










Hudi之TimeLine(时间轴)原理概念
在Apache Hudi中,TimeLine是指一个有序的事件序列,用于跟踪数据湖Hudi中数据的变化历史。TimeLine是Hudi的核心概念之一,用于管理和维护数据湖Hudi中各个数据集的变化历史。具体来说,TimeLine由一系列时间戳(timestamp)和相关的操作事件(如写入、更新、删除)组成,这些事件按时间顺序排列。每个数据集都有自己的TimeLine,用于记录该数据集的变化历史。
通过TimeLine,用户可以追溯数据集的变化历史,了解数据是如何随着时间变化的。此外,TimeLine还支持快速的数据回滚、数据恢复等操作,使得数据管理变得更加灵活和可控。
Hudi 的核心是维护一个表上在不同的即时时间(称为 instants)执行的所有操作的时间轴。这意味着 Hudi 记录了表在不同时间点上所发生的所有操作,包括写入、更新、删除等操作。这个时间轴跟踪了表的变化历史,可以用于回溯、查询和分析数据的演变。
- TimeLine是一个有序的事件序列,记录了数据湖Hudi中数据集的变化历史,包括写入、更新、删除等操作
- 每个数据集都有自己的TimeLine,用于跟踪该数据集的变化情况
- TimeLine按时间顺序排列,可以看作是数据湖Hudi中数据变化历史的总体框架
1. Instant(瞬时)
Hudi中"instant"(即“瞬时”)是指一个确定的时间点,它代表了数据湖Hudi中的一个重要状态。每个数据集都有一个instant,用于标识该数据集的当前状态。
可以将instant理解为数据湖Hudi中的一个快照点,表示在这个时间点之前所有的数据写入、更新、删除操作都已经完成,并且数据集的状态已经固定。通过instant,用户可以了解数据集在特定时间点的状态,从而进行数据查询、分析或者回滚操作。此外,instant还具有可重放性的特点,即可以根据instant来重放数据集的变化历史,以实现数据恢复或者时间旅行式的数据分析。
- Instant代表了数据湖Hudi中的一个确定时间点,用于标识数据集的当前状态。
- 每个Instant都与TimeLine中的某个事件相关联,表示该事件发生的时间点。
- Instant可以理解为数据湖Hudi中的一个重要里程碑,用于标记数据集的状态。
- 用户可以通过Instant来访问数据湖Hudi中的特定时间点的数据状态,从而进行查询、分析或者回滚操作。
1-1. Instant Action(瞬时操作)
可以将 Instant Action(瞬时操作)比喻为在数据湖Hudi中发生的各种动作或事件,这个部分涵盖了操作类型,即Instant所关联的具体操作,比如写入(INSERT)、更新(UPSERT)、删除(DELETE)等等。
写入(INSERT):就像在游戏中创建一个新的角色或保存游戏进度一样,写入操作表示在数据湖Hudi中添加新的数据。
更新(UPSERT):类似于在游戏中更新已有角色的属性或状态,更新操作表示对现有数据进行修改或更新。
删除(DELETE):就像在游戏中删除不需要的角色或清除某些数据一样,删除操作表示从数据湖Hudi中移除不再需要的数据。
提交(COMMIT):类似于在游戏中保存当前游戏进度或确认一项任务已经完成,提交操作表示确认对数据的修改已经完成,并将其应用到数据湖Hudi中。
合并(MERGE):就像在游戏中合并不同分支的剧情或合并不同的资源一样,合并操作表示将不同的数据文件或数据集合并为一个更大的整体。
- Instant Action 相关概念:
create(创建):表示对数据湖Hudi中的数据集执行了创建操作,即在数据湖Hudi中新建了一个数据集。
commit(提交):表示对数据集执行了提交操作,即提交了一批数据的写入操作,使其成为可查询和可见的状态。
delta_commit(增量提交):指示对增量数据集执行了提交操作,即对增量数据集进行了提交,使得新增的数据可见。
compaction(合并):表示对数据集执行了合并操作,即将数据集中的多个数据文件合并为较少数量的文件,以优化数据集的存储和查询性能。
clean(清理):表示对数据集执行了清理操作,即删除了数据集中满足某些条件的数据,以减少数据集的大小或清理过期数据。
rollback(回滚):表示对数据集执行了回滚操作,即将数据集恢复到之前的某个状态,通常是撤销了之前的操作。
savepoint(保存点):表示对数据集执行了保存点操作,即在某个时间点创建了数据集的保存点,以便后续可以回滚到该时间点的状态。
merge_on_read(读时合并):表示对增量数据集执行了读时合并操作,即在查询时动态合并增量数据,以获取完整的视图。
1-2. Instant Time(瞬时时间)
可以将 Instant Time(瞬时时间)比喻为时间轴上的一个具体时间点,表示Instant发生的时间戳,是Instant的时间维度,确定了Instant所代表的状态的确切时间点
- Instant Time 相关概念:
写入时间(Write Time):表示数据被写入数据湖Hudi的时间。对于新增数据,写入时间即为数据写入的时间;对于更新数据,写入时间可能是数据最后一次更新的时间。
提交时间(Commit Time):表示提交操作发生的时间点,即数据集的状态被提交或者变更的时间点。
合并时间(Merge Time):表示合并操作发生的时间点,即执行数据文件合并操作的时间。
清理时间(Cleanup Time):表示数据清理操作发生的时间点,即执行数据清理操作的时间。
回滚时间(Rollback Time):表示回滚操作发生的时间点,即数据集被回滚到之前的某个状态的时间点。
保存点时间(Savepoint Time):表示创建保存点的时间点,即在数据集的特定状态下创建保存点的时间。
查询时间(Query Time):表示查询操作发生的时间点,即对数据集进行查询的时间。
数据生效时间(Effective Time):表示数据生效或可见的时间点,即数据在数据湖Hudi中变得可查询和可见的时间。
1-3. Instant Action与Instant Time对比理解
Instant Action(瞬时操作):描述了具体的操作类型,即对数据集执行了什么样的操作,比如写入、提交、合并等。这些操作类型直接反映了对数据集的具体处理和变更。
Instant Time(瞬时时间):描述了操作发生的时间点,即某个操作何时发生。它是以时间戳的形式表示的,反映了操作发生的确切时间。
Instant Action更侧重于操作的类型和性质,而Instant Time更关注操作发生的时间点。在分析数据湖Hudi的操作历史和状态变化时,这两个概念通常是相辅相成的,一起使用可以提供更全面和准确的信息。
比如玩一款角色扮演游戏,我们可以将 Instant Time 和 Instant Action 结合起来直观形象对比
Instant Time 的比喻:
- Instant Time 就像在游戏中的进度条所显示的时间。例如,当开始游戏时,Instant Time 是游戏开始的时间点;当完成某个任务时,Instant Time 是任务完成的时间点;当退出游戏时,Instant Time 是游戏结束的时间点。
Instant Action 的比喻:
- 当你创建一个新的游戏角色时(INSERT 操作),这就是一个 Instant Action,表示在游戏世界中添加了一个新的角色。
- 当你升级了你的角色(UPDATE 操作),这也是一个 Instant Action,表示在游戏中更新了你的角色等级和属性。
- 当你完成了一项任务(COMMIT 操作),这是另一个 Instant Action,表示在游戏中提交了任务并保存了游戏进度。
- 当你删除了一些不再需要的物品或任务(DELETE 操作),这也是一个 Instant Action,表示在游戏中删除了一些数据,比如清理背包中的多余物品。
- 当游戏开发人员合并了一个新的游戏更新(MERGE 操作),这是另一个 Instant Action,表示在游戏中合并了新的内容和功能。
在数据湖Hudi中,Instant Action类似于发生的不同操作和事件,而Instant Time则类似于这些操作和事件发生的时间点
1-4. Timeline 操作
- 创建时间轴(Timeline)
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.table.timeline.versioning.TimelineLayoutVersion;
import org.apache.hudi.common.table.timeline.versioning.TimelineLayoutVersionWriter;
import org.apache.hudi.common.table.timeline.versioning.TimelineLayoutVersion.WrittenMetadata;
import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
import org.apache.hudi.common.table.view.FileSystemViewStorageConfig.DEFAULT_FILESYSTEM_VIEW_SPILLABLE_DIR;
// 创建时间轴
HoodieTimeline timeline = HoodieTimeline.createNewInstantTimeline();
- 添加 Instant 到时间轴
import org.apache.hudi.common.table.timeline.HoodieInstant;
import org.apache.hudi.common.table.timeline.TimelineMetadataUtils;
import org.apache.hudi.common.table.timeline.TimelineMetadataUtils.MetadataMergeWriteStatus;
import org.apache.hudi.common.table.timeline.TimelineMetadataUtils.MetadataUpdateFunction;
import org.apache.hudi.common.util.collection.Pair;
// 添加 Instant 到时间轴
HoodieInstant instant = new HoodieInstant(true, "commit", "1");
TimelineMetadataUtils.updateTimelineMetadata(timeline, instant.getTimestamp(), TimelineMetadataUtils.createMetadataWriteFunction(instant.getTimestamp(), (TimelineMetadataUtils.MetadataUpdateFunction<Pair<String, HoodieInstant>, MetadataMergeWriteStatus>) (timeline1, instant1) -> MetadataMergeWriteStatus.SuccessAndShouldUpdateMetadata(), instant), MetadataUpdateFunction.CREATE);
- 检索时间轴中的 Instant
import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.collection.ImmutablePair;
// 检索时间轴中的 Instant
Option<Pair<String, HoodieInstant>> instantOption = timeline.findInstantsBefore("commit").lastInstant();
if (instantOption.isPresent()) {
Pair<String, HoodieInstant> pair = instantOption.get();
System.out.println("Instant Type: " + pair.getRight().getAction());
System.out.println("Instant Timestamp: " + pair.getRight().getTimestamp());
}
2. State(状态)
State是Instant所代表的数据集在Instant Time时刻的具体状态。State包含了数据集的元数据、数据文件的信息、分区信息等,以描述数据集的当前状态。State是Instant Time(瞬时时间)时数据集的快照,描述了数据集在那个时间点的完整情况。
requested(请求中):表示某个操作已经被请求,但尚未执行。当用户发起一个数据操作请求时,操作会进入requested状态,等待后续执行。
inflight(进行中):表示某个操作正在执行过程中。一旦操作开始执行,它就会进入inflight状态,表示操作正在进行中,但尚未完成。
completed(已完成):表示某个操作已经成功完成。当操作执行成功并且达到预期的结果时,它将进入completed状态,表示操作已经顺利完成。
有一个笔记本用来记录每天的待办事项和笔记。这本笔记本就代表了数据集,而每一页就是数据集的一个State状态。
-
笔记本的每一页:每一页上都有不同的内容,比如日期、待办事项、笔记等。这些内容就代表了数据集在某个时间点的状态,也就是 State。
-
不同时间点的内容:当你打开笔记本的不同页时,你会看到不同的内容。这就像在不同的时间点查看数据集的状态,每一页都记录了某个时刻的数据状态。
-
状态的变化:随着时间的推移,你会不断记录新的待办事项和笔记,每页的内容会发生变化。这就是数据集状态的变化,也就是 State 的更新。
-
历史记录:整本笔记本就像是一个时间轴,记录了你的所有待办事项和笔记的历史。这就是数据集状态的历史记录,可以用来回溯查看过去的数据状态。
-
管理和查询:通过整理和管理笔记本的内容,你可以更好地组织和查询自己的信息。同样,通过管理和查询数据集的状态,你可以更好地理解和分析数据。
State一般包括主要内容:
数据文件(Data Files):数据文件是存储实际数据内容的文件,通常以 Parquet 或者其他列式存储格式存储。这些数据文件包含了数据集的实际记录和信息。
元数据(Metadata):元数据包含了关于数据文件的描述信息,比如文件路径、文件大小、数据记录数等。元数据还包括了关于数据集的其他信息,比如创建时间、修改时间、所有者信息等。
分区信息(Partition Information):如果数据集根据分区进行划分,State 存储还可能包括分区信息,描述每个分区的数据情况。分区信息可以帮助加速数据查询和过滤操作。
索引信息(Index Information):如果数据集有索引,State 存储可能还包括索引信息,描述索引的构建情况和内容。索引可以加速数据的检索和查询操作。
其他附加信息:除了上述主要部分之外,State 存储还可能包括其他附加信息,比如数据集的描述、标签、元数据统计等。
3. Arrival time 和 Event time
Apache Hudi 中,Arrival time 和 Event time 是两个重要的概念,用于处理数据湖Hudi中的数据,并且在数据管理和分析中起着关键的作用。
- Arrival time(到达时间):
- Arrival time 是指数据到达系统的时间。它表示数据被加载到数据湖Hudi中的时间点,通常是数据被写入数据湖Hudi的时间。在数据湖Hudi中,Arrival time 是指明数据进入系统的时间,反映了数据的实际到达时间。
- Event time(事件时间):
- Event time 是指数据代表的事件发生的时间。它表示数据所描述的事件或记录的时间,而不是数据被处理、加载或写入系统的时间。Event time 是数据自身所包含的时间信息,可以是事件发生的实际时间或者记录时间。
在 Apache Hudi 中,Arrival time 和 Event time 通常用于处理实时数据流或者批处理数据,并且用于数据的分区、排序、查询等操作。对于实时数据处理一般基于 Arrival time 进行操作,以确保及时处理新到达的数据;而对于分析查询,通常会基于 Event time 进行操作,以保证数据分析的准确性和一致性。
- Arrival time(到达时间) 可以被比喻为邮件抵达收件人所属的邮局时间。每当收到一封信件,你会查看邮戳上的时间,这个时间就是该信件的到达时间。Arrival time 表示的是信件到达邮局的实际时间。
- Event time(事件时间) 可以被比喻为信件上标注的信件发送时间。信件上发件人写明的时间,这个时间是信件代表的事件发生的时间。Event time 表示的是信件所描述的事件发生的时间。
举例来说:
- 如果一封信件标注的发送时间是2024年5月1日,但是由于邮局繁忙运力不足,这封信件直到5月10日才被收到。那么,Arrival time 是5月10日,而 Event time 是信件上标注的5月1日。
在数据处理中,类似于处理邮件,Arrival time 用于表示数据到达系统的时间,而 Event time 则表示数据本身所代表的事件发生的时间。
官方图例:
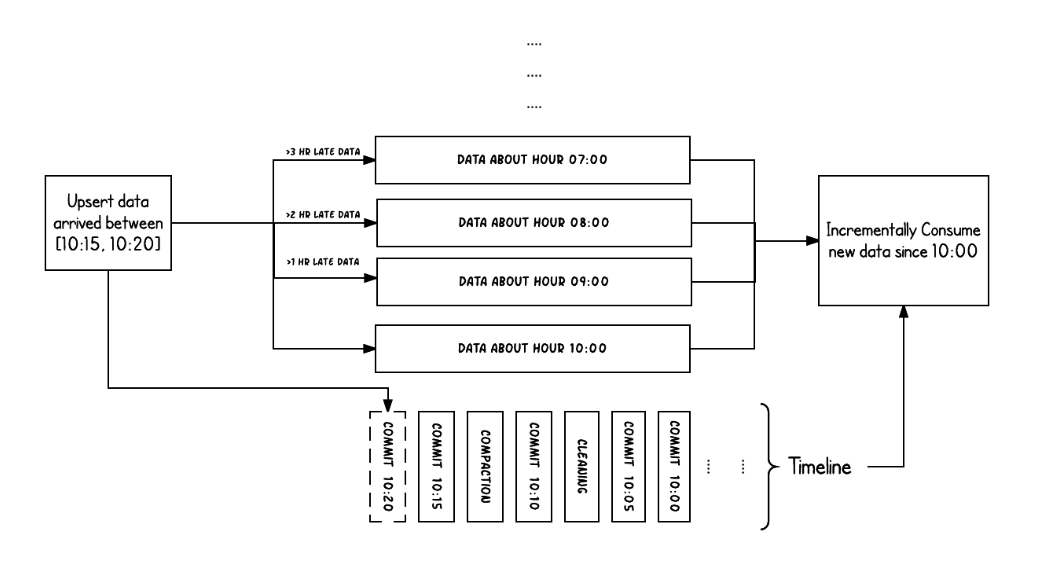
上面的例子显示了Hudi表在10:00到10:20之间发生的混乱,大约每5分钟发生一次,在Hudi时间线上留下提交元数据,以及其他后台清理/压缩。一个关键的观察结果是,提交时间表示数据的到达时间(上午10:20A),而实际数据组织反映了数据的实际时间或事件时间(从07:00开始的每小时一段)。在对数据的延迟和完整性之间的权衡进行推理时,这是两个关键概念。
当存在延迟到达的数据(预计9点到达的数据>10点20分延迟1小时)时,我们可以看到upstart将新数据生成到更旧的时间段/文件夹中。在时间线的帮助下,尝试获取自10:00以来成功提交的所有新数据的增量查询能够非常有效地仅使用更改的文件,而无需扫描所有时间段>07:00。
表示数据的到达时间(上午10:20A),而实际数据组织反映了数据的实际时间或事件时间(从07:00开始的每小时一段)。在对数据的延迟和完整性之间的权衡进行推理时,这是两个关键概念。
当存在延迟到达的数据(预计9点到达的数据>10点20分延迟1小时)时,我们可以看到upstart将新数据生成到更旧的时间段/文件夹中。在时间线的帮助下,尝试获取自10:00以来成功提交的所有新数据的增量查询能够非常有效地仅使用更改的文件,而无需扫描所有时间段>07:00。


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











