









之前已经分享过基于模型的动态规划方法(DP)和基于免模型的蒙特卡罗法(MC),DP方法解决了在MDP框架下环境已知的情况下求解值函数和策略,而MC是在不知道环境的情况,通过与环境足够的交互来获得经验来进行学习值函数和策略。但是MC需要等到每次试验结束才更新,学习效率低,而本次分享的时间差分(TD)可以结合MC的采样和DP的bootstrapping。
我们先来回顾一下MC的特点:

TD的特点如下:

下面把MC和TD的值函数更新作一个对比:

如上所示,TD中才会把Gt写成递归的形式。这样,每走一步都可以更新一次V。而蒙特卡罗中,却需要走完整个样本,才能得到Gt,从而更新一次。蒙特卡罗学习方法的更新是这样的:
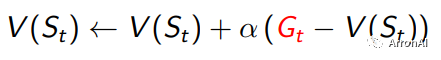
在TD中,算法在估计某一个状态的价值时,用的是离开该状态时的即时奖励Rt+1与下一个状态t+1的预估状态价值乘以折扣因子γ组成,

其中,bootstrapping指的就是TD目标值Rt+1+γV(St+1)代替Gt的过程。
显然,蒙特卡罗每次更新都需要等到agent到达终点之后再更新;而对于TD来说,agent每走一步它都可以更新一次,不需要等到到达终点之后才进行更新。
下面我们从多个角度来对比一下MC和TD:
1、方差与偏差
我们在实际使用中发现MC和TD两种算法的表现却差别比较大,熟悉机器学习的朋友们都知道偏差和方差的概念,那我们先从这两个角度来分析一个这两个算法:

MC的期望是值函数的定义,因此MC是无偏估计,但是MC每次得到的累计回报Gt随机性很大,因此尽管期望等于真值,但是方差无穷大。TD中如果V(St+1)采用真实值,那么TD也是无偏估计,然而在实验中V(St+1)也是估计值,因此TD属于有偏估计。与MC方法相比,TD是用到了一步随机状态和动作,因此TD目标的随机性要比MC的Gt小,相应的方差也比MC小,具体对比如下:
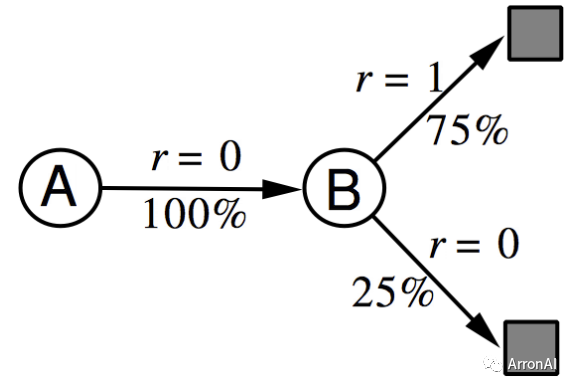
AB example
已知:有两个状态A和B,折扣因子为1,有8个完整的episodes。除了第一个episode有状态转移之外,其余7个均只有一个状态。如下图所示:

问题就是要求解出V(A)和V(B)。
解释:假如应用MC算法,由于需要完整的episode,因此,只有episode1 能够用来计算A的状态值,所以显然,V(A) = 0;同时B状态的价值为6/8。而对于TD算法来说,由于状态A的后继有状态B,所以状态A的价值是通过状态B的价值来计算的。所以根据上面TD的计算公式,V(A)=V(B) = 6/8.
2、收敛性对比

DP、MC和TD对比
1、值函数更新方式
Monte-Carlo, Temporal-Difference 和Dynamic Programming这三种学习方法都是用来计算状态价值的。它们的区别在于,前两种是在不知道模型的情况下常用的方法,而MC方法又需要一个完整的episode来更新状态价值,TD则不需要完整的episode。DP方法则是基于Model(知道模型的运作方式)的计算状态价值的方法。它通过计算一个状态S所有可能的转移状态S’及其转移概率以及对应的即时奖励来计算这个状态S的价值。也正是因为它知道整个模型的情况(知道状态转移概率与即时奖励),所以它才能够这样子计算全面的情况。下面的图可以直观地看出它们的区别:
1)MC
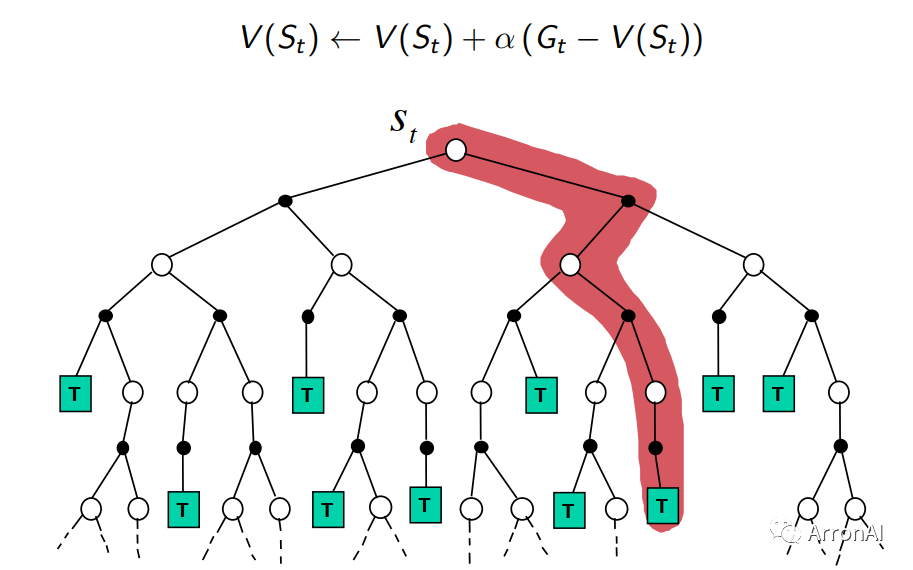
上图中的这颗树,代表了整个状态与动作空间。对于蒙特卡罗方法来说,要更新一次V值,需要有一个完整的样本(即图中红色部分就是一个样本)。这条路径经过了三个状态,所以可以更新三个状态的V值。由于不知道模型情况,所以无法计算从St到下面四个节点的概率以及即时奖励,所以一次只能更新一条路径。如果重复次数够多了,就能覆盖所有的路径,最后的结果才能跟动态规划那样。
2)TD
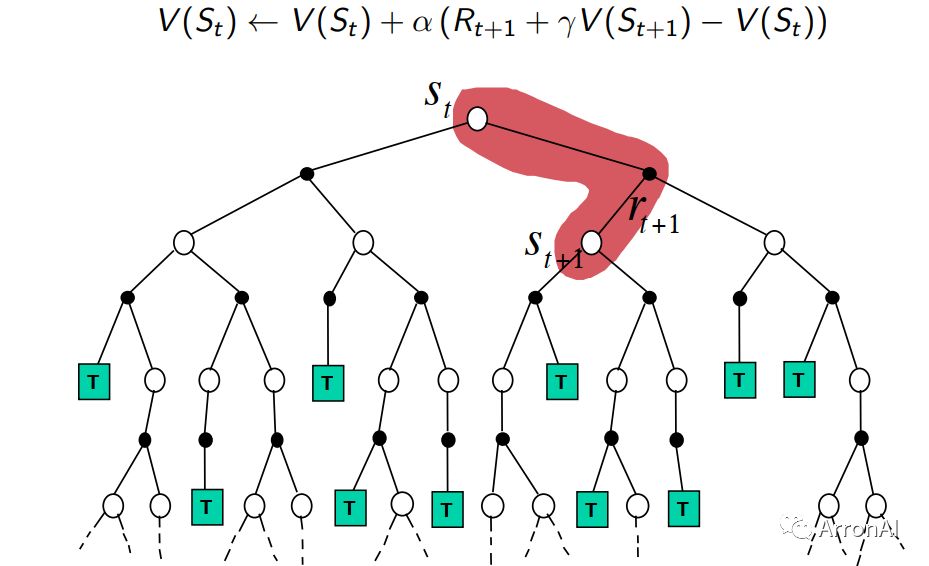
上图的红色部分是TD每次更新所需要的,每次更新只考虑下一步的状态值函数。对于MC和TD来说,它们都是模型不可知的,所以它们只能通过尝试来近似真实值
3)DP

这是动态规划的V值计算,由于知道了模型,所以可以直接使用贝尔曼公式计算期望V值。
2、Bootstrapping and Sampling

综上所述,时间差分TD算法和蒙特卡罗算法MC以及动态规划DP有千丝万缕的联系。首先MC与TD都是免模型的方法,但是他们的目标是不一样的,值函数的更新公式不同,导致他们的效果差别还是比较大的,MC的方差比较大,TD的偏差比较大,这时候很容易想到梯度下降,可以通过batch来改进。本文只介绍了TD的基本思想和原理,下面会介绍两种经典的算法Sarsa和Qlearning算法,以及TD(λ),敬请期待。
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











