







目录
3. Soft Labels and Unsupervised Loss
4. Exponential Moving Average for the Teacher Model Update
5. Teacher Ensemble with Horizontal Flipping
2. Extended weak-strong data augmentations
Humble Teacher
Humble Teachers Teach Better Students for Semi-Supervised Object Detection
1. 要点
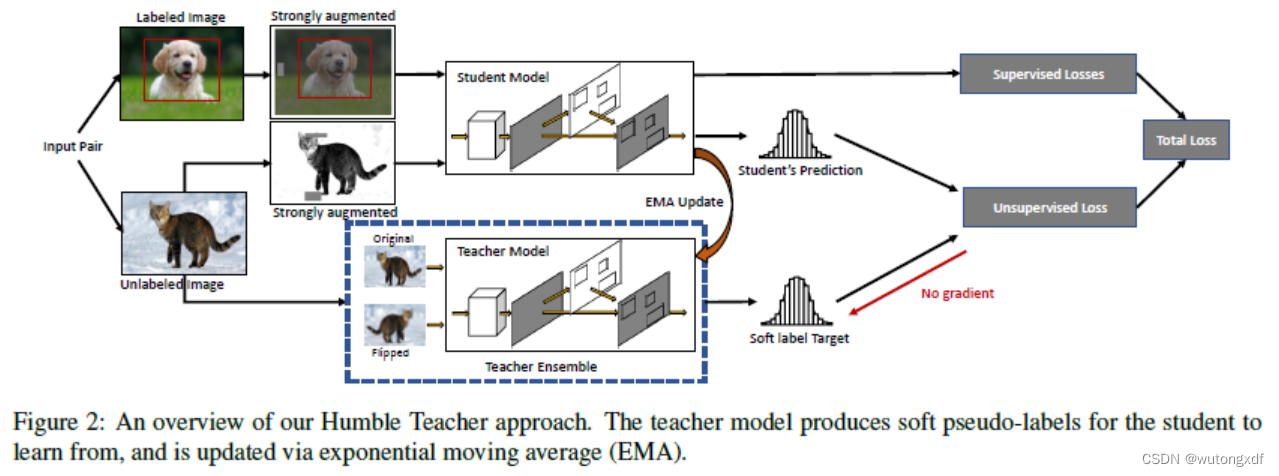
Humble Tearcher 遵循 teacher-student 双重模型框架(Fast R-CNN),主要创新点包括:
1) 采用指数滑动平均(Exponential Moving Average)策略,在线更新教师模型;
2) 使用大量的 region proposals 和 软伪标签(soft pseudo-labels)作为学生模型的训练目标;
3) 使用轻量级的检测专用数据集成,生成更可靠的伪标签。
2. Overview
训练时,将相同数量的带标签和未带标签的图像,分别输入监督分支和非监督分支。

1)监督分支
采用标准的两阶段检测器,如 Faster R-CNN。损失函数分为 RPN 和 ROI 两部分:
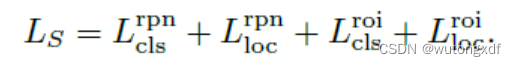
2)非监督分支
- 教师、学生、有监督分支使用同样的模型框架(Faster R-CNN),并使用相同的权重进行初始化;
- 学生模型与有监督分支共享权重,但与教师模型不共享;
- 学生模型与教师模型分别处理无标签图形。教师模型的输入图片只进行弱增广,输出伪标签,并且不使用反向传播算法更新权重;学生模型的输入图片经过同样的弱增广后,再进行强增广,输出的预测与伪标签计算非监督损失
。
3)图像增广
弱增广:随机翻转(flip),改变尺寸(resize);
强增广:

【注】Humble Teacher 不使用随机旋转、平移。
教师和学生模型使用非对称的数据增广。学生模型使用强的数据增广,提高学生模型的任务难度,促使其更好地学习图像特征;教师模型使用弱增广,以产生更多正确的伪标签。
4)预测阶段
使用教师模型进行预测,并且不使用任何数据增广。
3. Soft Labels and Unsupervised Loss
对于分类任务,软标签目标是预测的类别概率分布(不转化成独热向量式的伪标签);对于边界框回归任务,软标签目标是所有可能类别的偏移量。
1)RPN阶段

2)ROI 阶段

教师模型保留其在 RPN 阶段生成的 top-N 候选区域,然后将这些候选区域输入教师模型和学生模型的 ROI heads(学生模型不使用自己生成的候选区域)。
【注】在合理数量的候选区域上使用软伪标签,能够更全面地覆盖整个图像上的检测分值的分布情况(硬标签只区分前景和背景,没有涵盖中间情况)。
4. Exponential Moving Average for the Teacher Model Update

5. Teacher Ensemble with Horizontal Flipping
将图像及其水平翻转的版本作为输入来集成教师模型。
动机:当图像被翻转时,对象的类别应该保持不变,而从原始图像和翻转的复制版本中做出的平均预测可能比从单一图像中做出的预测更准确。

【注】只在 ROI 阶段使用集成方法。
参考资料:Humble Teachers Teach Better Students for Semi-Supervised Object Detection - 知乎
Instant-Teaching
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
动机
1. 已有的半监督目标检测(SST) SOTA 方案 STAC,通过一个固定的教师模型获得伪标签,在训练过程中不会进行更新。因此,当训练的学生模型的精度已经接近或超过教师模型时,使用教师模型提供的伪标签会限制模型精度的提升;
2. 数据增广在 SSL 中占据重要位置,应该针对 SSL 设计更有效的数据增广方式;
3. confirmation bias 问题,即模型给出了高置信度的错误预测,而这些错误的预测随后转变为错误的伪标签,在训练过程中累积,而模型无法自行纠正这些错误预测。
针对上述三个问题,作者提出了改善方案。

上图为两个模块:左边为基于弱-强数据增广的即时伪标签的 Instant-Teaching 模型;右边是协同校正(co-rectify)的 。
【注】Instant-Teaching 作为一个完整的 SSOD 框架,已经优于当时的 SOTA 方法。
1. Instant pseudo labeling
同时进行模型的训练和伪标注的生成,实现在线更新伪标签。随着模型在训练过程中逐步收敛,其生成的伪标签质量也会同步提高,从而能够从自己生产的伪标注中学习有用的信息,反过来进一步促进模型的学习。
每次迭代分为两步:
1)使用当前模型在 mini-batch 的无标签数据上生成伪标注,此阶段只是用弱增广(随机翻转);
2)对第一步产生的带有伪标注的数据使用强增广,使用完整的训练目标(包括监督损失和非监督损失 )来更新模型参数。

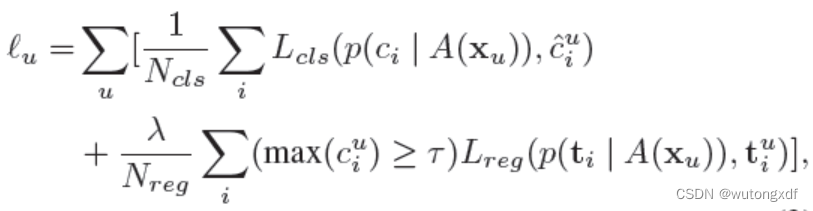
其中, 表示弱增广,
表示强增广。
【注】只对无标签数据进行强增广,对带标签数据只使用弱增广。与 STAC 类似,Instant-Teaching 也是对 NMS 后的预测框进行高置信度阈值筛选 hard label。
2. Extended weak-strong data augmentations

作者主要提出了两种针对无标签数据的数据增广方案:

1)Mixup
给定一个无标签图像及其伪标注,从mini-batch 中随机选择一个有 ground-truth 的带标签图像,用 分布得出的混合系数,混合这两张图片及其类标签和边界框坐标,以此代替无标签图像的内容和伪标注。
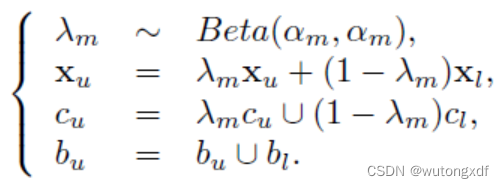
【注】作者设置 ,Beta(1, 1)等于均匀分布。
2)Mosaic
给定一个 mini-batch 的带标签和无标签图像,随机对图像及其相应标注进行两种混合(水平混合、垂直混合)。
3. Co-rectify
同时训练两个模型(Model-a 和 Model-b),分别为对方检查和纠正伪标签,从而有效抑制错误预测的积累,提高模型精度。
关键在于 Model-a 和 Model-b 不会收敛到同一个模型:
1)虽然两个模型具有同样的结构,但它们的初始化参数不同;
2)虽然两个模型共享 mini-batch 数据,但它们的数据增广和伪标签不同(使用对方生成的伪标注)。

【注】在 inference 阶段,只使用其中一个模型进行预测。















 1281
1281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









