







上一篇记录到MapReduce工作流程,只是粗略的讲了框架,具体到内部每个环节还有很多细节,同时每个环节在代码上是哪一步/如何实现都需要记得。
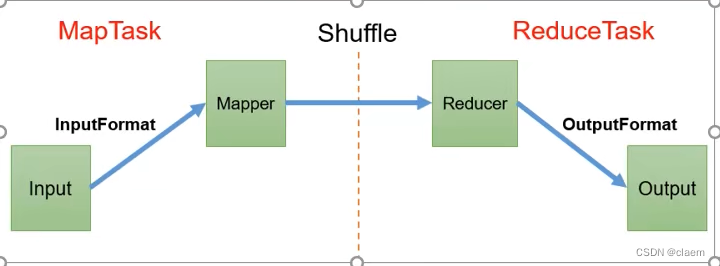
这个是最大的一个框架,从数据输入到mapper处理 再通过shuffle机制 最后到reducer处理聚合 最终数据输出 四大过程。下面开始解释每一步的具体流程:
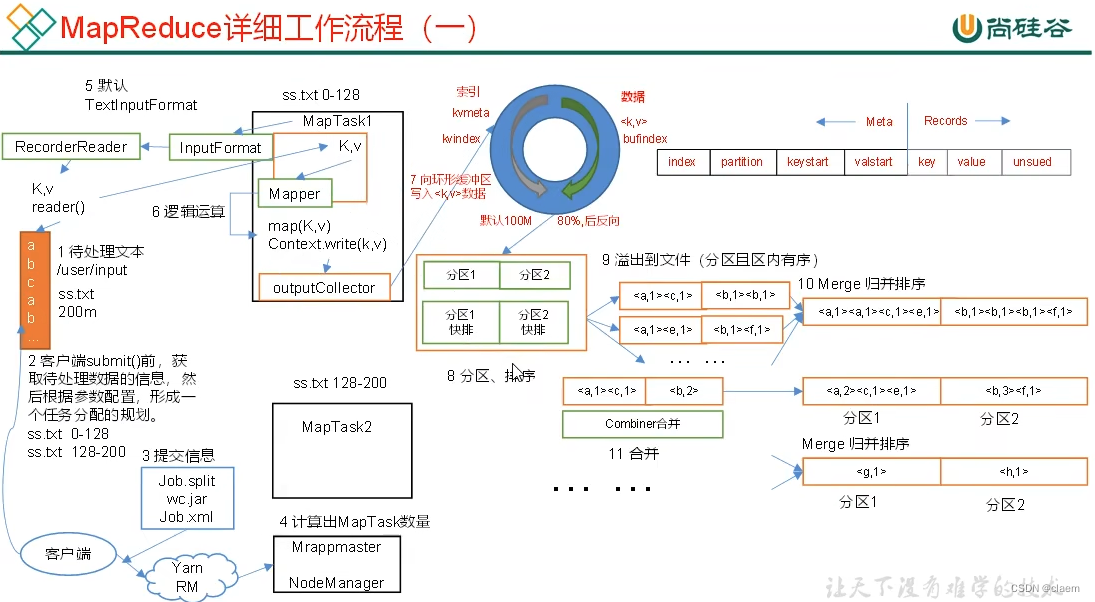
首先是到Mapper之前的数据输入input+inputformat这个过程:可以看见当客户端提交了本次任务的原始数据(数据文件可以是1个或者多个)例如这里就是ss.txt 200MB大小的原始数据,提交数据之后hdfs里yarn进程会使用resourcemanager调度资源给Mrappmaster和NodeManager,它俩得到资源执行任务,而我们都知道 mapper 里具体执行任务的方法是map 并且mapper是并行的,具体的并行度由mapTask数量决定,mapTask就是干活的,可以理解为在每个mapTask里执行map方法和其他的一些 例如setup方法,mapTask的数量又由切片数量决定 n个切片对应n个mapTask,那么切片数量又什么决定呢?即由inputformat格式决定,默认default的inputformat是按行读取的TextInputFormat格式 它的特点是每个文件不论大小都使用某个切片阈值来切片 例如有两个文件f1/f2 ,f1 200MB f2 10MB,默认的切片阈值是128MB (也可以设定成100MB),那么对于f1 就会被切片成两份 1份是0~128 另一份是128~200,而对于f2 由于根本没达到切片阈值 那么Textinputformat就不会对其切片 但仍会为它分配一台mapTask,这就很浪费性能,因为f2只有10MB 非常小,所以遇到传入很多个小文件的时候,默认的Textinputformat就不适用,会造成mapTask资源的浪费,就可以使用CombineTextInputFormat替换默认的format,CombineTextinputformat需要手动指定切片阈值,然后合并传入的文件,一旦达到切片阈值大小即切片一次,如果没达到则不切片,整体作为一个文件并且为其分配一个mapTask。
当数据切片好也分配好mapTask之后,就进入到mapper操作数据的阶段:对于每个mapTask,在里面进行逻辑运算的部分是map方法,该方法会按行读取数据然后操作读取的行数据,由于每个mapTask处理的切片数据大小不一,可以完成逻辑运算的时间也会不一致。当mapTask完成逻辑运算时会将结果数据传入环形缓冲区,该缓冲区会开始分两侧记录不同的数据,左边一侧记录元数据,即mapTask传入数据存储的索引,分区信息等数据,右边一侧记录传入的数据,这里要注意的是当缓冲区整体记录的数据(左边+右边)占比达到缓冲区大小的80%时(缓冲区大小默认为100MB)就会开启一个异步的溢写进程,将mapper传入的数据逆向(右边一侧的数据从下往上)写入到磁盘,为什么是80%而不是存满缓冲区再溢写呢?因为缓冲区比较小,存满数据的时候会反向存入mapper传入的新数据,就会覆盖之前存入的数据信息,如果刚好存满缓冲区才开启异步溢写那么就得等溢写完之前存入的数据才能反向存入新数据覆盖,这样就很浪费时间,如果存满80%缓冲区就开启溢写相当于节省了一部分等待时间(有可能接下来存入数据从80%->100%这段时间溢写刚好结束,如果没结束等待的时间也比存满100%再开始溢写要短)。每个mapTask输出的数据都会经过缓冲区再溢写到磁盘,由于缓冲区大小的限制,溢写过程可能是多次的。
对于每个mapTask,当溢写结束时意味着这个mapTask处理的数据全部保存到磁盘上了。接下来即将被reduceTask接手进行聚合操作。但这段过程也会发生一些操作(这里要有时刻有序的概念):首先对于单个mapTask,当数据从缓冲区即将溢写到磁盘时会进行一次排序(由于数据存在分区标签,会做到每个区的数据有序),由于溢写过程可能发生多次,那么多次溢写成所有数据后,只保证了每次溢写内的数据有序,所以还需要一次归并排序,将多次溢写的数据整理成一个整体并且该整体内数据每个区有序。需要注意的是,在这里还存在一个Combiner处理,对于Combiner我们可以理解为中继reducer,就是它可以干和reducer一样的活,帮reducer减轻处理压力,它发生在每个mapTask溢写完成数据的阶段,它可以把最后单一mapTask归并成整体的数据里按区处理数据。
当每个mapTask完事的时候,对每个单一mapTask归并后输出的整体数据,会按每个分区再进行合并,即从mapTask1(区1,区2),mapTask2(区1,区2),mapTask3(区1,区2)...mapTaskn(区1,区2),变成区1(mapTask1,mapTask2,...mapTaskn),按区合并之后将数据传给reduceTask。
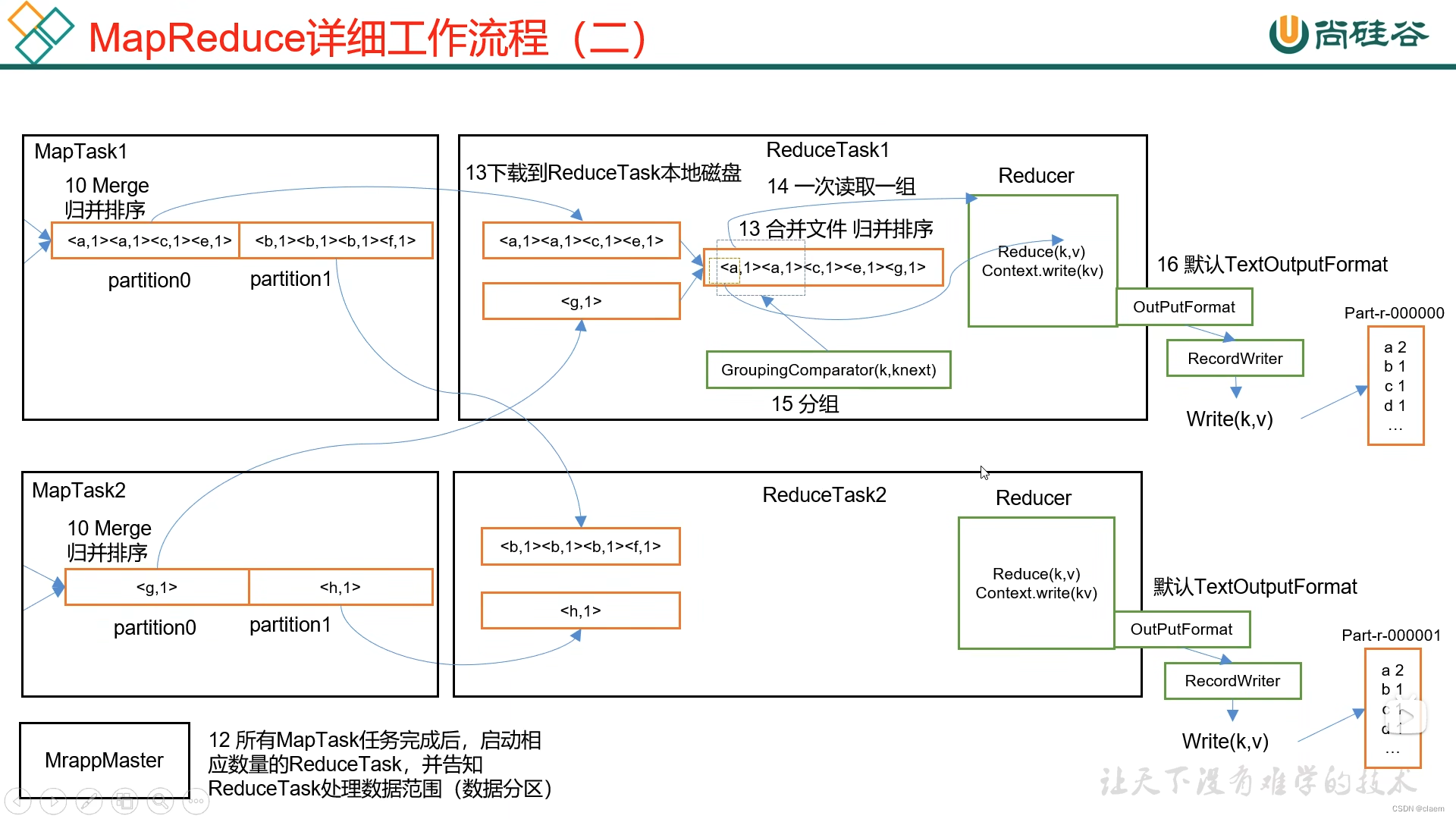
这里合并传给reduceTask之后还需要再排序一遍,保证reducer处理的数据是有序的,reducer里的reduce方法每次处理相同key的数据。处理完后通过outputformat写出数据,需要注意的是有多少个分区就会启动多少个reduceTask,当然如果reduceTask数量少于分区数,则存在分区无法被reduceTask处理,会报错,如果reduceTask数量多于分区数量,则会造成reduceTask的浪费。
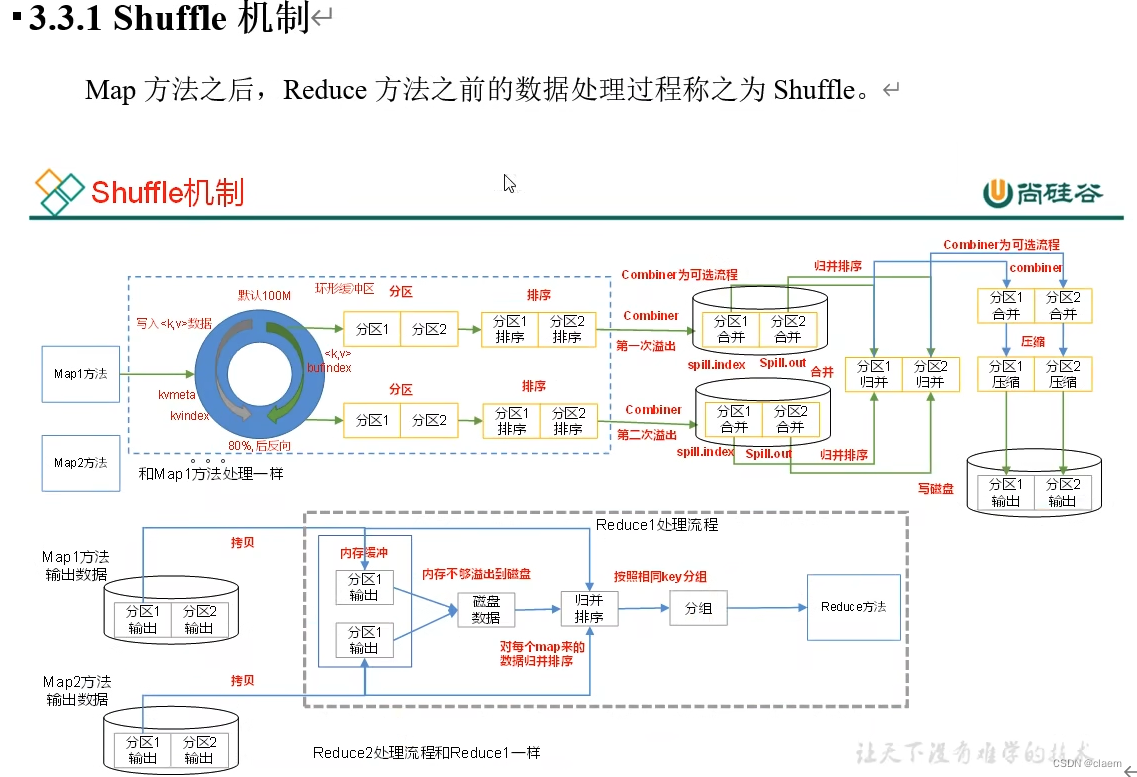
Mapper里的map方法之后到Reducer里的reduce方法之前的这段数据操作称为Shuffle:如下图

















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









