







#1. 简介
在Andrew Ng的机器学习教程里,会将给定的数据集分为三部分:训练数据集(training set)、交叉验证数据集(cross validation set)、测试数据集(test set)。三者分别占总数据集的60%、20%、20%。
那么这些数据集分别是什么作用呢?
#2. 三种数据集的作用
假设我们训练一个数据集,有下面10中模型可以选择:
(图片来自Coursera Machine Learning Andrew Ng 第6周:Model Selection and Train/Validation/Test Sets)
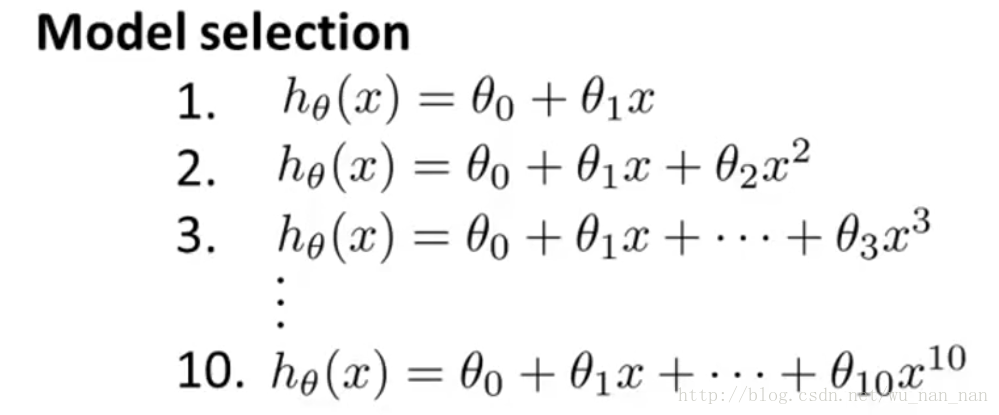
我们想知道两件事:
- 1)这10中模型中哪种最好(决定多项式的阶数d);
- 2)最好的模型的
θ
\theta
θ参数是什么。
为此,我们需要,
- 使用训练数据集分别训练这10个模型;
- 用训练好的这10个模型,分别处理交叉验证数据集,统计它们的误差,取误差最小的模型为最终模型(这步就叫做Model Selection)。
- 用测试数据集测试其准确性。
这里有个问题要回答:为什么不直接使用测试数据集(Test Set)来执行上面的第2.步?
答:如果数据集只分成训练数据集(Training Set)和测试数据集(Test Set),且训练数据集用于训练 θ \theta θ,测试数据集用于选择模型,那么就缺少能够“公平”评判最终模型优劣的数据集,因为最终的模型就是根据训练数据集和测试数据集训练得到的,肯定在这两个数据集上表现良好,但不一定在其他数据上也如此。















 7239
7239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









