






概要
在学习hadoop的过程中对一些概念需要了解,例如hdfs分布式文件系统的运作流程,namenode和secondarynamenode的工作原理等概念了解之后有助于理解hadoop的各部分机制。
Hadoop读写流程
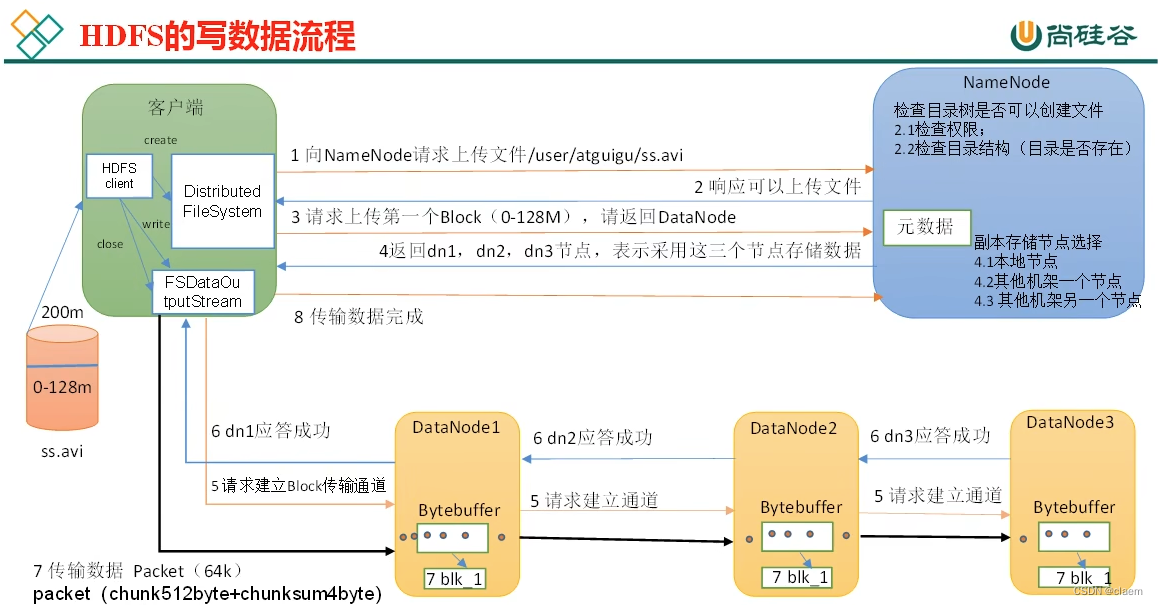
上图就是hdfs写入数据的过程,无论是使用linux环境下hadoop集群进行处理文件的命令操作还是在本地idea里调用api连接集群/本地模式处理数据都是基于客户端和namenode进行交互。
需要注意的一点是 无论是读取数据还是写入数据 hdfs都是串行的 并不是并行,在这里即为:fs的输出流连接到就近的一个datanode尝试建立传输通道,如果成功建立则该输出流不会同时和分配的所有datanode进行传输,而是只和该就近的datanode进行传输,然后该就近的datanode在将数据同步传输到其他分配的datanode。
在写入数据时,对于分配datanode考虑的距离计算以及对于存储副本节点的选择:以下图解释了如何选择


接下来是hdfs读取数据的流程 和写入类似 读取数据也是由客户端发起请求 namenode授权后返回数据存储的信息,然后客户端的输入流尝试与datanode建立传输,这里读取数据是分块读取的,因为数据在存储时分块存在了不通datanode上,这里也是串行读取,然后拼接成完整的数据。

NameNode和SecondaryNameNode工作机制

对于nn和2nn的工作机制见上图,需要注意的是fsimage镜像文件里存储的是namenode里的文件目录等信息,而edits操作日志记录的是对目标文件进行增删改查的操作记录,仅记录不执行,只有当namenode启动的时候将edits操作日志和fsimage镜像文件共同加载到内存,保证内存里生成最新的文件目录信息(经edits操作后的文件信息)
另一个需要注意的点即是2nn拷贝nn信息的checkpoint设定:check周期&edits存储命令数量check周期为1小时 edits命令数量为1百万条,达到条件触发拷贝。

datanode工作机制顺带提一嘴,这个没啥特殊的。
MapReduce工作机制
首先要了解mapreduce是干啥的,他这个层在hdfs里起到什么作用:我个人理解为它是干活的,类似javaweb里的service层,就是创建好后在里面自定义方法,就像第一个例子wrodcount统计词频,使用的命令就是hadoop jar xxxx.jar 里面的wrodcount方法,同时自定义的mapreduce计算方法可以在本地idea创建好后打包传到hadoop服务器上以jar包形式运行。
再就是mapreduce的优缺点了解一下即可。

上图是wordcount这个mapreduce计算方法具体的执行流程,从获取数据开始,有一个切片的动作,橙色数据被分成两部分128M和72M,灰色数据就是100M所以不需要切片了再。
(这里补充一下切片的概念,是逻辑上的划分数据 并不是物理意义上将存储在磁盘里的数据切分,相当于maptask的分工而已,切片越多 启动的maptask数量就越多 因为mapreduce是一个分布式的计算方法处理数据)
要注意的是,处理的数据如果是txt 或者 csv xlsx等文本表格类文件 通常都是按行处理数据,mapreduce里需要我们自己动手的就是mapper 和 reducer两个执行处理类 mapper类里重写map方法 按行处理数据 并在每行对数据进行一些操作 例如遍历 split切分 等,最后处理好的数据以键值对类型写入context对象
紧接着context对象将mapper处理好的数据传给reducer 由reducer进行进一步操作。有个小注意的是 hadoop里的数据类型和java有区别 除了string 叫成text 其余均在后面加上writable即可。
MapReduce的序列化概念,当我们需要处理多维度数据时,单一的mapper 和 reducer就显得能力有限 因为一对map+reduce方法能操作的数据是有限的。这里就需要一个中间层概念 将多维度数据套一个bean对象 变成一个对象数据 这样就更方便map+reduce处理。















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









