









 研究提出了一种新的人群计数模型PointquEryTransformer(PET),将人群计数视为点查询过程,通过点查询四叉树处理密集人群,解决了查询点数量的问题。PET适用于多种任务,包括全监督计数、定位等。作者展示了PET在实验中的初步结果,尽管存在一些差距,但仍显示出其潜力。
研究提出了一种新的人群计数模型PointquEryTransformer(PET),将人群计数视为点查询过程,通过点查询四叉树处理密集人群,解决了查询点数量的问题。PET适用于多种任务,包括全监督计数、定位等。作者展示了PET在实验中的初步结果,尽管存在一些差距,但仍显示出其潜力。
一、Point-Query Quadtree for Crowd Counting, Localization, and More (ICCV 2023)
 https://arxiv.org/abs/2308.13814
https://arxiv.org/abs/2308.13814摘要:
我们证明人群计数可以被视为可分解的点查询过程。该公式允许任意点作为输入,并共同推理这些点是否拥挤以及它们所在的位置。查询处理提出了关于必要查询点的数量的根本问题:太少意味着低估,太多会增加计算开销。为了解决这个困境,我们引入了一种可分解的结构,即点查询四叉树,并提出了一种新的计数模型Point quEry Transformer (PET)。
正文:
1. 人群计数现有方法:
(1) 密度图:无法提供对人群的直观了解,即没有提供实例级信息。
(2) 头部边界框:将人群计数视为头部检测问题。但由于box信息的缺失,检测精度理论上无法保证。
(3) 单个头部点:直接输出头点,绕过了边界框估计容易出错的阶段。但通常需要进行后处理才能获得每个人的位置,因此,拥挤的场景可能会导致计数或定位失败。
此外,现有技术通常解决特定的计数任务或学习范式,每个都需要定制设计。这阻碍了它们在不同应用程序或任务中的使用。例如,全监督计数模型通常无法很好地解决半监督人群计数问题。
2. 本文的工作:
(1)提供了直观且通用的人群建模:人群计数制定为可分解的点查询过程。点查询设计允许模型接收任意点作为输入,并推断每个点是否是一个人以及它所在的位置。我们的公式自然适合不同的人群相关任务,例如完全监督的人群计数和定位、部分注释学习和点注释细化
(2)点查询四叉树:主要优点是它允许数据相关的分裂,必要时,一个查询点可以分割成多个新的查询点,从而实现稀疏区域和密集区域的动态处理。基于四叉树,我们实例化一个Point quEry Transformer(PET)来实现可分解的点查询。
(3)PET 的另一个关键要素是渐进式矩形窗口注意力,其中查询过程是在局部窗口内执行的,而不是以渐进的方式在整个图像中执行,以实现有效的推理。
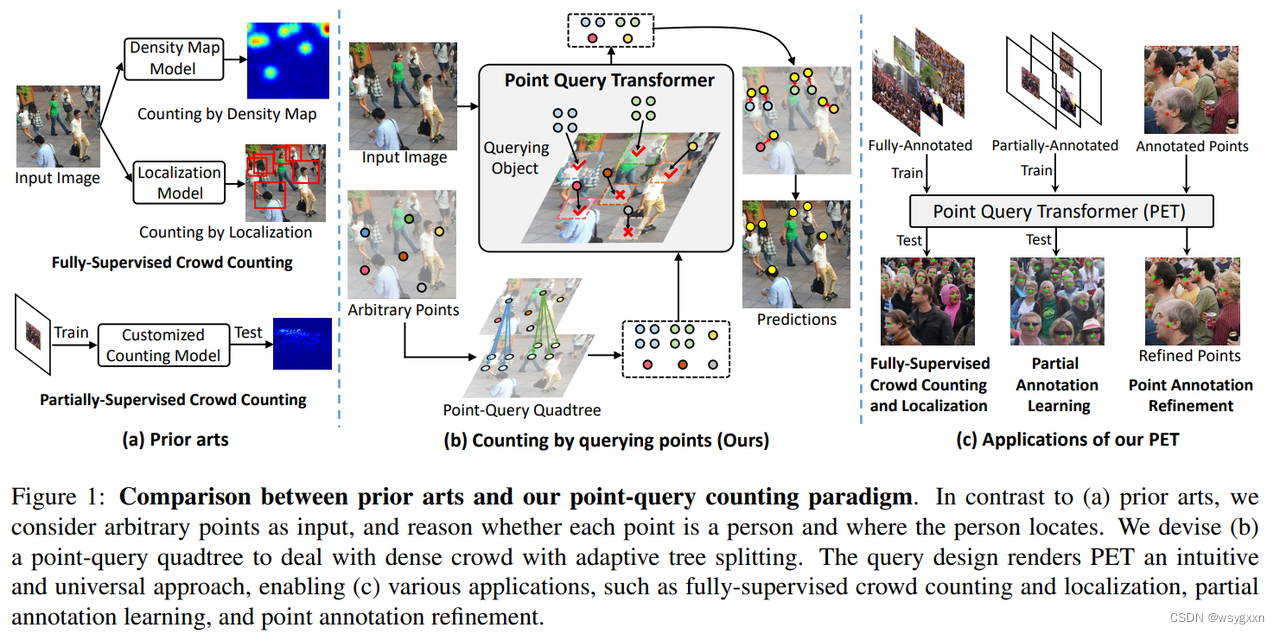
图1:现有技术与我们的点查询计数范例之间的比较。与(a)现有技术相比,我们将任意点视为输入,并推理每个点是否是一个人以及该人位于哪里。我们设计了(b)点查询四叉树来通过自适应树分裂来处理密集人群。查询设计使 PET 成为一种直观且通用的方法,从而实现 (c) 各种应用,例如完全监督的人群计数和定位、部分注释学习和点注释细化。
3. 架构概述:
在 PET 中,有两个要素至关重要:i)点查询四叉树的设计; ii)渐进式矩形窗口注意机制。前者自适应地生成查询点来解决密集人群预测,后者提高了效率。PET 的整体架构(图2)包括四个组件:a CNN backbone, an efficient encoder-decoder transformer, a point-query quadtree, and a prediction head。
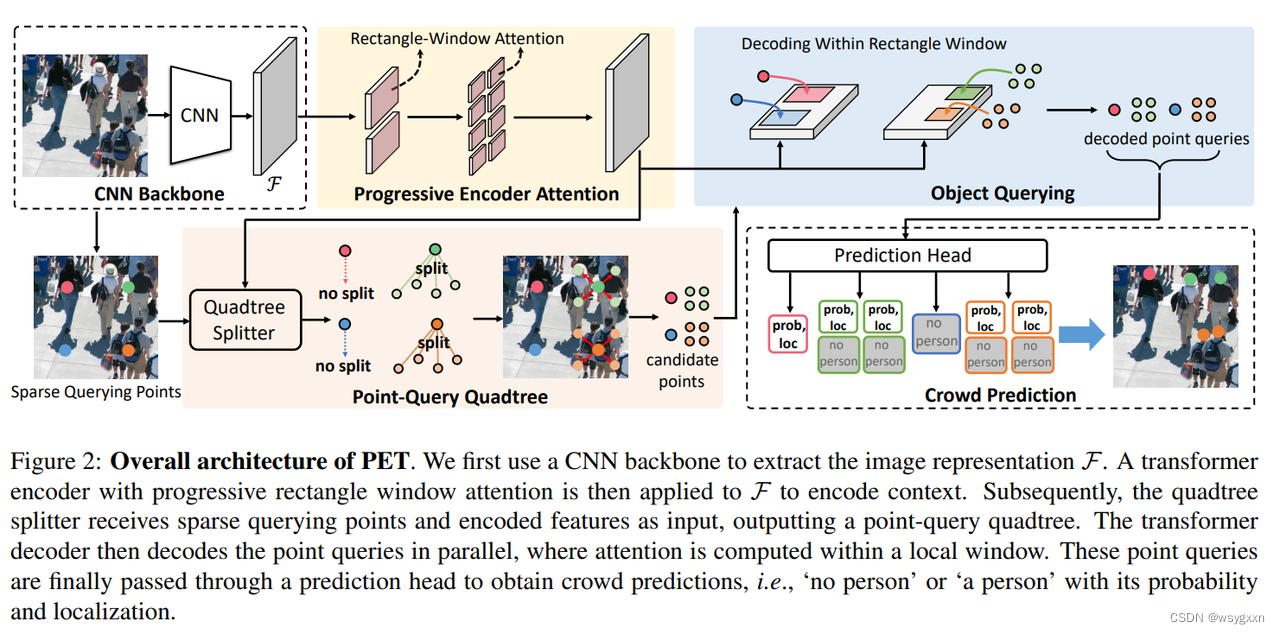
图 2:PET 的整体架构。我们首先使用CNN backbone来提取图像表示 F。然后将具有渐进式矩形窗口注意力的transformer encoder应用于 F 以对上下文进行编码。随后,quadtree splitter接收稀疏查询点和编码特征作为输入,输出点查询四叉树。然后,The transformer decoder并行解码点查询,其中在本地窗口内计算注意力。这些点查询最终通过prediction head来获得人群预测,即“无人”或“一个人”及其概率和定位。
3.1 Point-Query Quadtree
三个问题:1)如何使查询点的数量适应不同的场景; 2)如何表示一个点查询; 3)如何通过点查询来预测人群。
四叉树遵循从稀疏到密集的过程,即稀疏查询点首先跨越图像,然后在拥挤的场景中自适应地将它们分割成密集查询点以进行密集人群预测。我们认为分裂过程应该通过检查局部区域来确定,而不是依赖于单个点。因此,我们采用基于区域的四叉树分割器来构造四叉树。
3.2 Progressive Querying in Rectangle Window
我们设计了一个水平窗口,因为它通常比垂直窗口容纳更多的人,如图3。

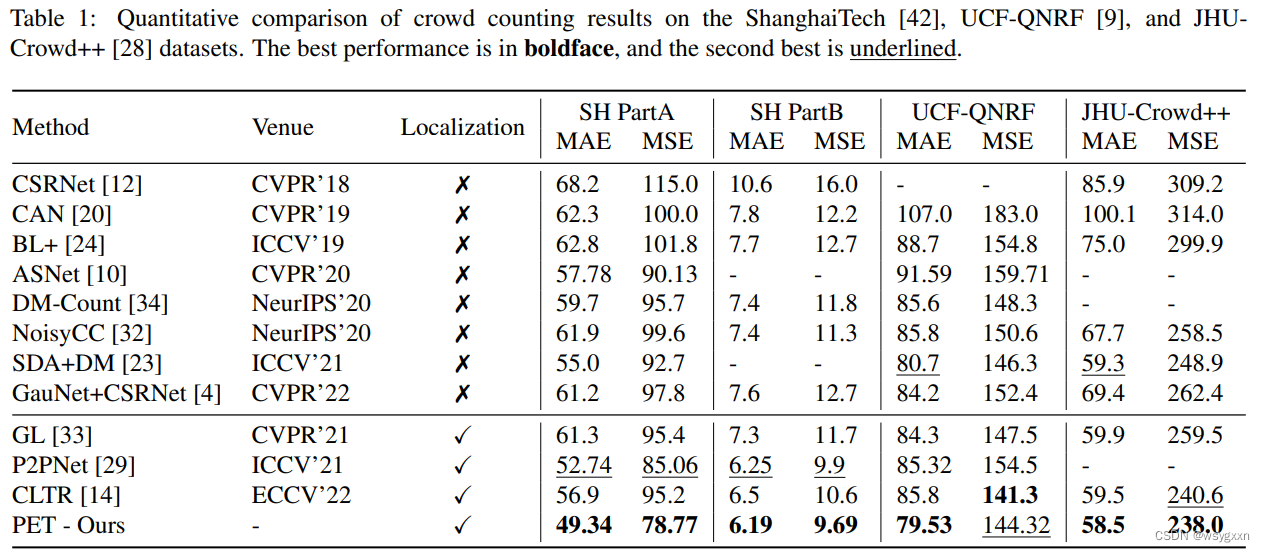
4. 实验结果
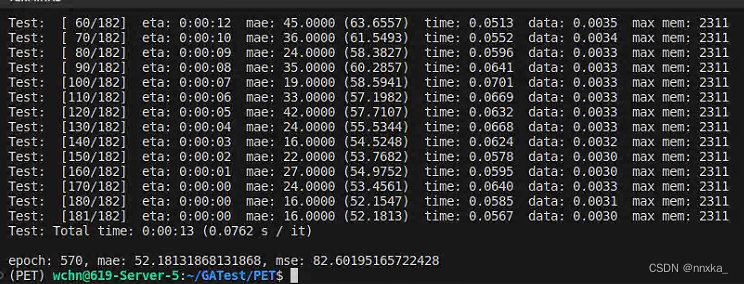
我的实验结果
图5为我复现的结果,可以看出,目前我跑出的mae和mse指标大于文章里给出的结果。根据作者在Issues里的回答,初步判断是环境问题。
记录日期:2024年4月


















 3949
3949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









