







DENSE POINT PREDICTION: A SIMPLE BASELINE FOR CROWD COUNTING AND LOCALIZATION (论文阅读笔记)

文章出处:IEEE ICME Workshop,2021
摘要
在这篇文章中,作者提出了一个简单但是有效的人群计数和定位网络——SCALNet,与现有的将计数和定位任务分离的工作不同,作者将这些任务视为像素级密集预测问题,并将其集成到一个端到端框架中。
具体来说,对于人群计数,采用了由均方误差(MSE)损失监督的计数头。对于人群定位,关键是识别人的关键点,即头部的中心点,并提出了一个定位头来区分密集人群,其由两个损失函数训练得到,即Negative-Suppressed Focal (NSF) loss和False-Positive (FP) loss,它能够平衡正/负样本和处理假阳性预测。
在大规模基准NWPU-Crowd数据集上的实验表明,该方法在人群定位和计数任务上的性能分别比最先进的方法提高了5%和10%以上。
定位:


计数:


一、介绍
传统上,人群计数和定位被视为是两个独立的任务。
最先进的人群计数方法是基于回归网络的,它专注于回归计数,但忽略对象实例的位置。此类方法旨在预测密度图,其中的计数结果是通过对热图的积分计算得到的。基于检测的方法由于由于高度遮挡的群体导致召回率较低,影响了计数的性能。
针对密集人群的人群定位方法在近年来也得到了发展,这些方法可以对人群进行定位,并获得较好的计数结果。定位过程一般是在每个对象的头部产生关键点、斑点或边界框,总数通过置信阈值获得。
如表1所示,对于密度图预测的方法,计数结果是通过密度回归的方法获得,对于人群定位是对所获得的密度图进行进一步的后处理(如局部峰值选择和高斯先验重建,GPR);对于关键点、斑点、边界框预测的方法,计数结果依赖于置信度阈值的设定,人群定位取决于分类。

二、本文方法
2.1 网络结构
作者认为,人群定位问题是一个密集分类问题(即像素级二元分类),人群计数问题是一个密集回归问题,网络架构如图2所示。
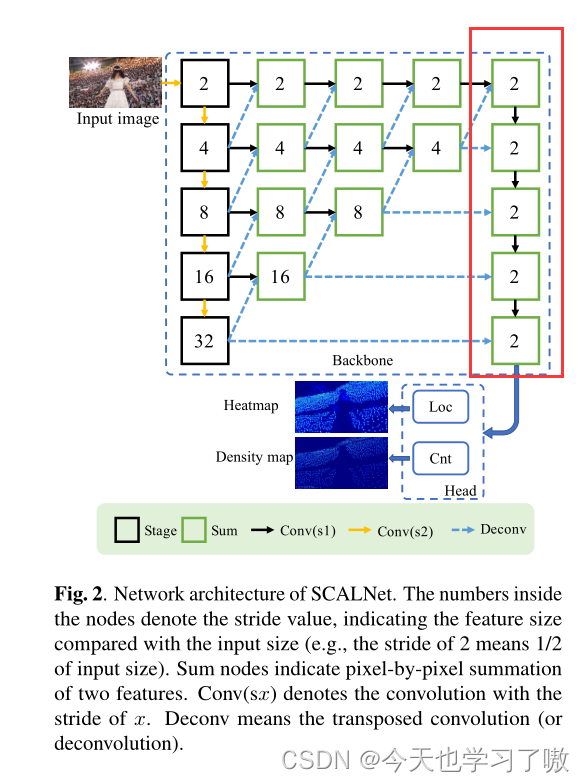
a.主干网络
作者采用了Centernet中的DLANet-34作为主干网络,并进行了修改,Centernet用到的主干特征网络有多种,一般是以 Hourglass Network、DLANet 或者 ResNet 为主干特征用来提取特征。
主干网络为32到2跨越式的多尺度特征提供了一种分期融合方式。小规模特征与大规模特征逐渐融合,使得语义信息与空间信息融合。作者在融合步骤中利用2步特征来保留更多的空间信息,而不是原来的4步DLA-34,如图2中网络的顶部行所示。最后,将不同级别的特征通过反卷积层和卷积层聚合为2stride特征,如图2网络右列红色框所示。这种修改通过增加一点推断时间显著提高了定位能力。
b.定位头网络(LHN)
由于人群是密集分布的,在一幅图像中,两个头部之间的距离可能小于几个像素。为了区分这些头部,LHN应该输出全分辨率的热图。具体来说,热图大小设置为与输入相同。
其结构为:
Dconv反卷积层(k4-s2)-Conv(k3-s1)-BN-ReLU-Conv(k1-s1)-Sigmoid
c.计数头网络(CHN)
CHN的目的是通过回归生成密度图。密度图可以积累拥挤物体的密度值,因此低分辨率的地图可以满足计数任务。具体地说,CHN由骨干网的输出特征提供,生成一个2步幅的密度图。
其结构为:
Conv(k3-s1)-PReLU-Conv(k1-s1)-PReLU
d.推理
在整个网络的前向传递过程中,输出的热图包含了人头的估计。头部存在于热图的高置信点(峰)中,从图2中可以看到热图中有尖锐的峰,显示了良好的定位能力。采用3×3局部极大值操作滤除峰值周围的噪声点,并通过置信阈值选择峰值作为头的估计。阈值通过搜索一个置信区间[0.3,0.5]得到,其中所选阈值在验证集上的定位性能最佳。头的位置由峰的坐标得到。从计数头网络中,通过简单地将输出密度图上的所有密度值相加就可以得到总数。
2.2 监督
a.定位监督
根据点标注文件,作者将点图上的每个像素值初始化为0,表示负标签。同时,根据头部的坐标将像素值设置为1,代表正标签,用于生成热图。高斯核被放置在头部位置,以平滑正标签周围的监督。选择两个高斯核重叠时的最大值。高斯核函数定义为:
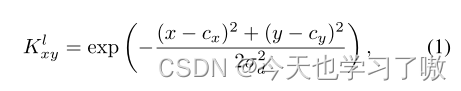

b.计数监督
生成真实标签的密度图作为计数监督,归一化高斯核函数定义为:
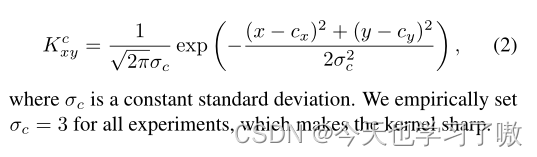
2.3 损失函数
a.定位损失
采用像素级分类损失。损失需要处理训练样本的不平衡和复杂的背景。首先,正样本的数量比负样本的数量(背景)少得多。在1080×1080图片中有1000名行人的情况下,正负之比约为1:1000。这种不平衡给训练过程带来了挑战。其次,复杂的背景可能导致许多假阳性头部检测。
针对这些问题,作者建议利用两个互补的损失函数,即负抑制焦点(NSF)损失和假阳性(FP)损失,以稳定训练过程。
NSF损失采用带负样本抑制的交叉熵损失:

然而,NFS损失是对负样本的整体抑制,但由于复杂的背景,假阳性峰值仍然出现在热图中。因此,作者提出FP缺失来强调假阳性检测。
根据真值热图和预测热图(分别用H和ˆH表示)找到假阳性区域。背景区域定义为:
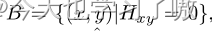
预测热图的正样本区域定义为:
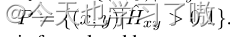
因此,假阳性的样本为:
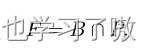
FP loss定义为 :

b.回归损失
采用MSE损失进行密度图回归。
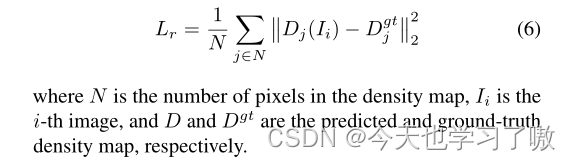
c.总的损失函数

三、实验结果
3.1 实验设置
a.数据集
NWPU-Crowd:5109张图片和超过2000个人头,既有点标注也有框标注
训练集:验证集:测试集 = 3109:500:1500
b.评价标准
- 对于人群定位:计算精度(Pre.)、召回率(Rec.)和F1-measure (F1-m.)
- 对于人群计数:平均绝对误差(MAE)、均方根误差(MSE)和平均归一化绝对误差(NAE)
c.实验细节
网络由ImageNet上预先训练好的DLA-34权值进行初始化。
优化器:Adam
Epoch:180
学习率:1e-4,并在第135轮开始衰减10倍
batch size:32
图像的长边若大于1600,我们将其缩小到1600像素
数据增强:随机水平翻转、随机裁剪(320×320)和归一化
实验设备:3080Ti
3.2 实验对比
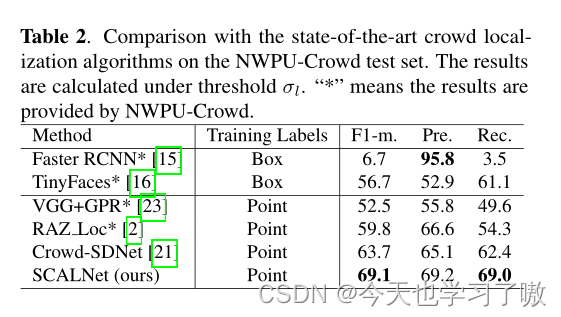
a.人群定位
通过使用点训练标签,该方法在F1-measure和Recall方面取得了最好的性能。与最近的方法crowdsdnet相比,F1-measure和Recall提高了5%以上。虽然Faster RCNN获得了最好的Precision,但是它的F1-measure和Recall非常低,这意味着Faster RCNN能够精确的检测到大规模的人,但是在密集的人群中效果并不好。

b.人群计数
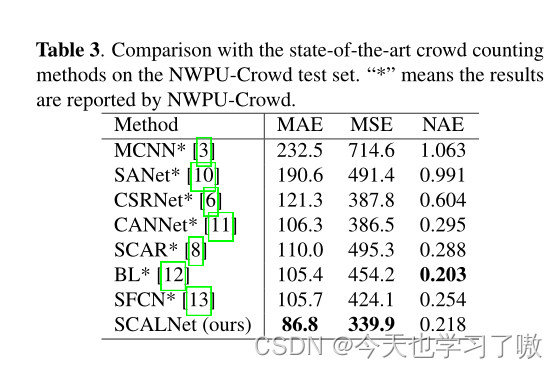
3.3 消融实验
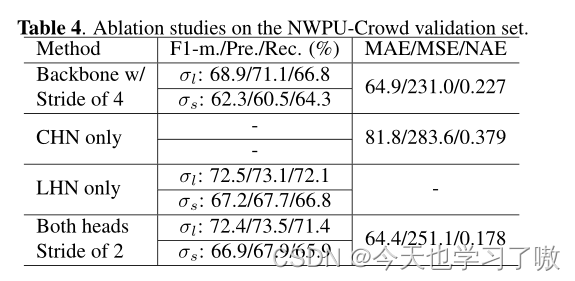
a.主干网络取步长为2
主干网络改变了DLA-34从4 (S4)步幅到2 (S2)。这种修改可以保留更多的空间信息,有利于小而拥挤的目标检测。从表4的第1项和第4项可以看出,在阈值σl和σs下,修正后使f1测度分别提高了3.5%和4.6%,此外,S4和S2的推理时间分别为每幅图像25ms和29ms(边长1600像素),这意味着这样的修改只增加了少量的推理时间(4ms)。
b.计数头和定位头网络
作者分别测试了计数头和定位头网络的有效性。仅使用CHN(见第2项),与使用两个头部的模型相比,人群计数误差显著增加(见第4项),这说明定位头部为计数任务提供了互补特征,减少了误差(例如,MAE从81.8下降到64.4)。此外,仅LHN的定位性能(见第3项)与两个头的定位性能都存在竞争,这表明计数头对定位任务的影响很小。
通过比较第2、3、4项,可以得出结论,将CHN和LHN集成到一个端到端密集预测网络中,同时执行这两项任务,不仅保留了定位性能,而且能提高计数能力。
四、结论
这篇文章提出了一种用于人群计数和定位的密集点预测方法,该模型采用了简单而有效的改进DLA、计数和定位头网络以及相应的损失函数,与目前最先进的方法相比,取得了优异的性能。同时,作者还提出了一个有价值的探讨:研究图像感知或物体阈值来选择预测的关键点,而不是简单的阈值过程。















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









