









Paper![]() https://arxiv.org/abs/2212.09748 Code
https://arxiv.org/abs/2212.09748 Code![]() https://github.com/facebookresearch/DiT
https://github.com/facebookresearch/DiT
目录
用transformer替换处理latent patches的U-Net backbone。本文作者发现,通过增加Transformer深度/宽度或增加输入令牌数量,具有较高Gflops的DiT始终具有较低的FID。除了具有良好的可扩展性外,最大的DiT-XL/2模型在条件类ImageNet 512×512和256×256基准测试中的表现优于所有先前的扩散模型,在后者上实现了2.27的最先进FID。
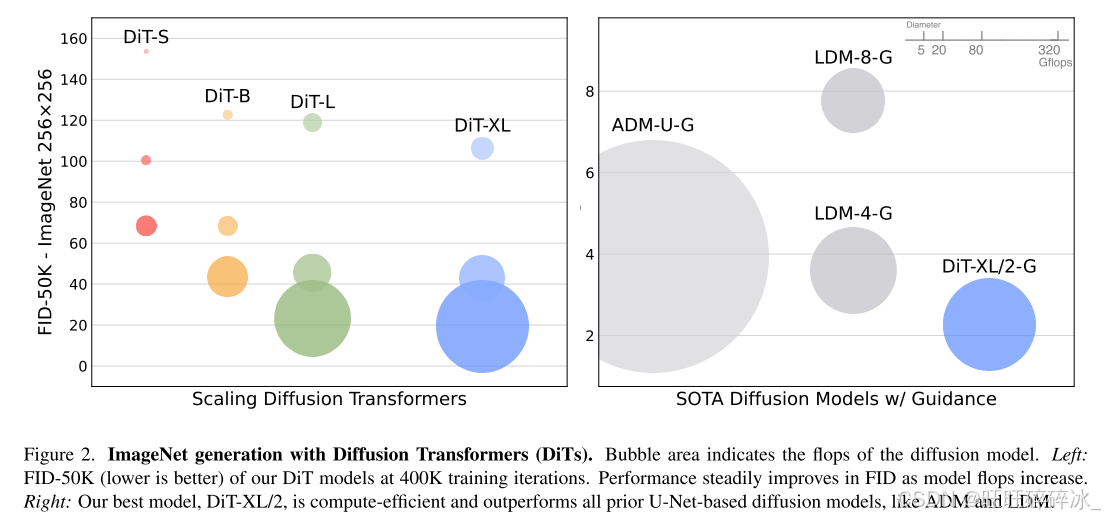
方法:
本文介绍了一种新的扩散模型结构--扩散变换器(DiT)。我们的目标是尽可能忠实于标准Transformer架构,以保持其扩展特性。由于我们的重点是训练图像的DDPM(具体而言,图像的空间表示),因此DiT基于VIT。

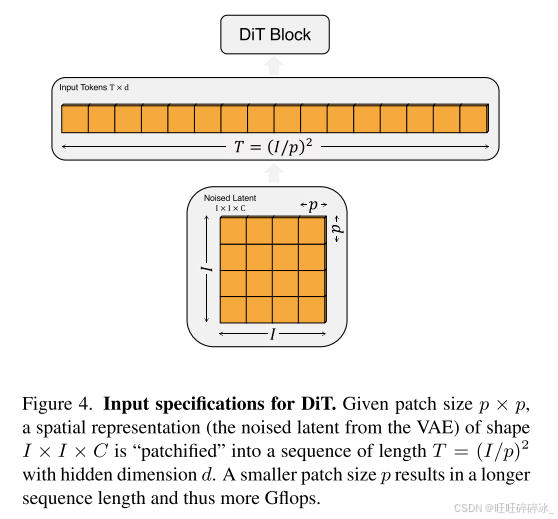
Patchify. DIT的输入是空间表示z(对于256 × 256 × 3图像,z的形状为32 × 32 × 4)。它通过在输入中线性地嵌入每个patch,将空间输入转换为T个tokens的序列,每个token的维数为d。与patchify一起,我们把标准VIT位置嵌入应用于所有tokens。
如图4,将p减半将使T增加四倍,因此至少使总Transformer Gflops增加四倍。尽管它对Gflops有显著影响,但请注意,更改p对下游参数计数没有任何有意义的影响。我们将p = 2、4、8添加到DiT设计空间。
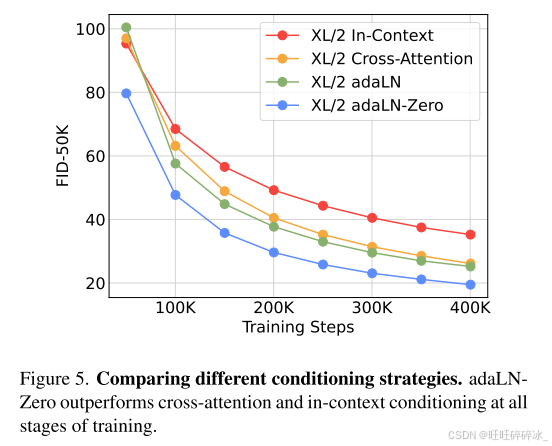
DiT block design. 在patchify之后,输入tokens由一系列Transformer块处理。除了噪声图像输入,扩散模型有时处理额外的条件信息,如噪声时间步长t,类标签c,自然语言等。我们探讨了Transformer块的四种变体处理不同条件输入。这些设计对标准ViT块设计进行了微小但重要的修改。所有试验块的设计如图3所示。
(1)In-context conditioning. 我们简单地将t和c的向量嵌入作为两个额外的标记添加到输入序列中,将它们与图像标记没有区别地对待。这类似于ViT中的cls令牌,它允许我们使用标准的ViT块而无需修改。在最后一个块之后,我们从序列中移除条件标记。该方法向模型引入了可忽略不计的新Gflops。
(2)Cross-attention block. 我们将t和c的嵌入连接成一个长度为2的序列,与图像标记序列分开。修改了Transformer块,以在多头自注意块之后包括额外的多头交叉注意层,类似于Vaswani等人的原始设计,也类似于LDM用于调节类标签的层。交叉注意为模型增加了最多的Gflops,大约为15%的开销。
(3)Adaptive layer norm (adaLN) block. 在GAN和具有UNet骨干的扩散模型中广泛使用自适应归一化层之后,我们探索用自适应层范数(adaLN)替换Transformer块中的标准层范数层。我们不是直接学习维度尺度和移位参数γ和β,而是从t和c的嵌入向量之和回归它们。在我们研究的三种块设计中,adaLN添加的Gflops最少,因此计算效率最高。它也是唯一一种限制为对所有令牌应用相同功能的条件机制。
(4)adaLN-Zero block. 先前关于ResNets的工作已经发现,将每个残差块初始化为单位函数是有益的。扩散U-Net模型使用类似的初始化策略,在任何残差连接之前,对每个块中的最终卷积层进行零初始化。我们探索了一种改良的adaLN DiT阻断剂,其具有相同的作用。除了回归γ和β之外,我们还回归了在DiT块内的任何残差连接之前立即应用的维度标度参数α。
Model size. 我们应用N个DiT块的序列,每个DiT块以隐藏维度大小d操作。在ViT之后,我们使用标准的Transformer转换器来联合缩放N、d和注意力头。具体而言,我们使用四种配置:DiT-S、DiT-B、DiT-L和DiT-XL。
Transformer decoder. 在最后的DiT块之后,我们需要将我们的图像tokens序列解码为输出噪声预测和输出对角协方差预测。这两个输出都具有与原始空间输入相等的形状。我们使用标准的线性解码器来完成此操作。我们应用最终层范数(如果使用adaLN,则为自适应),并将每个令牌线性解码为p×p×2C张量,其中C是DiT的空间输入中的通道数。最后,我们将解码后的记号重新排列成它们原来的空间布局,以得到预测的噪声和协方差。
实验设置:
我们在ImageNet数据集上以256 × 256和512 × 512图像分辨率训练类条件潜在DiT模型。我们用零初始化最后的线性层,其他使用来自ViT的标准权重初始化。我们使用AdamW训练所有模型。我们使用1e−4的恒定学习率,没有权重衰减,批量大小为256。我们唯一使用的数据增强是水平翻转。
我们使用了来自SD的现成的预训练变分自动编码器(VAE)模型。VAE编码器的下采样系数为8——给定RGB图像x的形状为256 × 256 × 3,z = E(x)的形状为32 × 32 × 4。在本节的所有实验中,我们的扩散模型都是在这个Z空间中进行的。在从我们的扩散模型中采样新的潜像之后,我们使用VAE解码器x = D(z)将其解码为像素。
评估指标。我们使用FID来衡量缩放性能,FID是评估图像生成模型的标准度量。使用250步DDPM采样,计算FID-50K的结果,没用特殊说明时未采用classifier-free guiance。此外还增加了Inception Score、sFID、Precision/Recall等指标。
结论:
本文引入了扩散变换器(DiTs),这是一个简单的基于变换器的扩散模型主干,它优于先前的U-Net模型,并继承了Transformer模型类的出色缩放特性。鉴于本文中的缩放结果,未来的工作应继续将DiT缩放到更大的模型和令牌计数。DiT也可以作为文本到图像模型(如DALL·E 2和Stable Diffusion)的嵌入式主干进行探索。
DiT代码:
Sampling
python sample.py --image-size 512 --seed 1Training DiT
To launch DiT-XL/2 (256x256) training with N GPUs on one node:
python sample.py --model DiT-L/4 --image-size 256 --ckpt /path/to/model.pt训练和采样均使用以下代码设置DIT_models,
model = DiT_models[args.model](
input_size=latent_size,
num_classes=args.num_classes
)DiT
下面进入DiT_models,看看怎么运行的。先来看Class DiT的初始化。可以看出,对inputs(图片的latent特征表示)、timesteps、class_lables的编码分别使用PatchEmbed、TimestepEmbedder、LabelEmbedder。
class DiT(nn.Module):
"""
Diffusion model with a Transformer backbone.
"""
def __init__(
self,
input_size=32,
patch_size=2,
in_channels=4,
hidden_size=1152,
depth=28,
num_heads=16,
mlp_ratio=4.0,
class_dropout_prob=0.1,
num_classes=1000,
learn_sigma=True,
):
super().__init__()
self.learn_sigma = learn_sigma
self.in_channels = in_channels
self.out_channels = in_channels * 2 if learn_sigma else in_channels
self.patch_size = patch_size
self.num_heads = num_heads
self.x_embedder = PatchEmbed(input_size, patch_size, in_channels, hidden_size, bias=True)
self.t_embedder = TimestepEmbedder(hidden_size)
self.y_embedder = LabelEmbedder(num_classes, hidden_size, class_dropout_prob)
num_patches = self.x_embedder.num_patches
# Will use fixed sin-cos embedding:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, hidden_size), requires_grad=False)
self.blocks = nn.ModuleList([
DiTBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(depth)
])
self.final_layer = FinalLayer(hidden_size, patch_size, self.out_channels)
self.initialize_weights()再来看class DiT的forward函数,输入的条件c为timesteps和class_label编码后相加,x为编码后的图片和位置编码相加,将x和c送入到DiTBlock块中处理,再通过FinalLayer和unpatchify得到输出结果。
def forward(self, x, t, y):
"""
Forward pass of DiT.
x: (N, C, H, W) tensor of spatial inputs (images or latent representations of images)
t: (N,) tensor of diffusion timesteps
y: (N,) tensor of class labels
"""
x = self.x_embedder(x) + self.pos_embed # (N, T, D), where T = H * W / patch_size ** 2
t = self.t_embedder(t) # (N, D)
y = self.y_embedder(y, self.training) # (N, D)
c = t + y # (N, D)
for block in self.blocks:
x = block(x, c) # (N, T, D)
x = self.final_layer(x, c) # (N, T, patch_size ** 2 * out_channels)
x = self.unpatchify(x) # (N, out_channels, H, W)
return xDiT的forward_with_cfg会在采样使用cfg时用到,具体是使用了 Classifier-Free Guidance (CFG) 技术。其内部会调用self.forward得到模型输出,然后分离出eps 和 rest,eps是噪声预测结果,rest是方差,再将eps分为cond_eps, uncond_eps,分为有条件和无条件引导,这是由samply.py文件中模型输入方式决定的:
sample.py
# 这里的标号对应的是ImageNet数据集标签
class_labels = [207, 360, 387, 974, 88, 979, 417, 279]
# Create sampling noise:
n = len(class_labels)
z = torch.randn(n, 4, latent_size, latent_size, device=device)
y = torch.tensor(class_labels, device=device)
# Setup classifier-free guidance:
z = torch.cat([z, z], 0)
y_null = torch.tensor([1000] * n, device=device)
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=args.cfg_scale)
# Sample images:
samples = diffusion.p_sample_loop(
model.forward_with_cfg, z.shape, z, clip_denoised=False, model_kwargs=model_kwargs, progress=True, device=device
)def forward_with_cfg(self, x, t, y, cfg_scale):
"""
Forward pass of DiT, but also batches the unconditional forward pass for classifier-free guidance.
"""
# https://github.com/openai/glide-text2im/blob/main/notebooks/text2im.ipynb
half = x[: len(x) // 2]
combined = torch.cat([half, half], dim=0)
model_out = self.forward(combined, t, y)
# For exact reproducibility reasons, we apply classifier-free guidance on only
# three channels by default. The standard approach to cfg applies it to all channels.
# This can be done by uncommenting the following line and commenting-out the line following that.
# eps, rest = model_out[:, :self.in_channels], model_out[:, self.in_channels:]
eps, rest = model_out[:, :3], model_out[:, 3:]
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)
eps = torch.cat([half_eps, half_eps], dim=0)
return torch.cat([eps, rest], dim=1)
DiTBlock
下面看DiTBlock,在init初始化时,norm1和norm2初始化为elementwise_affine=False,不进行仿射变换,LayerNorm层不含有可学习参数;在forward函数中,条件c经过self.adaLN_modulation处理,得到6个参数。对input tokens x进行Layer Norm、Scale、Shift后进行attn多头自注意力,然后乘α系数与x进行残差连接得到新的输出x,再对x进行Layer Norm、Scale、Shift后使用mlp(Pointwise Feedforward),再次进行残差连接,得到最终的输出x:
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
#使用自适应归一化替换标准归一化层
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
# 残差连接
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x
FinalLayer
对应方法中Transformer deocder,将图像tokens序列解码为输出噪声预测和输出对角协方差预测。
class FinalLayer(nn.Module):
"""
The final layer of DiT.
"""
def __init__(self, hidden_size, patch_size, out_channels):
super().__init__()
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 2 * hidden_size, bias=True)
)
def forward(self, x, c):
shift, scale = self.adaLN_modulation(c).chunk(2, dim=1)
x = modulate(self.norm_final(x), shift, scale)
x = self.linear(x)
return x再来看Class DiT中的最后一步unpatchify,将最后一层得到的x恢复为原始图片,将每个patch重新拼回图像。
def unpatchify(self, x):
"""
x: (N, T, patch_size**2 * C)
imgs: (N, H, W, C)
"""
c = self.out_channels
p = self.x_embedder.patch_size[0]
h = w = int(x.shape[1] ** 0.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], c, h * p, h * p))
return imgs下面附上TimestepEmbedder和LabelEmbedder:
TimestepEmbedder
class TimestepEmbedder(nn.Module):
"""
Embeds scalar timesteps into vector representations.
"""
def __init__(self, hidden_size, frequency_embedding_size=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(frequency_embedding_size, hidden_size, bias=True),
nn.SiLU(),
nn.Linear(hidden_size, hidden_size, bias=True),
)
self.frequency_embedding_size = frequency_embedding_size
@staticmethod
def timestep_embedding(t, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param t: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an (N, D) Tensor of positional embeddings.
"""
# https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=t.device)
args = t[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
def forward(self, t):
t_freq = self.timestep_embedding(t, self.frequency_embedding_size)
t_emb = self.mlp(t_freq)
return t_emb
LabelEmbedder
class LabelEmbedder(nn.Module):
"""
Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance.
"""
def __init__(self, num_classes, hidden_size, dropout_prob):
super().__init__()
use_cfg_embedding = dropout_prob > 0
self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
self.num_classes = num_classes
self.dropout_prob = dropout_prob
def token_drop(self, labels, force_drop_ids=None):
"""
Drops labels to enable classifier-free guidance.
"""
if force_drop_ids is None:
drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob
else:
drop_ids = force_drop_ids == 1
labels = torch.where(drop_ids, self.num_classes, labels)
return labels
def forward(self, labels, train, force_drop_ids=None):
use_dropout = self.dropout_prob > 0
if (train and use_dropout) or (force_drop_ids is not None):
labels = self.token_drop(labels, force_drop_ids)
embeddings = self.embedding_table(labels)
return embeddings

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









