









flink1.12.0学习笔记第1篇-部署与入门
flink1.12.0学习笔记第2篇-流批一体API
flink1.12.0学习笔记第3篇-高级API
flink1.12.0学习笔记第4篇-Table与SQL
flink1.12.0学习笔记第5篇-业务案例实践
flink1.12.0学习笔记第6篇-高级特性与新特性
flink1.12.0学习笔记第7篇-监控与优化
7-1-Flink-Metrics
1.Metrics介绍
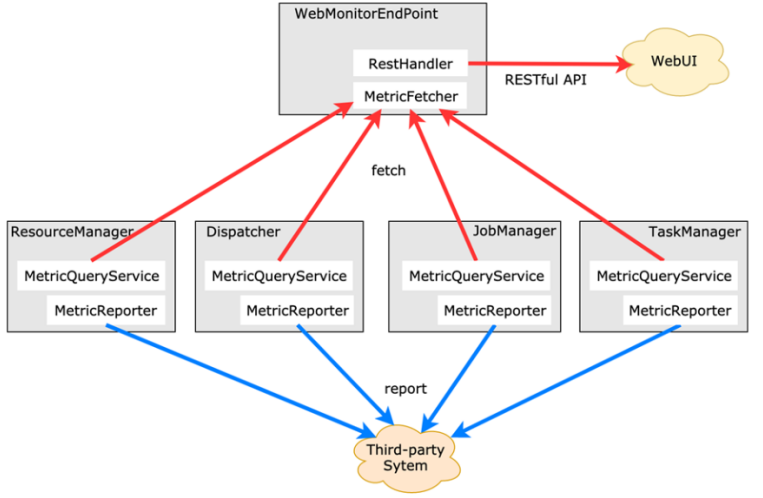
由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志,比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态
2.Metric Types
Metrics 的类型如下:
- 常用的如 Counter,雷同mapreduce 的Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。
- Gauge,Gauge 是最简单的 Metrics,它反映一个值。比如要看现在 Java heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是heap使用的量。
- Meter,Meter 是指统计吞吐量和单位时间内发生“事件”的次数。它相当于求一种速率,即事件次数除以使用的时间。
- Histogram,Histogram 比较复杂,也并不常用,Histogram 用于统计一些数据的分布,比如说 Quantile、Mean、StdDev、Max、Min 等。
Metric 在 Flink 内部有多层结构,以 Group 的方式组织,它并不是一个扁平化的结构,Metric Group + Metric Name 是 Metrics 的唯一标识。
3.WebUI监控
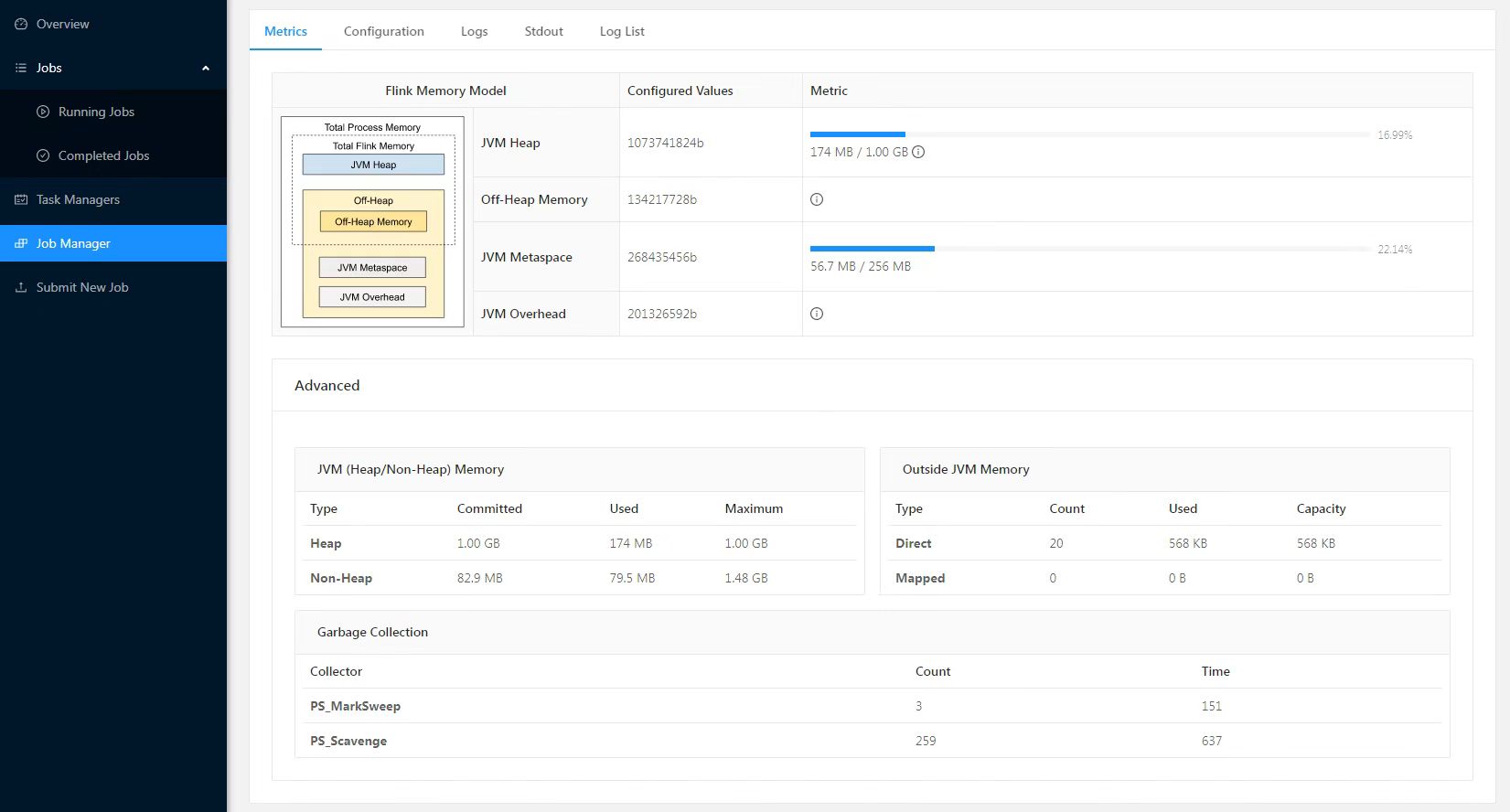
在flink的UI的界面上点击任务详情,然后点击Task Metrics可以看到各类监控指标
7-2-Flink-性能优化
1.History Server
flink的HistoryServer主要是用来存储和查看任务的历史记录
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
# 将已完成的作业上传到的目录
jobmanager.archive.fs.dir: hdfs://ops01:8020/completed-jobs/
# The address under which the web-based HistoryServer listens.
# 基于 Web 的 HistoryServer 的地址
historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
# 基于 Web 的 HistoryServer 的端口号
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
# 以逗号分隔的目录列表,用于监视已完成的作业
historyserver.archive.fs.dir: hdfs://ops01:8020/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
# 刷新受监控目录的时间间隔(以毫秒为单位)
historyserver.archive.fs.refresh-interval: 10000
- 参数释义
- jobmanager.archive.fs.dir:flink job运行完成后的日志存放目录
- historyserver.archive.fs.dir:flink history进程的hdfs监控目录
- historyserver.web.address:flink history进程所在的主机
- historyserver.web.port:flink history进程的占用端口
- historyserver.archive.fs.refresh-interval:刷新受监视目录的时间间隔(以毫秒为单位)。
- 默认启动端口8082:
- bin/historyserver.sh (start|start-foreground|stop)
2.序列化
- Java 原生的序列化方式
优点:好处是比较简单通用,只要对象实现了 Serializable 接口即可;
缺点:效率比较低,而且如果用户没有指定 serialVersionUID的话,很容易出现作业重新编译后,之前的数据无法反序列化出来的情况(这也是 Spark Streaming Checkpoint 的一个痛点,在业务使用中经常出现修改了代码之后,无法从 Checkpoint 恢复的问题)
对于分布式计算来讲,数据的传输效率非常重要。好的序列化框架可以通过较低的序列化时间和较低的内存占用大大提高计算效率和作业稳定性
- Flink 和 Spark 的序列化方式
Spark 对于所有数据默认采用 Java 原生序列化方式,用户也可以配置使用 Kryo;相比于 Java 原生序列化方式,无论是在序列化效率还是序列化结果的内存占用上,Kryo 则更好一些(Spark 声称一般 Kryo 会比 Java 原生节省 10x 内存占用);Spark 文档中表示它们之所以没有把 Kryo 设置为默认序列化框架的唯一原因是因为 Kryo 需要用户自己注册需要序列化的类,并且建议用户通过配置开启 Kryo。
Flink 则是自己实现了一套高效率的序列化方法
3.数据倾斜
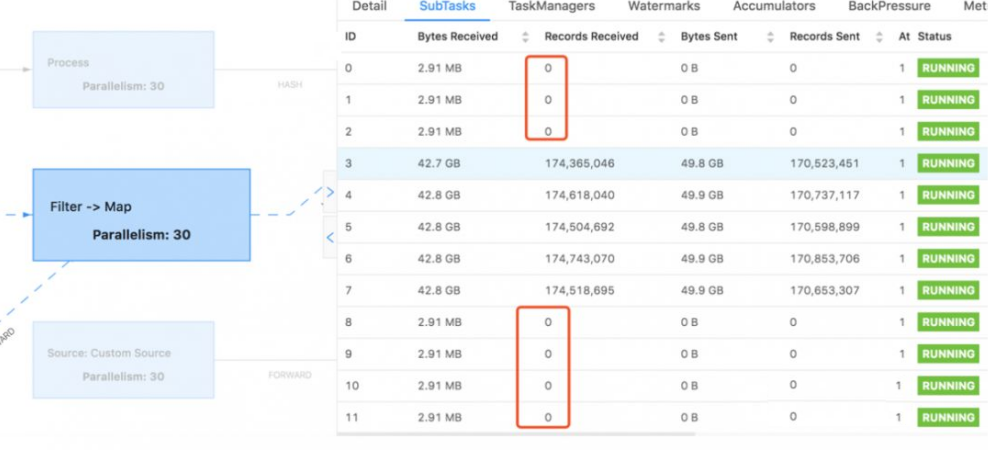
flink程序中如果使用了keyBy等分组的操作,很容易就出现数据倾斜的情况,数据倾斜会导致整体计算速度变慢,有些子节点甚至接受不到数据,导致分配的资源根本没有利用上
-
带有窗口的操作
○ 带有窗口的每个窗口中所有数据的分布不平均,某个窗口处理数据量太大导致速率慢
○ 导致Source数据处理过程越来越慢
○ 再导致所有窗口处理越来越慢
-
不带有窗口的操作
-
有些子节点接受处理的数据很少,甚至得不到数据,导致分配的资源根本没有利用上
-
WebUI体现
- 优化方式
- 对key进行均匀的打散处理(hash,加盐等)
- 自定义分区器
- 使用Rebalabce
注意:Rebalance是在数据倾斜的情况下使用,不倾斜不要使用,否则会因为shuffle产生大量的网络开销
7-3-Flink-内存管理
1.内存问题背景
Flink本身基本是以Java语言完成的,理论上说,直接使用JVM的虚拟机的内存管理就应该更简单方便,但Flink还是单独抽象出了自己的内存管理
因为Flink是为大数据而产生的,而大数据使用会消耗大量的内存,而JVM的内存管理管理设计是兼顾平衡的,不可能单独为了大数据而修改,这对于Flink来说,非常的不灵活,而且频繁GC会导致长时间的机器暂停应用,这对于大数据的应用场景来说也是无法忍受的。
JVM在大数据环境下存在的问题:
-
Java 对象存储密度低。在HotSpot JVM中,每个对象占用的内存空间必须是8的倍数,那么一个只包含 boolean 属性的对象就要占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上我们只想让它占用1个bit。
-
在处理大量数据尤其是几十甚至上百G的内存应用时会生成大量对象,Java GC可能会被反复触发,其中Full GC或Major GC的开销是非常大的,GC 会达到秒级甚至分钟级。
-
OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
2.内存划分
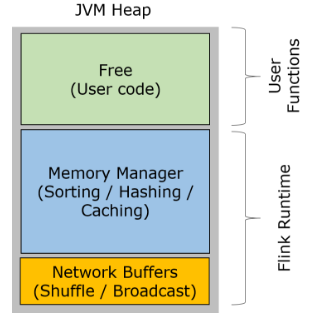
Flink的内存管理是在JVM的基础之上,自己进行的管理,但是还没有逃脱的JVM
-
网络缓冲区Network Buffers:这个是在TaskManager启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是32K,默认分配2048个,可以通过“taskmanager.network.numberOfBuffers”修改
-
内存池Memory Manage pool:大量的Memory Segment块,用于运行时的算法(Sort/Join/Shufflt等),这部分启动的时候就会分配。默认情况下,占堆内存的70% 的大小。
-
用户使用内存Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager的数据使用的。
3.堆外内存
除了JVM之上封装的内存管理,还会有个一个很大的堆外内存,用来执行一些IO操作
启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。
使用堆外内存可以极大地减小堆内存(只需要分配Remaining Heap),使得 TaskManager 扩展到上百GB内存不是问题。
进行IO操作时,使用堆外内存(可以理解为使用操作系统内存)可以zero-copy,使用堆内JVM内存至少要复制一次(需要在操作系统和JVM直接进行拷贝)。
堆外内存在进程间是共享的。
Flink相对于Spark,堆外内存该用还是用, 堆内内存管理做了自己的封装,不受JVM的GC影响
4.序列化与反序列化
Flink除了对堆内内存做了封装之外,还实现了自己的序列化和反序列化机制
序列化与反序列化可以理解为编码与解码的过程。序列化以后的数据希望占用比较小的空间,而且数据能够被正确地反序列化出来。为了能正确反序列化,序列化时仅存储二进制数据本身肯定不够,需要增加一些辅助的描述信息。此处可以采用不同的策略,因而产生了很多不同的序列化方法。
Java本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。
Flink实现了自己的序列化框架,使用TypeInformation表示每种数据类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
TypeInformation 支持以下几种类型:
BasicTypeInfo: 任意Java 基本类型或 String 类型。
BasicArrayTypeInfo: 任意Java基本类型数组或 String 数组。
WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
GenericTypeInfo: 任意无法匹配之前几种类型的类。(除了该数据使用kyro序列化.上面的其他的都是用二进制)
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口(具有像C语言一样的操作内存空间的能力)写入MemorySegments。
Flink通过自己的序列化和反序列化,可以将数据进行高效的存储,不浪费内存空间
5.操纵二进制数据
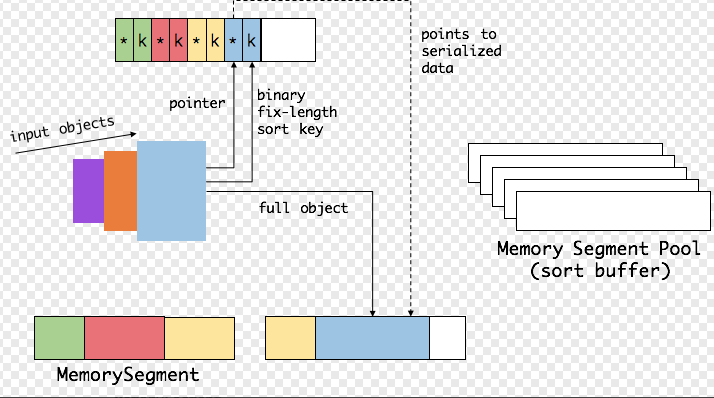
Flink中的group、sort、join 等操作可能需要访问海量数据。以sort为例
首先,Flink 会从 MemoryManager 中申请一批 MemorySegment,用来存放排序的数据
这些内存会分为两部分:
一个区域是用来存放所有对象完整的二进制数据。
另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。
将实际的数据和point+key分开存放有两个目的:
-
第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。
-
第二,这样做是缓存友好的,因为key都是连续存储在内存中的,可以增加cache命中。 排序会先比较 key 大小,这样就可以直接用二进制的 key 比较而不需要反序列化出整个对象。访问排序后的数据,可以沿着排好序的key+pointer顺序访问,通过 pointer 找到对应的真实数据。
在交换过程中,只需要比较key就可以完成sort的过程,只有key1 == key2的情况,才需要反序列化拿出实际的对象做比较,而比较之后只需要交换对应的key而不需要交换实际的对象
7-4-Flink与Spark全方位对比
1.运行角色
Spark Streaming
Spark Streaming 运行时的角色(standalone 模式)主要有
-
Master
- 主要负责整体集群资源的管理和应用程序调度
-
Worker
- 负责单个节点的资源管理,driver 和 executor 的启动等
-
Driver
- 用户入口程序执行的地方,即 SparkContext 执行的地方,主要是 DAG 生成、stage 划分、task 生成及调度
-
Executor
- 负责执行 task,反馈执行状态和执行结果
Flink
Flink 运行时的角色(standalone 模式)主要有:
-
Jobmanager
- 协调分布式执行,他们调度任务、协调 checkpoints、协调故障恢复等。至少有一个 JobManager。高可用情况下可以启动多个 JobManager,其中一个选举为 leader,其余为 standby
-
Taskmanager
- 负责执行具体的 tasks、缓存、交换数据流,至少有一个 TaskManager
-
Slot
- 每个 task slot 代表 TaskManager 的一个固定部分资源,Slot 的个数代表着 taskmanager 可并行执行的 task 数
2.生态
- spark

- flink
3.运行模型
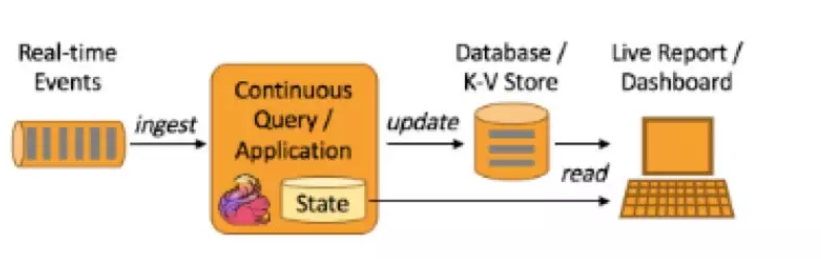
Spark Streaming 是微批处理,运行的时候需要指定批处理的时间,每次运行 job 时处理一个批次的数据
流程如图所示:

Flink 是基于事件驱动的,事件可以理解为消息。事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入事件,通过触发计算更新状态,或外部动作对注入的事件作出反应。
4.编程模型对比
编程模型对比,主要是对比 flink 和 Spark Streaming 两者在代码编写上的区别
- Spark Streaming
Spark Streaming 与 kafka 的结合主要是两种模型:
基于 receiver dstream;
基于 direct dstream。
以上两种模型编程机构近似,只是在 api 和内部数据获取有些区别,新版本的已经取消了基于 receiver 这种模式,企业中通常采用基于 direct Dstream 的模式
val Array(brokers, topics) = args// 创建一个批处理时间是2s的context
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// 使用broker和topic创建DirectStream
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print() // 启动流
ssc.start()
ssc.awaitTermination()
通过以上代码我们可以 get 到:
设置批处理时间
创建数据流
编写transform
编写action
启动执行
- Flink
Flink 与 kafka 结合是事件驱动,大家可能对此会有疑问,消费 kafka 的数据调用 poll 的时候是批量获取数据的(可以设置批处理大小和超时时间),这就不能叫做事件触发了。而实际上,flink 内部对 poll 出来的数据进行了整理,然后逐条 emit,形成了事件触发的机制。
下面的代码是 flink 整合 kafka 作为 data source 和 data sink:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableSysoutLogging();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
// create a checkpoint every 5 seconds
env.enableCheckpointing(5000);
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(parameterTool);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// ExecutionConfig.GlobalJobParameters
env.getConfig().setGlobalJobParameters(null);
DataStream<KafkaEvent> input = env
.addSource(new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-topic"), new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.setParallelism(1).rebalance()
.keyBy("word")
.map(new RollingAdditionMapper()).setParallelism(0);
input.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("output-topic"), new KafkaEventSchema(),
parameterTool.getProperties()));
env.execute("Kafka 0.10 Example");
从 Flink 与 kafka 结合的代码可以 get 到:
注册数据 source
编写运行逻辑
注册数据 sink
调用 env.execute
相比于 Spark Streaming 少了设置批处理时间,还有一个显著的区别是 flink 的所有算子都是 lazy 形式的,调用 env.execute 会构建 jobgraph。client 端负责 Jobgraph 生成并提交它到集群运行;而 Spark Streaming的操作算子分 action 和 transform,其中仅有 transform 是 lazy 形式,而且 DGA 生成、stage 划分、任务调度是在 driver 端进行的,在 client 模式下 driver 运行于客户端处。
5.时间机制对比
- 流处理的时间
- 处理时间
- 事件时间
- 注入时间
处理时间
处理时间是指每台机器的系统时间,当流程序采用处理时间时将使用运行各个运算符实例的机器时间。处理时间是最简单的时间概念,不需要流和机器之间的协调,它能提供最好的性能和最低延迟。然而在分布式和异步环境中,处理时间不能提供消息事件的时序性保证,因为它受到消息传输延迟,消息在算子之间流动的速度等方面制约
事件时间
事件时间是指事件在其设备上发生的时间,这个时间在事件进入 flink 之前已经嵌入事件,然后 flink 可以提取该时间。基于事件时间进行处理的流程序可以保证事件在处理的时候的顺序性,但是基于事件时间的应用程序必须要结合 watermark 机制。基于事件时间的处理往往有一定的滞后性,因为它需要等待后续事件和处理无序事件,对于时间敏感的应用使用的时候要慎重考虑
注入时间
注入时间是事件注入到 flink 的时间。事件在 source 算子处获取 source 的当前时间作为事件注入时间,后续的基于时间的处理算子会使用该时间处理数据。
相比于事件时间,注入时间不能够处理无序事件或者滞后事件,但是应用程序无序指定如何生成 watermark。在内部注入时间程序的处理和事件时间类似,但是时间戳分配和 watermark 生成都是自动的
- Spark 时间机制
Spark Streaming 只支持处理时间,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据
- Flink 时间机制
flink 支持三种时间机制:事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。
flink1.12.0学习笔记第1篇-部署与入门
flink1.12.0学习笔记第2篇-流批一体API
flink1.12.0学习笔记第3篇-高级API
flink1.12.0学习笔记第4篇-Table与SQL
flink1.12.0学习笔记第5篇-业务案例实践
flink1.12.0学习笔记第6篇-高级特性与新特性
flink1.12.0学习笔记第7篇-监控与优化
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











