方差一样,且其值等于与最近三个点的平均距离。即一个球形。
投影
这里讲的就是如何将3D高斯体投影到2D平面上去,因为最终成像肯定是2D的图片嘛。那这里就涉及到了相机的投影矩阵,和高斯体在当前方向上投影时发生的的仿射变换
。通过公式
获得高斯体在2D平面上的投影的协方差矩阵
。
但是这里有一个问题,就是协方差矩阵必须是半正定的,否则没有意义(比如方差如果是负数,那是没有意义的),但我们在模型训练时,无法保证其一直都是半正定的。因此作者将协方差矩阵分解为一个旋转矩阵和一个缩放矩阵
来表示(想象成空间中的一个椭圆),即
。这样,通过约束
和
就可以很轻易的保证
是半正定得了。然后,作者进一步将旋转矩阵
转换成四元数
以便于后续梯度下降的优化。
优化
之前已经讲了,对于一个高斯体,我们要优化的参数有(位置),
(不透明度)和
(旋转+缩放)。除此以外,作者还增加了一组新的优化参数,用于控制颜色的,即球谐函数系数(SH coefficient),简单来说就是用一个球面来模拟光照情况。这个比单纯的朗伯反射要好很多。
从结构图中也可以看出,模型结构很简单,因此文中只使用了基于rgb的损失,包括一个L1项和一个D-SSIM项。
高斯体的动态优化:本文的一大亮点就是如何在训练过程中动态优化这些高斯体,也即什么时候需要增加新的高斯体,增加什么样的高斯体,又或者什么时候删除高斯体。
何时删除高斯体?:这个其实比较简单,就是当一个高斯体的即不透明度过于低时,就删除,因为透明的高斯体根本不会有任何贡献。这里会人工设定一个阈值
。
何时增加高斯体?:直观上来讲,我们肯定是希望在高斯体密度比较稀疏的地方增加新的高斯体,这样能帮助场景拟合更多细节。因此就分为两种情况:1.局部的高斯体过小且少,有很多地方cover不到。2.局部的高斯体过大,很多地方都被同一个高斯体cover了。并且作者发现,在这两种情况下,坐标接收到的回传导数都很大,作者认为这是因为高斯体也想要努力去重建这一部分的细节。因此作者就将所有回传梯度平均值大于的高斯体设为需要增加高斯体的备选。
增加什么样的高斯体?:按照上文说的,情况分为两种:高斯体太小且少和高斯体太大。对于太小且小的情况,作者选择复制当前的高斯体,并将其放置到梯度方向上去。对于太大的高斯体,作者则删除原有高斯体,并根据原有高斯体的分布重新采样出新的小高斯体,比原来的要小1.6倍(实验出来的结果)。
特殊情况?:当某些高斯体过于接近相机时,在视图中就会变大,此时会错误的被分裂成新的高斯体。作者的方案就是每隔一定时间就将所有高斯体的都变得特别小,这样的话,那些没用的高斯体的
增长的就会很慢,也就会低于阈值
,从而被删掉了。
渲染
在进行点云类数据的重建时,一个比较大的问题就是怎么渲染。通常来说,点云的渲染是在渲染时对每个像素确定一个采样半径,对半径内的点做加权平均来获得当前像素的颜色。而本文中除了点以外,还有一个高斯体的分布,每个点的影响范围都是不一样的。因此,对于这种情况必然需要一套新的渲染方案。并且我们当然希望这个方案的是高效以及可微的。
首先,作者将一个图像分裂成16*16个小块,每个小块独立进行渲染。首先先获取所有与当前小块相交度超过99%的高斯体(置信度区间),然后对这些高斯体按照其中心与相机的距离(深度)进行排序。后续在做渲染时,就直接使用这个排序的结果进行渲染,而不再基于每个像素单独排序。(需要说明的是,基于这个排序结果进行渲染的话,那结果并不是绝对准确的,其精确度必然比不过体渲染,但是这样主要的好处是速度快,而且当后期每个高斯体大小都近似于一个像素的大小时,其结果和体渲染的结果也就差不多了。)
在渲染时,当累积值足够大时,就不再继续往后渲染了,因此每次渲染并不是都要遍历所有的高斯体,从而进一步增加了效率。
此外,在计算方向传播的梯度时,也可以利用这里的排序结果,并且在每个像素上只计算那些对当前像素的值有贡献的高斯体计算梯度。
结语
至此,本文的方法部分就讲完了,剩余的实验结果看原论文即可。最近正在研究这一块,有感兴趣的同学欢迎留言和我交流,或者加微信讨论:wrk226。















 2810
2810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









