









flink1.12.0学习笔记第1篇-部署与入门
flink1.12.0学习笔记第2篇-流批一体API
flink1.12.0学习笔记第3篇-高级API
flink1.12.0学习笔记第4篇-Table与SQL
flink1.12.0学习笔记第5篇-业务案例实践
flink1.12.0学习笔记第6篇-高级特性与新特性
flink1.12.0学习笔记第7篇-监控与优化
6-1.BroadcastState
1.BroadcastState介绍
在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有 task 时,就可以使用 Broadcast State。Broadcast State 是 Flink 1.5 引入的新特性。
下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到另一个数据流的计算中
场景举例
-
动态更新计算规则: 如事件流需要根据最新的规则进行计算,则可将规则作为广播状态广播到下游Task中。
-
实时增加额外字段: 如事件流需要实时增加用户的基础信息,则可将用户的基础信息作为广播状态广播到下游Task中。
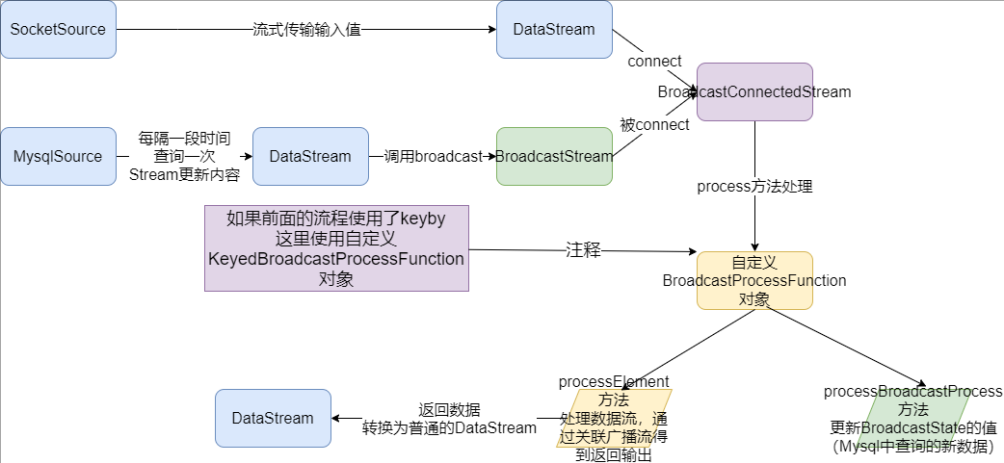
API介绍
-
首先创建一个Keyed 或Non-Keyed 的DataStream,
-
然后再创建一个BroadcastedStream,
-
最后通过DataStream来连接(调用connect 方法)到Broadcasted Stream 上,
这样实现将BroadcastState广播到Data Stream 下游的每个Task中
1.如果DataStream是Keyed Stream ,则连接到Broadcasted Stream 后, 添加处理ProcessFunction 时需要使用KeyedBroadcastProcessFunction 来实现, 下面是KeyedBroadcastProcessFunction 的API
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
上面泛型中的各个参数的含义,说明如下:
KS:表示Flink 程序从最上游的Source Operator 开始构建Stream,当调用keyBy 时所依赖的Key 的类型;
IN1:表示非Broadcast 的Data Stream 中的数据记录的类型;
IN2:表示Broadcast Stream 中的数据记录的类型;
OUT:表示经过KeyedBroadcastProcessFunction 的processElement()和processBroadcastElement()方法处理后输出结果数据记录的类型。
2.如果Data Stream 是Non-Keyed Stream,则连接到Broadcasted Stream 后,添加处理ProcessFunction 时需要使用BroadcastProcessFunction 来实现, 下面是BroadcastProcessFunction 的API
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
上面泛型中的各个参数的含义,与前面KeyedBroadcastProcessFunction 的泛型类型中的后3 个含义相同,只是没有调用keyBy 操作对原始Stream 进行分区操作,就不需要KS 泛型参数。
具体如何使用上面的BroadcastProcessFunction,接下来我们会在通过实际编程,来以使用KeyedBroadcastProcessFunction 为例进行详细说明
注意事项
Broadcast State 是Map 类型,即K-V 类型。
Broadcast State 只有在广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processBroadcastElement 方法中可以修改。在非广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processElement 方法中只读。
Broadcast State 中元素的顺序,在各Task 中可能不同。基于顺序的处理,需要注意。
Broadcast State 在Checkpoint 时,每个Task 都会Checkpoint 广播状态。
Broadcast State 在运行时保存在内存中,目前还不能保存在RocksDB State Backend 中。
2.实现配置动态更新示例
需求
- 实时过滤出配置中的用户,并在事件流中补全这批用户的基础信息
- 事件流:表示用户在某个时刻浏览或点击了某个商品,格式如下
{
"userID": "user_3",
"eventTime": "2022-10-01 12:19:47",
"eventType": "browse",
"productID": 1
}
{
"userID": "user_2",
"eventTime": "2022-10-01 12:19:48",
"eventType": "click",
"productID": 1
}
- 配置数据: 表示用户的详细信息,在Mysql中
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
SET FOREIGN_KEY_CHECKS = 1;
MariaDB [bigdata]> select * from user_info;
+--------+----------+---------+
| userID | userName | userAge |
+--------+----------+---------+
| user_1 | 张三 | 10 |
| user_2 | 李四 | 20 |
| user_3 | 王五 | 30 |
| user_4 | 赵六 | 40 |
+--------+----------+---------+
4 rows in set (0.000 sec)
- 预期输出结果:
(user_3,2019-08-17 12:19:47,browse,1,王五,33)
(user_2,2019-08-17 12:19:48,click,1,李四,20)
实现步骤
- env
- source
- 构建实时数据事件流-自定义随机
<userID, eventTime, eventType, productID> - 构建配置流-从MySQL
<用户id,<姓名,年龄>>
- transformation
-
定义状态描述器
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>(“config”,Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT))); -
广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor); -
将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS); -
处理连接后的流-根据配置流补全事件流中的用户的信息
- sink
- execute
代码示例
package cn.wangting;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple6;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Author itcast
* Desc
*/
public class BroadcastStateDemo {
public static void main(String[] args) throws Exception {
//TODO 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//TODO 2.source
DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource());
DataStreamSource<Map<String, Tuple2<String, Integer>>> userDS = env.addSource(new MySQLSource());
//TODO 3.transformation
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>("info", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = userDS.broadcast(descriptor);
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS = eventDS.connect(broadcastDS);
SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result =
connectDS.process(new BroadcastProcessFunction<
Tuple4<String, String, String, Integer>,
Map<String, Tuple2<String, Integer>>,
Tuple6<String, String, String, Integer, String, Integer>
>() {
@Override
public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);//广播流中的数据
if (map != null) {
String userId = value.f0;
Tuple2<String, Integer> tuple2 = map.get(userId);
String username = tuple2.f0;
Integer age = tuple2.f1;
out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, username, age));
}
}
@Override
public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
broadcastState.clear();
broadcastState.put(null, value);
}
});
//TODO 4.sink
result.print();
//TODO 5.execute
env.execute();
}
public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, Integer>> ctx) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while (isRunning) {
int id = random.nextInt(4) + 1;
String user_id = "user_" + id;
String eventTime = df.format(new Date());
String eventType = "type_" + random.nextInt(3);
int productId = random.nextInt(4);
ctx.collect(Tuple4.of(user_id, eventTime, eventType, productId));
Thread.sleep(500);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
public static class MySQLSource extends RichSourceFunction<Map<String, Tuple2<String, Integer>>> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://ops01:3306/bigdata", "root", "123456");
String sql = "select `userID`, `userName`, `userAge` from `user_info`";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Map<String, Tuple2<String, Integer>>> ctx) throws Exception {
while (flag) {
Map<String, Tuple2<String, Integer>> map = new HashMap<>();
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String userID = rs.getString("userID");
String userName = rs.getString("userName");
int userAge = rs.getInt("userAge");
map.put(userID, Tuple2.of(userName, userAge));
}
ctx.collect(map);
Thread.sleep(5000);
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
if (conn != null) conn.close();
if (ps != null) ps.close();
if (rs != null) rs.close();
}
}
}
控制台输出:
(user_2,2022-09-29 16:38:37,type_1,3,李四,20)
(user_1,2022-09-29 16:38:37,type_0,2,张三,10)
(user_3,2022-09-29 16:38:38,type_1,2,王五,30)
(user_2,2022-09-29 16:38:38,type_1,0,李四,20)
(user_4,2022-09-29 16:38:39,type_0,1,赵六,40)
(user_2,2022-09-29 16:38:39,type_2,0,李四,20)
(user_1,2022-09-29 16:38:40,type_2,1,张三,10)
(user_4,2022-09-29 16:38:40,type_0,2,赵六,40)
(user_1,2022-09-29 16:38:41,type_1,3,张三,10)
(user_1,2022-09-29 16:38:42,type_1,1,张三,10)
(user_4,2022-09-29 16:38:42,type_2,1,赵六,40)
(user_2,2022-09-29 16:38:43,type_0,3,李四,20)
(user_2,2022-09-29 16:38:43,type_0,2,李四,20)
(user_2,2022-09-29 16:38:44,type_0,3,李四,20)
(user_2,2022-09-29 16:38:44,type_2,2,李四,20)
(user_2,2022-09-29 16:38:45,type_2,2,李四,20)
(user_2,2022-09-29 16:38:45,type_0,0,李四,20)
修改MySQL数据
update user_info set userage = 100 where userID = 'user_1';
update user_info set userage = 200 where userID = 'user_2';
回到控制台查看输出变化:
(user_3,2022-09-29 16:41:00,type_2,0,王五,30)
(user_1,2022-09-29 16:41:00,type_0,2,张三,100)
(user_4,2022-09-29 16:41:01,type_2,3,赵六,40)
(user_1,2022-09-29 16:41:01,type_1,3,张三,100)
(user_3,2022-09-29 16:41:02,type_0,0,王五,30)
(user_3,2022-09-29 16:41:02,type_1,0,王五,30)
(user_3,2022-09-29 16:41:03,type_2,2,王五,30)
(user_1,2022-09-29 16:41:03,type_2,0,张三,100)
(user_2,2022-09-29 16:41:04,type_0,0,李四,200)
(user_3,2022-09-29 16:41:04,type_0,0,王五,30)
(user_2,2022-09-29 16:41:05,type_2,1,李四,200)
(user_4,2022-09-29 16:41:05,type_2,1,赵六,40)
6-2.双流Join
1.双流join介绍
在实时处理中,事实数据(Event)源源不断地流入到Kafka中,这些事实数据可能是来自于网页中的用户访问日志、也有可能是MySQL中进行操作的binlog日志,但基本上可以确认的是,在这个事件流中,不是所有的数据都是完整的。绝大多数场景,原始日志数据需要和外部存储系统中的一些数据进行关联之后,才能得到更完整的数据
Join大体分类只有两种:Window Join和Interval Join。
- Window Join又可以根据Window的类型细分出3种:
- Tumbling Window Join
- Sliding Window Join
- Session Widnow Join。
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
- interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
目前Stream join的结果是数据的笛卡尔积;
2.window join
Tumbling Window Join
执行翻滚窗口联接时,具有公共键和公共翻滚窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。因为它的行为类似于内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射!
如图所示,我们定义了一个大小为2毫秒的翻滚窗口,结果窗口的形式为[0,1]、[2,3]、。。。。该图显示了每个窗口中所有元素的成对组合,这些元素将传递给JoinFunction。注意,在翻滚窗口[6,7]中没有发射任何东西,因为绿色流中不存在与橙色元素⑥和⑦结合的元素

实现代码块
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
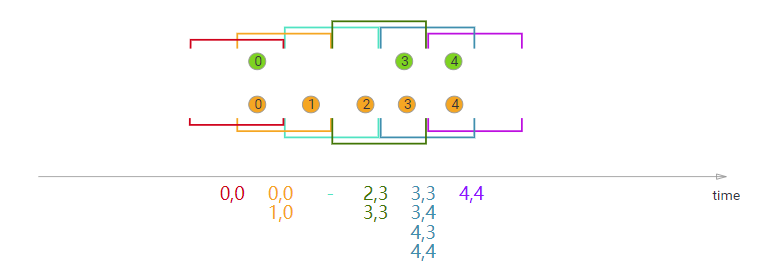
Sliding Window Join
在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。在当前滑动窗口中,一个流的元素没有来自另一个流的元素,则不会发射!而某些元素可能会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中!
在本例中,我们使用大小为2毫秒的滑动窗口,并将其滑动1毫秒,从而产生滑动窗口[-1,0],[0,1],[1,2],[2,3]…。x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素。在这里,您还可以看到,例如,在窗口[2,3]中,橙色②与绿色③连接,但在窗口[1,2]中没有与任何对象连接。
代码示例:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
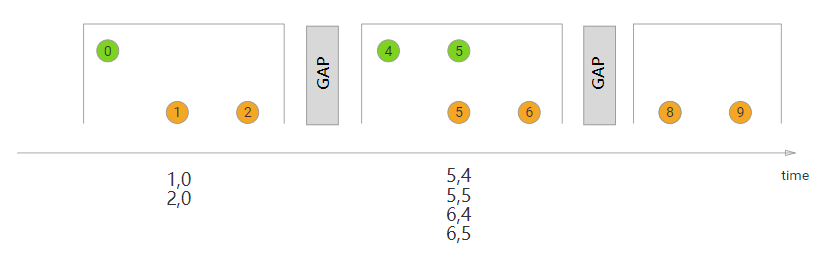
Session Window Join
在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联接,并传递给JoinFunction或FlatJoinFunction。同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何输出。
在这里,我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分割。有三个会话,在前两个会话中,来自两个流的连接元素被传递给JoinFunction。在第三个会话中,绿色流中没有元素,所以⑧和⑨没有连接!
代码示例:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
3.interval join
Window Join必须要在一个Window中进行JOIN,那如果没有Window如何处理呢?
interval join也是使用相同的key来join两个流(流A、流B),
并且流B中的元素中的时间戳,和流A元素的时间戳,有一个时间间隔。
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
or
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
也就是:
流B的元素的时间戳 ≥ 流A的元素时间戳 + 下界,且,流B的元素的时间戳 ≤ 流A的元素时间戳 + 上界。
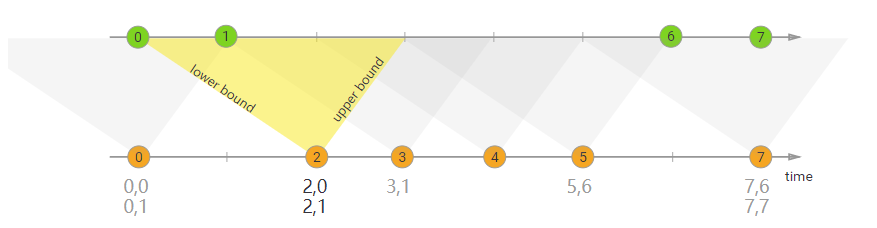
在上面的示例中,我们将两个流“orange”和“green”连接起来,其下限为-2毫秒,上限为+1毫秒。默认情况下,这些边界是包含的,但是可以应用.lowerBoundExclusive()和.upperBoundExclusive来更改行为
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
代码示例
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
6-3.End-to-End Exactly-Once
流处理的数据处理语义
对于批处理,fault-tolerant(容错性)很容易做,失败只需要replay,就可以完美做到容错。
对于流处理,数据流本身是动态,没有所谓的开始或结束,虽然可以replay buffer的部分数据,但fault-tolerant做起来会复杂的多
流处理(有时称为事件处理)可以简单地描述为是对无界数据或事件的连续处理。流或事件处理应用程序可以或多或少地被描述为有向图,并且通常被描述为有向无环图(DAG)。在这样的图中,每个边表示数据或事件流,每个顶点表示运算符,会使用程序中定义的逻辑处理来自相邻边的数据或事件。有两种特殊类型的顶点,通常称为 sources 和 sinks。sources读取外部数据/事件到应用程序中,而 sinks 通常会收集应用程序生成的结果。下图是流式应用程序的示例。有如下特点:
分布式情况下是由多个Source(读取数据)节点、多个Operator(数据处理)节点、多个Sink(输出)节点构成
每个节点的并行数可以有差异,且每个节点都有可能发生故障
对于数据正确性最重要的一点,就是当发生故障时,是怎样容错与恢复的
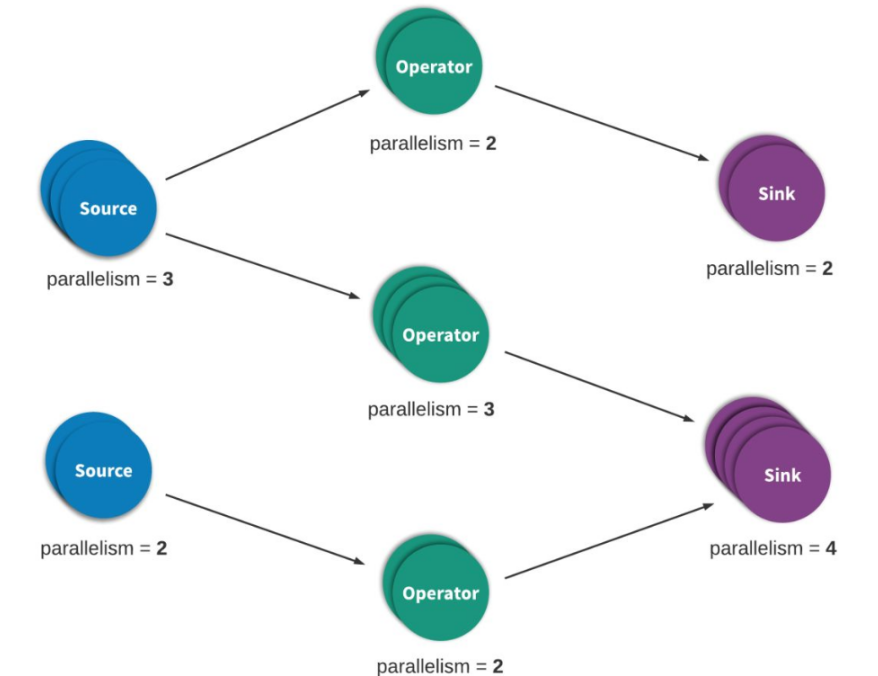
流处理引擎通常为应用程序提供了三种数据处理语义:最多一次、至少一次和精确一次。
如下是对这些不同处理语义的宽松定义(一致性由弱到强):
At most noce < At least once < Exactly once < End to End Exactly once
At-most-once-最多一次
有可能会有数据丢失
这本质上是简单的恢复方式,也就是直接从失败处的下个数据开始恢复程序,之前的失败数据处理就不管了。可以保证数据或事件最多由应用程序中的所有算子处理一次。 这意味着如果数据在被流应用程序完全处理之前发生丢失,则不会进行其他重试或者重新发送。

At-least-once-至少一次
有可能重复处理数据
应用程序中的所有算子都保证数据或事件至少被处理一次。这通常意味着如果事件在流应用程序完全处理之前丢失,则将从源头重放或重新传输事件。然而,由于事件是可以被重传的,因此一个事件有时会被处理多次(至少一次),至于有没有重复数据,不会关心,所以这种场景需要人工干预自己处理重复数据
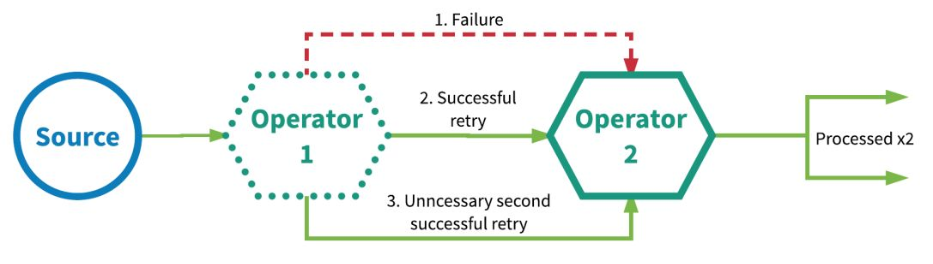
Exactly-once-精确一次
Exactly-Once 是 Flink、Spark 等流处理系统的核心特性之一,这种语义会保证每一条消息只被流处理系统处理一次。即使是在各种故障的情况下,流应用程序中的所有算子都保证事件只会被『精确一次』的处理。(也有文章将 Exactly-once 翻译为:完全一次,恰好一次)
Flink实现『精确一次』的分布式快照/状态检查点方法受到 Chandy-Lamport 分布式快照算法的启发。通过这种机制,流应用程序中每个算子的所有状态都会定期做 checkpoint。如果是在系统中的任何地方发生失败,每个算子的所有状态都回滚到最新的全局一致 checkpoint 点。在回滚期间,将暂停所有处理。源也会重置为与最近 checkpoint 相对应的正确偏移量。整个流应用程序基本上是回到最近一次的一致状态,然后程序可以从该状态重新启动。
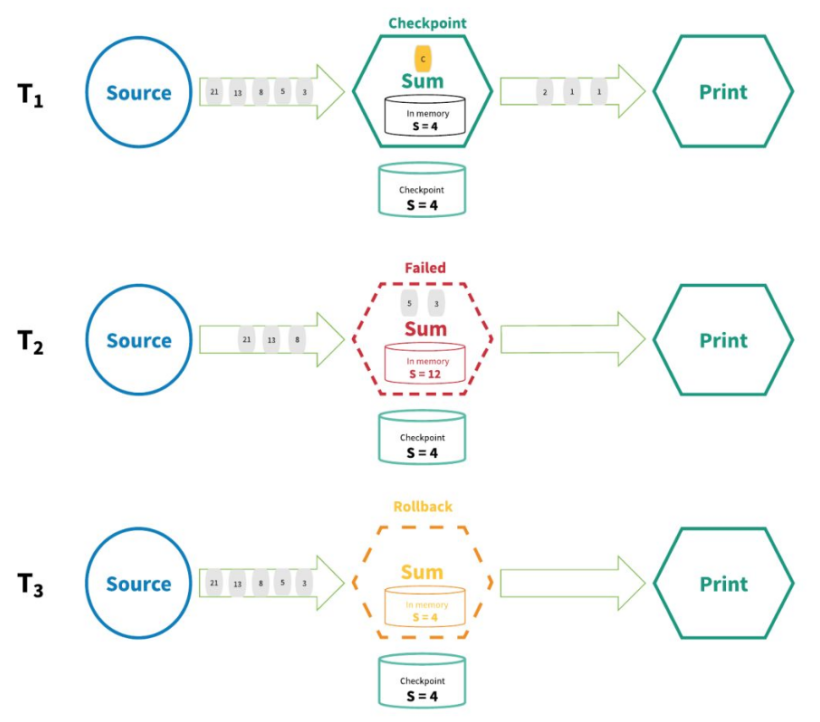
End-to-End Exactly-Once-端到端的精确一次
指的是 Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点。
注意:
『exactly-once』和『End-to-End Exactly-Once』的区别:
- exactly-once
- 保证所有记录仅影响内部状态一次
- End-to-End Exactly-Once
- 保证所有记录仅影响内部喝外部状态一次
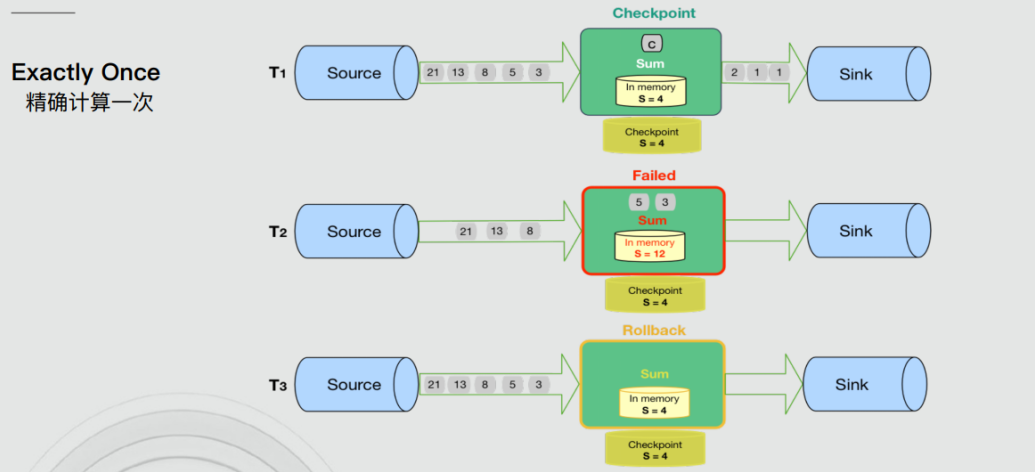
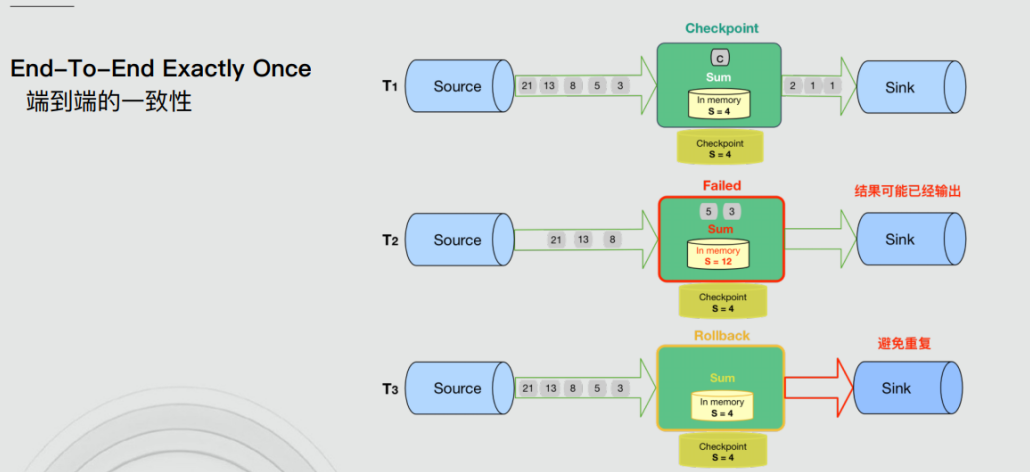
精确一次与有效一次
有些人可能认为『精确一次』描述了事件处理的保证,其中流中的每个事件只被处理一次。实际上,没有引擎能够保证正好只处理一次。在面对任意故障时,不可能保证每个算子中的用户定义逻辑在每个事件中只执行一次,因为用户代码被部分执行的可能性是永远存在的。
那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储。
事件的处理可以发生多次,但是该处理的效果只在持久后端状态存储中反映一次。因此,我们认为有效地描述这些处理语义最好的术语是『有效一次』(effectively once)
End-to-End Exactly-Once的实现
Flink内部借助分布式快照Checkpoint已经实现了内部的Exactly-Once,但是Flink 自身是无法保证外部其他系统“精确一次”语义的,所以 Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;然后借助一些其他手段才能实现
Source
发生故障时需要支持重设数据的读取位置,如Kafka可以通过offset来实现(其他的没有offset系统,我们可以自己实现累加器计数)
Transformation
也就是Flink内部,已经通过Checkpoint保证了,如果发生故障或出错时,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般
分布式快照机制
Flink 提供了失败恢复的容错机制,而这个容错机制的核心就是持续创建分布式数据流的快照来实现
同 Spark 相比,Spark 仅仅是针对 Driver 的故障恢复 Checkpoint。而 Flink 的快照可以到算子级别,并且对全局数据也可以做快照。Flink 的分布式快照受到 Chandy-Lamport 分布式快照算法启发,同时进行了量身定做
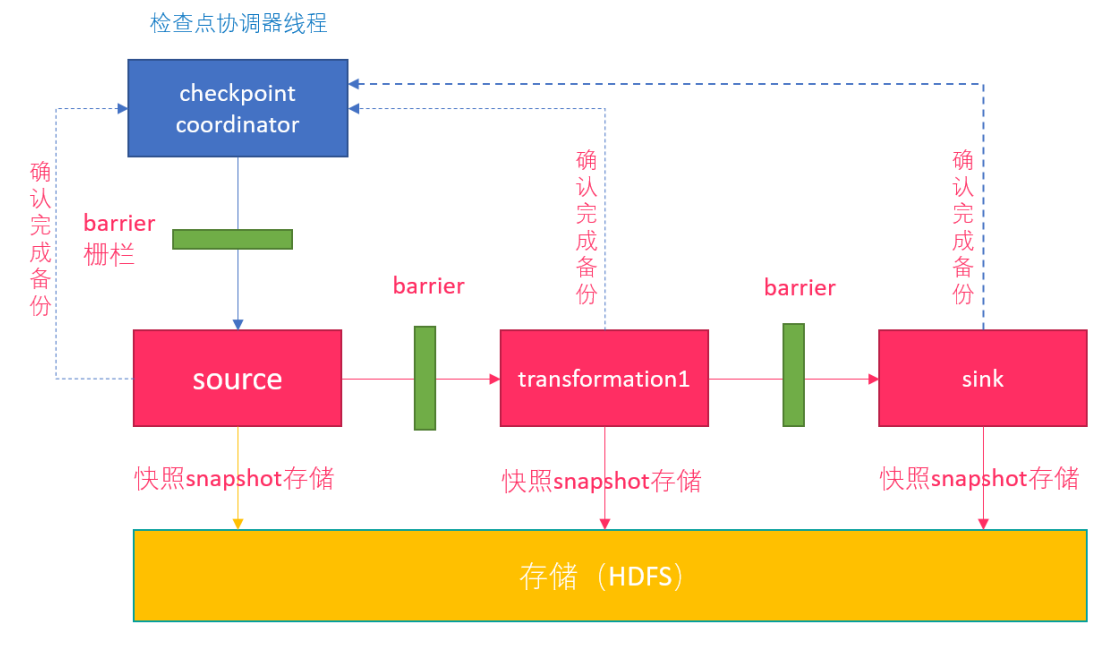
Barrier
Flink 分布式快照的核心元素之一是 Barrier(数据栅栏),我们也可以把 Barrier 简单地理解成一个标记,该标记是严格有序的,并且随着数据流往下流动。每个 Barrier 都带有自己的 ID,Barrier 极其轻量,并不会干扰正常的数据处理

Barrier 会随着正常数据继续往下流动,每当遇到一个算子,算子会插入一个标识,这个标识的插入时间是上游所有的输入流都接收到 snapshot n。与此同时,当我们的 sink 算子接收到所有上游流发送的 Barrier 时,那么就表明这一批数据处理完毕,Flink 会向“协调者”发送确认消息,表明当前的 snapshot n 完成了。当所有的 sink 算子都确认这批数据成功处理后,那么本次的 snapshot 被标识为完成
这里就会有一个问题,因为 Flink 运行在分布式环境中,一个 operator 的上游会有很多流,每个流的 barrier n 到达的时间不一致怎么办?这里 Flink 采取的措施是:快流等慢流

上图的 barrier n 来说,其中一个流到的早,其他的流到的比较晚。当第一个 barrier n到来后,当前的 operator 会继续等待其他流的 barrier n。直到所有的barrier n 到来后,operator 才会把所有的数据向下发送
异步和增量
按照上面我们介绍的机制,每次在把快照存储到我们的状态后端时,如果是同步进行就会阻塞正常任务,从而引入延迟。因此 Flink 在做快照存储时,可采用异步方式。
此外,由于 checkpoint 是一个全局状态,用户保存的状态可能非常大,多数达 G 或者 T 级别。在这种情况下,checkpoint 的创建会非常慢,而且执行时占用的资源也比较多,因此 Flink 提出了增量快照的概念。也就是说,每次都是进行的全量 checkpoint,是基于上次进行更新的
Sink
幂等写入(Idempotent Writes)
幂等写操作是指:任意多次向一个系统写入数据,只对目标系统产生一次结果影响。
例如,重复向一个HashMap里插入同一个Key-Value二元对,第一次插入时这个HashMap发生变化,后续的插入操作不会改变HashMap的结果,这就是一个幂等写操作。
HBase、Redis和Cassandra这样的KV数据库一般经常用来作为Sink,用以实现端到端的Exactly-Once。
需要注意的是,并不是说一个KV数据库就百分百支持幂等写。幂等写对KV对有要求,那就是Key-Value必须是可确定性(Deterministic)计算的。假如我们设计的Key是:name + curTimestamp,每次执行数据重发时,生成的Key都不相同,会产生多次结果,整个操作不是幂等的。因此,为了追求端到端的Exactly-Once,我们设计业务逻辑时要尽量使用确定性的计算逻辑和数据模型
事务写入(Transactional Writes)
Flink借鉴了数据库中的事务处理技术,同时结合自身的Checkpoint机制来保证Sink只对外部输出产生一次影响。大致的流程如下:
Flink先将待输出的数据保存下来暂时不向外部系统提交,等到Checkpoint结束时,Flink上下游所有算子的数据都是一致的时候,Flink将之前保存的数据全部提交(Commit)到外部系统。换句话说,只有经过Checkpoint确认的数据才向外部系统写入。
如下图所示,如果使用事务写,那只把时间戳3之前的输出提交到外部系统,时间戳3以后的数据(例如时间戳5和8生成的数据)暂时保存下来,等待下次Checkpoint时一起写入到外部系统。这就避免了时间戳5这个数据产生多次结果,多次写入到外部系统
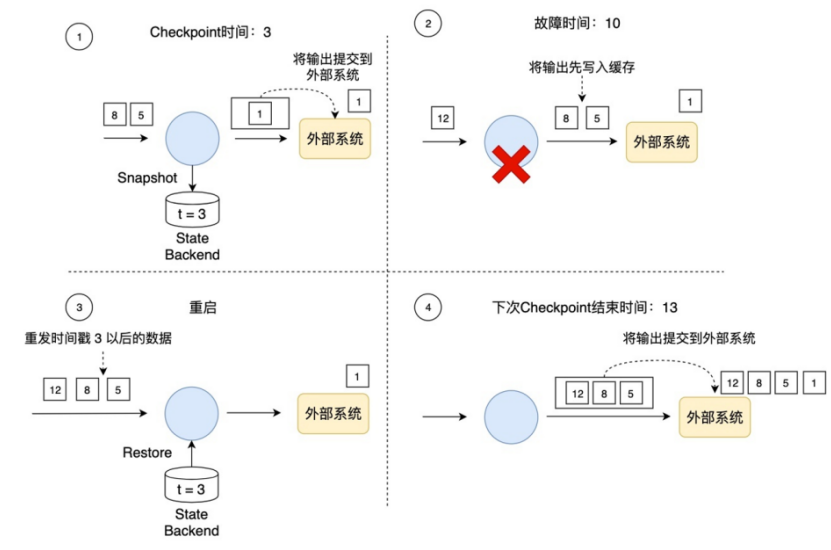
在事务写的具体实现上,Flink目前提供了两种方式:
-
预写日志(Write-Ahead-Log,WAL)
-
两阶段提交(Two-Phase-Commit,2PC)
这两种方式区别主要在于:
-
WAL方式通用性更强,适合几乎所有外部系统,但也不能提供百分百端到端的Exactly-Once,因为WAL预习日志会先写内存,而内存是易失介质。
-
如果外部系统自身就支持事务(比如MySQL、Kafka),可以使用2PC方式,可以提供百分百端到端的Exactly-Once。
事务写的方式能提供端到端的Exactly-Once一致性,它的代价也是非常明显的,就是牺牲了延迟。输出数据不再是实时写入到外部系统,而是分批次地提交。目前来说,没有完美的故障恢复和Exactly-Once保障机制,对于开发者来说,需要在不同需求之间权衡
6-4.异步IO
1.异步IO操作的需求
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,于1.2版本引入。主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
流计算系统中经常需要与外部系统进行交互,我们通常的做法如向数据库发送用户a的查询请求,然后等待结果返回,在这之前,我们的程序无法发送用户b的查询请求。这是一种同步访问方式,如下图所示
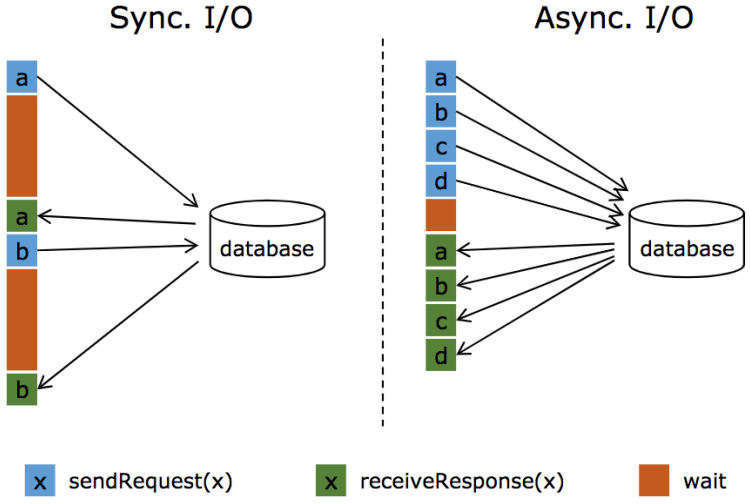
- 左图所示:通常实现方式是向数据库发送用户a的查询请求(例如在MapFunction中),然后等待结果返回,在这之前,我们无法发送用户b的查询请求,这是一种同步访问的模式,图中棕色的长条标识等待时间,可以发现网络等待时间极大的阻碍了吞吐和延迟
- 右图所示:为了解决同步访问的问题,异步模式可以并发的处理多个请求和回复,可以连续的向数据库发送用户a、b、c、d等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,这也正是Async I/O的实现原理。
2.使用Aysnc I/O的前提条件
-
数据库(或key/value存储系统)提供支持异步请求的client。(如java的vertx)
-
没有异步请求客户端的话也可以将同步客户端丢到线程池中执行作为异步客户端
3.Async I/O API
Async I/O API允许用户在数据流中使用异步客户端访问外部存储,该API处理与数据流的集成,以及消息顺序性(Order),事件时间(EventTime),一致性(容错)等脏活累活,用户只专注于业务
如果目标数据库中有异步客户端,则三步即可实现异步流式转换操作(针对该数据库的异步):
-
实现用来分发请求的AsyncFunction,用来向数据库发送异步请求并设置回调
-
获取操作结果的callback,并将它提交给ResultFuture
-
将异步I/O操作应用于DataStream
6-5.Streaming File Sink
1.场景描述
StreamingFileSink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
StreamingFileSink就可以用来将分区文件写入到支持Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下
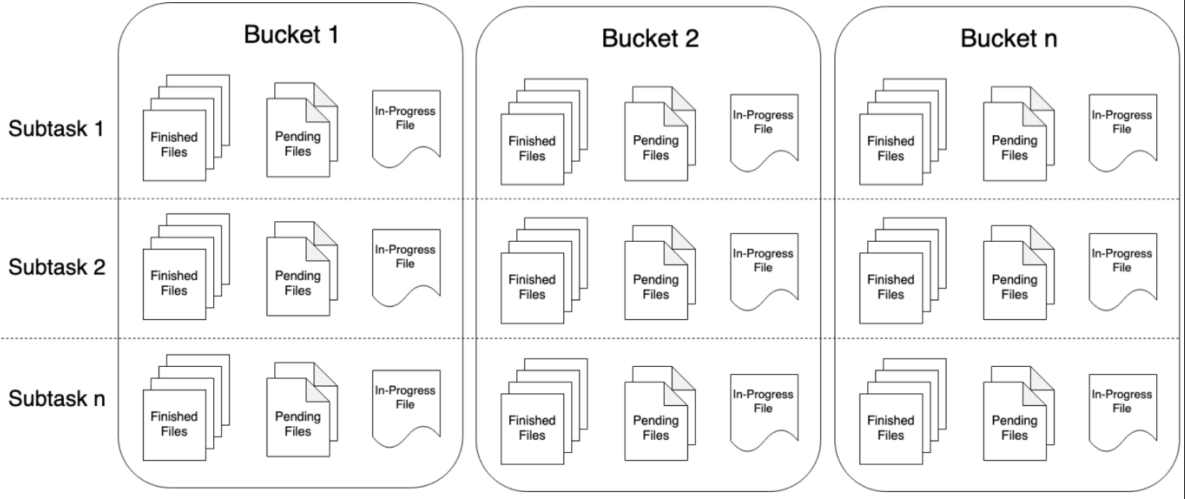
2.Bucket和SubTask、PartFile
Bucket
StreamingFileSink可向由Flink FileSystem抽象支持的文件系统写入分区文件(因为是流式写入,数据被视为无界)。该分区行为可配,默认按时间,具体来说每小时写入一个Bucket,该Bucket包括若干文件,内容是这一小时间隔内流中收到的所有record
PartFile
每个Bukcket内部分为多个PartFile来存储输出数据,该Bucket生命周期内接收到数据的sink的每个子任务至少有一个PartFile。
而额外文件滚动由可配的滚动策略决定,默认策略是根据文件大小和打开超时(文件可以被打开的最大持续时间)以及文件最大不活动超时等决定是否滚动。
Bucket和SubTask、PartFile关系如图所示
6-6.File Sink
新的 Data Sink API,之前发布的 Flink 版本中[1],已经支持了 source connector 工作在流批两种模式下,因此在 Flink 1.12 中,社区着重实现了统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 协议和一个更加模块化的接口。Sink 的实现者只需要定义 what 和 how:SinkWriter,用于写数据,并输出需要 commit 的内容(例如,committables);Committer 和 GlobalCommitter,封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。
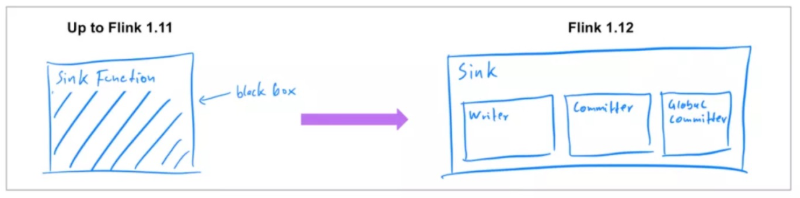
这种模块化的抽象允许为 BATCH 和 STREAMING 两种执行模式,实现不同的运行时策略,以达到仅使用一种 sink 实现,也可以使两种模式都可以高效执行。Flink 1.12 中,提供了统一的 FileSink connector,以替换现有的 StreamingFileSink connector (FLINK-19758)。其它的 connector 也将逐步迁移到新的接口。
Flink 1.12的 FileSink 为批处理和流式处理提供了一个统一的接收器,它将分区文件写入Flink文件系统抽象所支持的文件系统。这个文件系统连接器为批处理和流式处理提供了相同的保证,它是现有流式文件接收器的一种改进。
6-7.FlinkSQL整合Hive
1.集成hive的基本方式
Flink 与 Hive 的集成主要体现在以下两个方面:
- 持久化元数据
Flink利用 Hive 的 MetaStore 作为持久化的 Catalog,我们可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。例如,我们可以使用HiveCatalog将其 Kafka的数据源表存储在 Hive Metastore 中,这样该表的元数据信息会被持久化到Hive的MetaStore对应的元数据库中,在后续的 SQL 查询中,我们可以重复使用它们。 - 利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive表。不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
2.hive使用准备
1.需要下载相关的依赖jar并上传至flink/lib目录
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
找到对应版本号对应jar包下载
2.修改hive配置文件 hive-site.xml ( hive/conf/hive-site.xml )
增加元数据支持配置
<property>
<name>hive.metastore.uris</name>
<value>thrift://ops01:9083</value>
</property>
3.启动hive元数据服务
nohup $HIVE_HOME/bin/hive --service metastore &
3.SQL CLI
- 修改flinksql配置
vim /opt/flink/conf/sql-client-defaults.yaml
catalogs:
- name: myhive
type: hive
hive-conf-dir: /opt/module/hive/conf
default-database: default
- 启动flink集群
/opt/flink/bin/start-cluster.sh
- 启动flink-sql客户端
/opt/flink/bin/sql-client.sh embedded
- 执行sql
show catalogs;
use catalog myhive;
show tables;
select * from person;
4.java 代码示例
package cn.wangting;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class HiveDemo {
public static void main(String[] args){
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "./conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//注册catalog
tableEnv.registerCatalog("myhive", hive);
//使用注册的catalog
tableEnv.useCatalog("myhive");
//向Hive表中写入数据
String insertSQL = "insert into person select * from person";
TableResult result = tableEnv.executeSql(insertSQL);
System.out.println(result.getJobClient().get().getJobStatus());
}
}
flink1.12.0学习笔记第1篇-部署与入门
flink1.12.0学习笔记第2篇-流批一体API
flink1.12.0学习笔记第3篇-高级API
flink1.12.0学习笔记第4篇-Table与SQL
flink1.12.0学习笔记第5篇-业务案例实践
flink1.12.0学习笔记第6篇-高级特性与新特性
flink1.12.0学习笔记第7篇-监控与优化
















 2013
2013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











