




ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
paper![]() https://arxiv.org/pdf/2302.05543 code
https://arxiv.org/pdf/2302.05543 code![]() https://github.com/lllyasviel/ControlNet
https://github.com/lllyasviel/ControlNet
目录
ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet for Text-to-Image Diffusion
一、背景及要解决的问题:
ControlNet可以将空间条件控制添加到大型的预训练文生图扩散模型中。文生图对空间控制有限,仅通过文本提示精确地表达复杂的布局、姿势、形状和形式可能是困难的。本文希望通过让用户提供额外的图像来直接指定他们想要的图像组合,从而实现更细粒度的空间控制。
本文介绍了ControlNet,这是一种端到端的神经网络架构,可以学习大型预训练文本到图像扩散模型的条件控制。ControlNet通过锁定其参数来保留大型模型的质量和功能,并对其编码层进行可训练的复制。可训练副本和原始锁定模型与零卷积层连接,权重初始化为零,以便它们在训练期间逐渐增长。这种架构确保在训练开始时不会将有害噪声添加到大扩散模型的深层特征中,并保护可训练副本中的大规模预训练骨干免受此类噪声的破坏。
实验表明,ControlNet可以通过各种条件输入控制稳定扩散,包括Canny边缘、霍夫线、用户涂鸦、人体关键点、分割图、形状法线、深度等。ControlNet的训练在不同大小的数据集上都是鲁棒的和可扩展的,对于某些任务,如深度到图像调节,在单个NVIDIA RTX 3090 Ti GPU上训练ControlNet可以实现与在大型计算集群上训练的工业模型具有竞争力的结果。
总之,
(1)提出了ControlNet,可以通过有效的微调将空间定位的输入条件添加到预训练的文本到图像扩散模型中;
(2)提出了预训练的ControlNet,通过条件来控制stable diffusion;
(3)消融实验验证了该方法,并针对不同任务几个先前的baseline进行用户调查。
二、相关工作:
1. Fituning
微调神经网络的一种方法是直接用额外的训练数据继续训练它。但可能导致过拟合、模式崩溃和灾难性遗忘。
HyperNetwork:是一种起源于NLP的方法,目的是训练一个小的递归神经网络来影响一个更大的神经网络的权重。它已被应用于GAN图像生成,如改变输出图像的艺术风格;
Adapter:方法被广泛用于NLP中,通过将新的模块层嵌入预训练的Transformer模型定制为其他任务。在计算机视觉中用于增量学习和预适应,通常与CLIP一起使用,用于将预训练的骨干模型转移到不同的任务。
Additive Learning:通过冻结原始模型权重并使用可学习的weight masks、pruning 、or hard attention避免遗忘。
Low-Rank Adaptation (LoRA):通过学习低秩矩阵的参数偏移来防止灾难性遗忘。
Zero-Initialized Layers:ControlNet使用零初始化层来连接网络块。
2. Image Diffusion
DDPM:https://arxiv.org/abs/2006.11239
Stable Diffusion:https://arxiv.org/abs/2112.10752
3. Image-to-Image Translation
条件GAN和transformers可以学习不同图像域之间的映射,例如,Taming Transformer是一种视觉Transformer方法;Palette是从头开始训练的条件扩散模型;PITI是一个基于预训练的条件扩散模型,用于图像到图像的变换。操纵预训练的GAN可以处理特定的图像到图像任务。
三、方法:
1. ControlNet
ControlNet将附加条件注入神经网络的块中。一个网络块F(·;Θ),参数Θ,从一个输入特征图x转换到另一个特征图y,x∈R{H,W,C}。y = F(x;Θ)。
为了将ControlNet添加到这样一个预先训练的神经块中,我们锁定(冻结)原始块的参数Θ,同时将该块克隆到具有参数$${\theta}_c$$的可训练副本中。训练副本将外部条件向量c作为输入。当这种结构应用于稳定扩散等大型模型时,锁定的参数会保留用数十亿张图像训练的生产就绪模型,而可训练副本则会重复使用此类大规模预训练模型来建立深度、鲁棒性和强大的主干,以处理不同的输入条件。
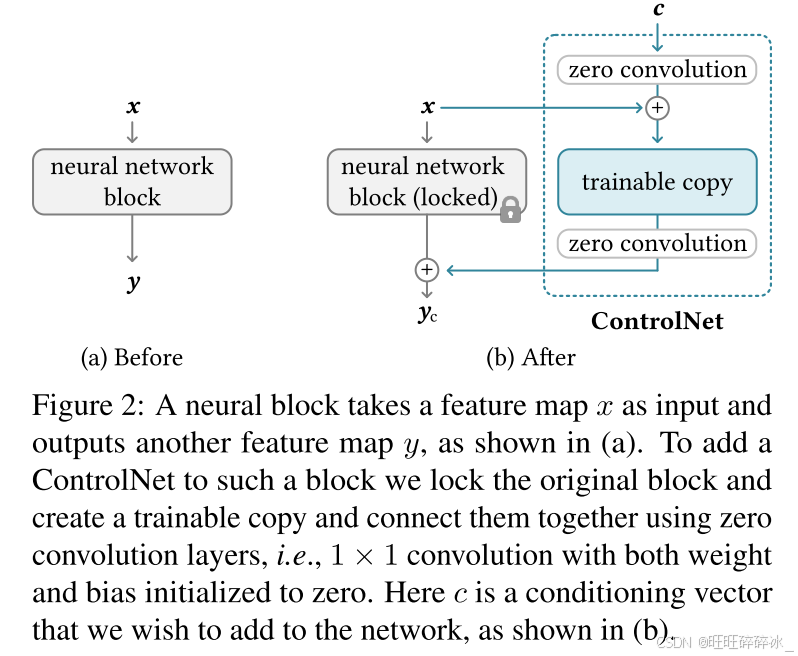
Z(·;·)表示一个1x1卷积层,权重和偏置都初始化为零。为了构建ControlNet,我们使用两个零卷积实例,分别具有参数Θz1和Θz2。然后,完整的ControlNet计算:
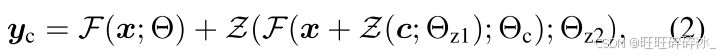
在第一步,由于零卷积层的权重和偏置参数都被初始化为零,yc=y。通过这种方式,当训练开始时,有害噪声不会影响可训练副本中神经网络层的隐藏状态。
2. ControlNet for Text-to-Image Diffusion
以Stable Diffusion为例,来展示ControlNet如何将条件控制添加到大型预训练扩散模型中。SD中的U-net在encoder和middle block中与controlnet链接。
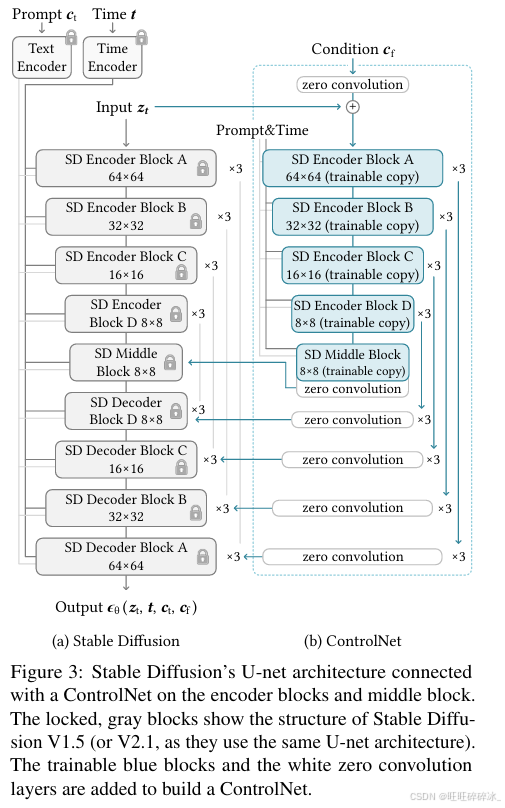
为了将ControlNet添加到SD中,我们首先将每个输入条件图像(例如,边缘、姿势、深度等)从512 × 512的输入大小转换为64 × 64的特征空间向量,与SD的大小相匹配。特别地,我们使用具有4 × 4内核和2 × 2步幅的四个卷积层的微小网络E(·)(由ReLU激活,分别使用16,32,64,128个通道,用高斯权重初始化并与完整模型联合训练)将图像空间条件ci编码为特征空间条件向量cf。cf = E(ci)。条件向量cf被传递到ControlNet。
3. Training
给定输入图像Z0,图像扩散算法逐渐将噪声添加到图像并产生噪声图像zt,其中t表示添加噪声的次数。给定包括时间步长t、文本提示ct以及特定于任务的条件cf的一组条件,图像扩散算法学习网络以预测添加到噪声图像zt的噪声,其中L是整个扩散模型的总体学习目标。L直接用于使用ControlNet微调扩散模型。
![]()
在训练过程中,我们随机将50%的文本提示ct替换为空字符串。这种方法增加了ControlNet直接识别输入条件图像中的语义的能力(例如,边缘、姿势、深度等)作为提示的替代。
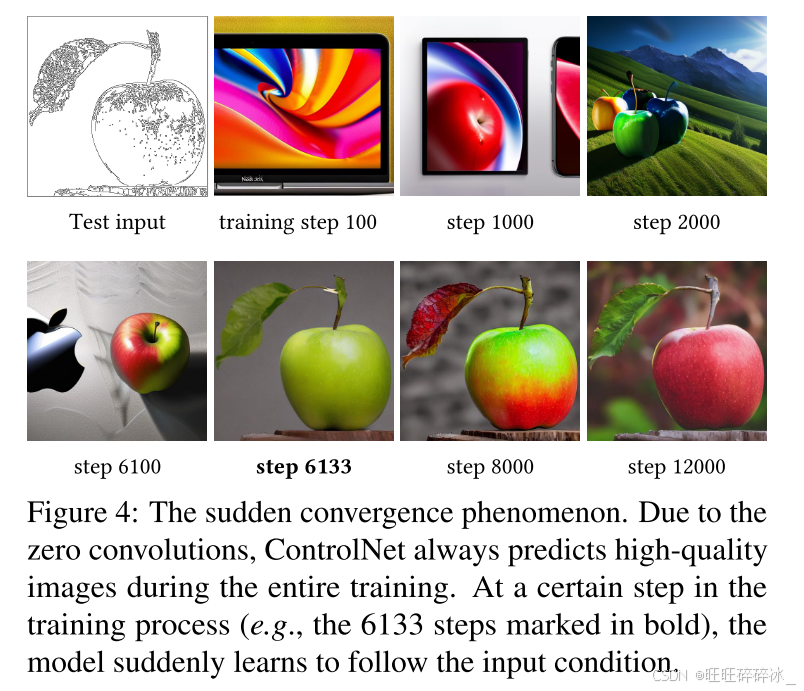
在训练过程中,由于零卷积不会给网络增加噪声,因此模型应该始终能够预测高质量的图像。我们观察到,模型并没有逐渐学习控制条件,而是在输入条件图像后突然成功;通常在不到10 K的优化步骤中。如图4所示,我们称之为“突然收敛现象”。
4. Inference
我们可以通过几种方式进一步控制ControlNet的额外条件如何影响去噪扩散过程。
Classifier-free guidance resolution weighting:SD依赖CLassifier-Free Guidance(CFG)技术来生成高质量图像,公式中从左到右依次为模型最终输出、无条件输出、用户指定的权重系数、条件输出。当通过ControlNet添加条件图像时,可以加到UC和C,或者只加到C中。图5a为添加到UC和C,会导致完全消除了CFG引导,只加到C中(图5b)会导致引导过于强。本文的方案是首先将条件图像添加到C中,然后根据每个块的分辨率wi=64/hi,将wi乘SD和ControlNet的连接,这里hi是第i个块的大小,h1=8, h2=16, ..., h13=64。通过降低CFG制导强度,我们可以实现图5d所示的结果,我们称之为CFG Resolution Weighting。
![]()

Composing multiple ControlNets:要将多个条件图像添加到SD的单个实例中,我们可以直接将相应ControlNet的输出添加到稳定扩散模型(图6)。这种合成不需要额外的加权或线性插值。

四、实验:
1. 生成结果
图1显示了几种提示设置中生成的图像。图7显示了我们在没有提示的情况下使用各种条件的结果,其中ControlNet在不同的输入条件图像中鲁棒地解释内容语义。


2. 消融实验:
设置了三种结构:(1)本文提出的结构;(2)用高斯权重初始化的标准卷积层替换零卷积;(3)用一个卷积层替换每个块的可训练副本,我们称之为ControlNet-lite。
设置了四组prompt:(1)无prompt;(2)不充分的prompt,没覆盖到条件图像中的对象,如本例中使用“高质量的详细的作品”,没有提到“房子”;(3)冲突prompt,和条件图像不同语义的prompt;(4)描述必要内容语义的完美prompt。

3. 质量评估:
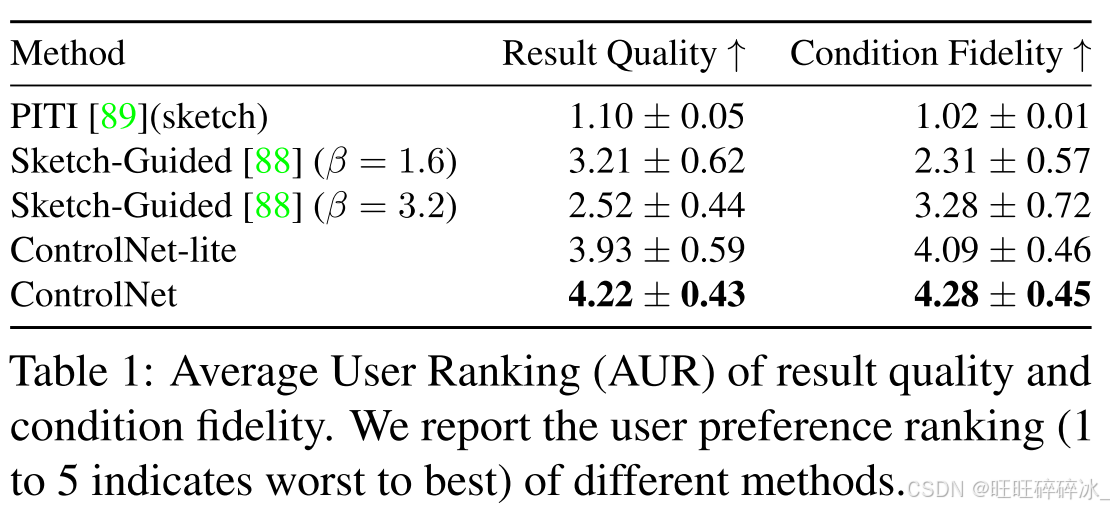
使用者调查:对20个未见过的手绘草图进行采样,分配5种方法。邀请12人来打分,从1-5,分越高质量越好。结果如表1;
与业界模型比较:SDv2用A100集群,数千小时训练超过1200w张图像,我们使用相同的深度条件,但只用3090ti在20w个训练样本上训练了5天。分别选了SDv2和ControlNet生成的100张图,来教12个用户怎么区分这两种方法,让用户说出每张图是哪个模型生成的,用户平均精度为0.52+-0.17,表明两种方法生成效果几乎没区别。
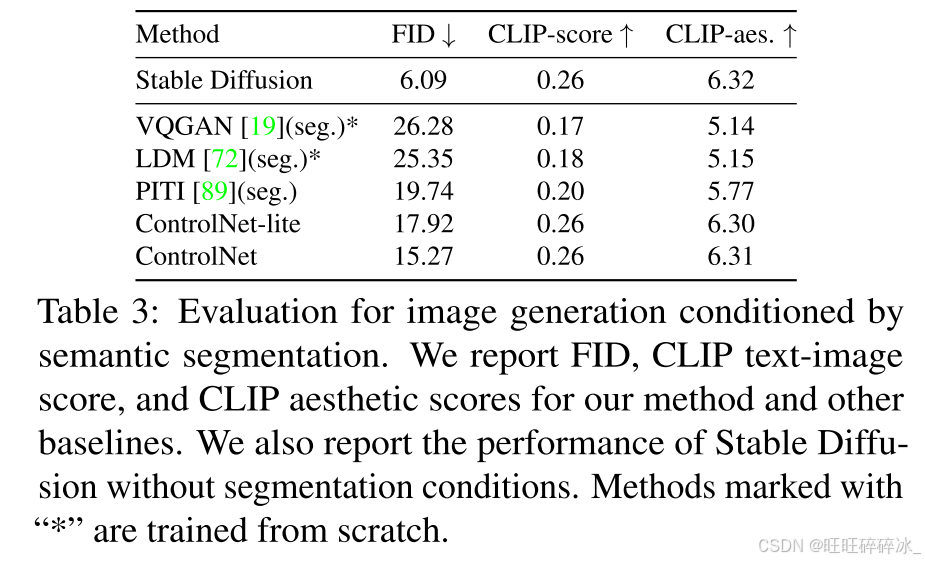
条件重建和FID评分:使用ADE20K测试集评估条件保真度,先用分割方法OneFormer在GT上实现0.58的IoU,再使用相同的模型检测生成图的IoU,见表2;FID、CLIP scores、CLIP aethetic scores,表3。

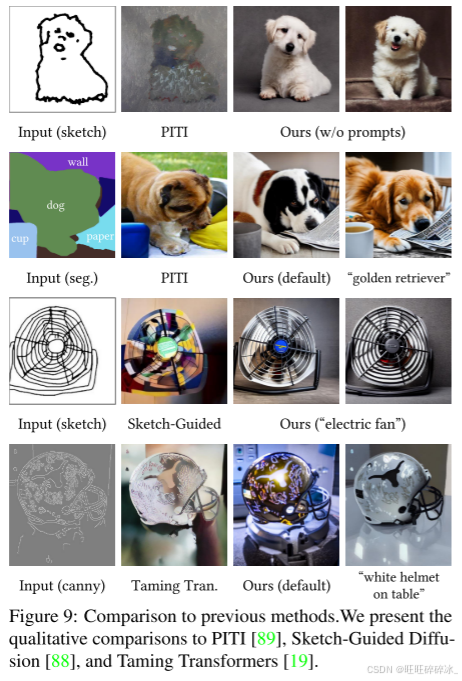
4. 与先前方法的比较
5. 讨论
数据集大小的影响:训练不会因为只有1k张图而崩溃;
解释内容的能力:ControlNet在输入条件图像中能捕获语义;
迁移能力:由于ControlNets不会改变预训练SD模型的网络拓扑,因此它可以直接应用于SD中的各种模型。

五、结论
ControlNet是一种神经网络结构,它可以学习大型预训练文本到图像扩散模型的条件控制。它重用源模型的大规模预训练层来构建一个深度和强大的编码器来学习特定条件。原始模型和可训练副本通过“零卷积”层连接,以消除训练过程中的有害噪声。大量的实验证明,ControlNet可以使用单个或多个条件,有或没有prompt来有效地控制SD。在不同条件数据集上的实验结果表明,ControlNet结构适用于更广泛的条件,为相关应用提供了便利。

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









