







K-Means算法
算法步骤
K-Means算法,即K均值算法,是最常见的一种聚类算法。顾名思义,该算法会将数据集分为K个簇,每个簇使用簇内所有样本的均值来表示,我们将该均值成为‘质心’。具体步骤如下:
- 从样本中选择K个点作为初始质心
- 计算每个样本到各个质心的距离,将样本划分到距离最近的质心所对应的簇中。
- 计算每个簇内所有样本的均值,并使用该均值更新簇的质心。
- 重复步骤2与3,直到达到以下条件之一结束:
▷质心的位置变化小于指定的阈值。
▷达到最大迭代次数。
优化目标
K-Means算法的目标就是选择合适的质心,使得在每个簇内,样本距离质心的距离尽可能的小。这样就可以保证簇内样本具有较高的相似性。我们可以使用最小化簇内误差平方和(within-cluster sum-of-squares SSE)来作为优化算法的量化目标(目标函数),簇内误差平方和也称为簇惯性(inertia)。
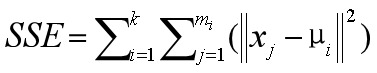
- k:簇的数量。
- mi:第i个簇含有的样本数量。
- μi:第i个簇的质心。
- ||xj - μi||:第i个簇中,每个样本xj与质心μi的距离。
算法优点与缺点
K-Means优点如下:
- 理解与实现简单。
- 可以很好的扩展到大量样本中。
- 广泛应用于不同领域。
同时,K-Means算法也具有一定的缺点:
- 需要事先指定K值,如果K值选择不当,聚类效果可能不佳。
- 聚类结果受初始质心的影响,可能会收敛到局部最小值。
- 适用于凸形的数据分布,对于条形或不规则形状的数据,效果较差。
程序演示
假设班级有50名学生参加期末考试,考试科目为语文、数学,现在想根据分数将学生分成若干个类别。
#首先绘制学生成绩的散点图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = 12
np.random.seed(1) #设置随机种子
#生成样本数据
x = np.random.randint(70,100,size=(50,2)) #从70-100中随机生成100个数,数组形状为50行2列
plt.scatter(x[:, 0]< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









