







目录
1.2 Scaled Dot-Product Attention
2. SubLayer II:PositionwiseFeedForward 模块
论文:Attention Is All You Need
参考网络资源:
李宏毅老师的课程:强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili
月来客栈原理解析博客:This post is all you need(上卷)——层层剥开Transformer - 知乎 (zhihu.com)
迷途小书僮:
The Annotated Transformer的中文注释版(1) - 知乎 (zhihu.com)
The Annotated Transformer的中文注释版(2) - 知乎 (zhihu.com)
这篇笔记的目的是为了帮助入不了门自己更好地理解 Transformer 模型的实现细节。
Part I Transformer 论文要点概括
1. SubLayer I:Attention 模块
1.1 self-attention
自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。
——月来客栈《This post is all you need》
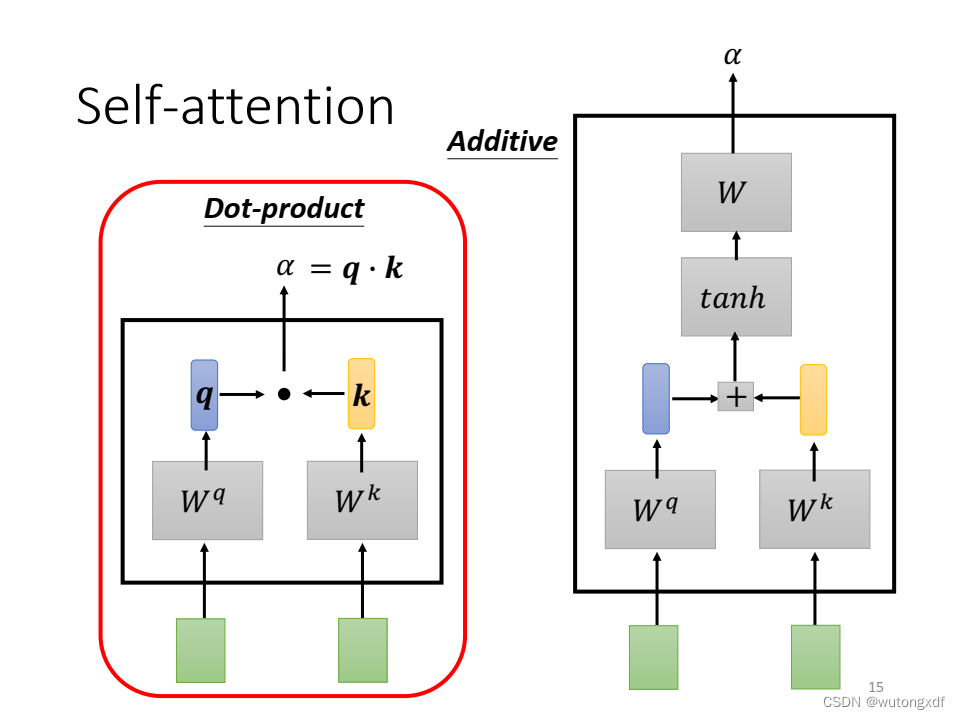
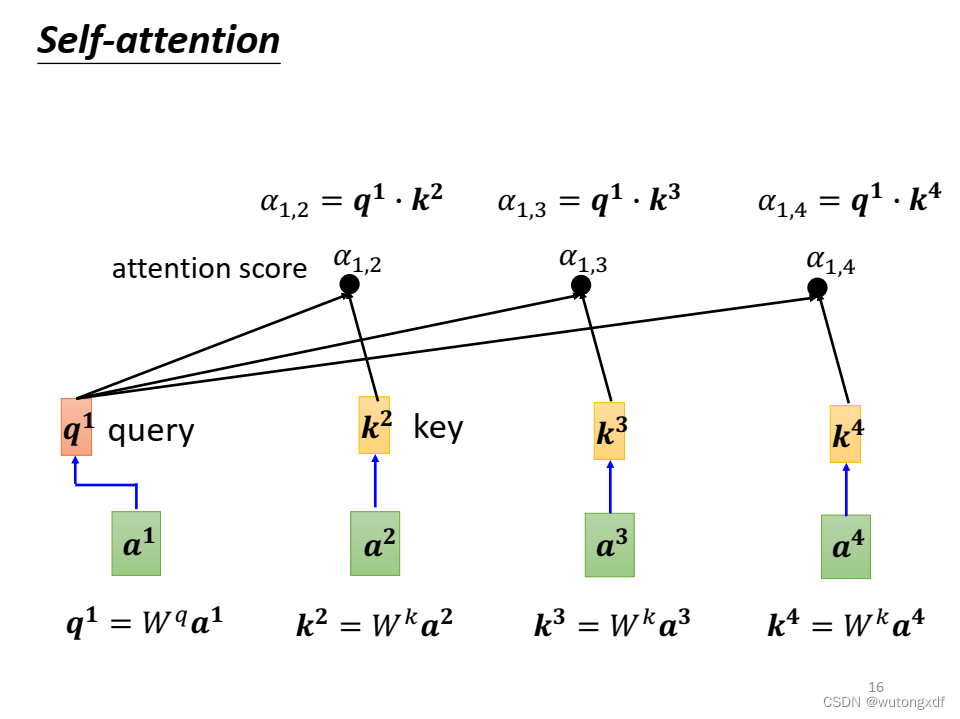
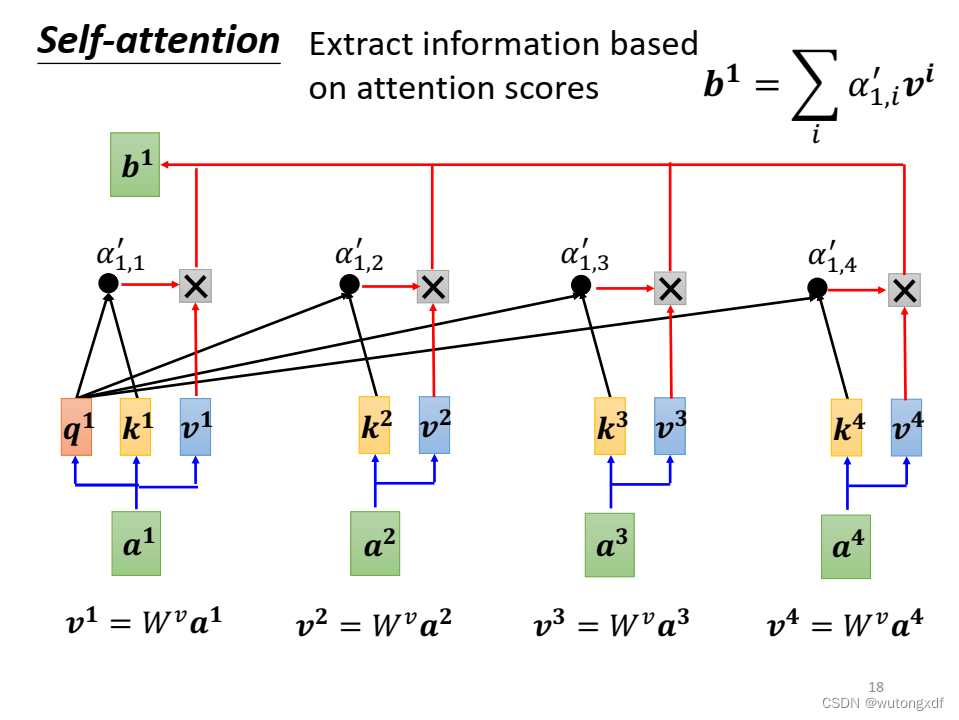
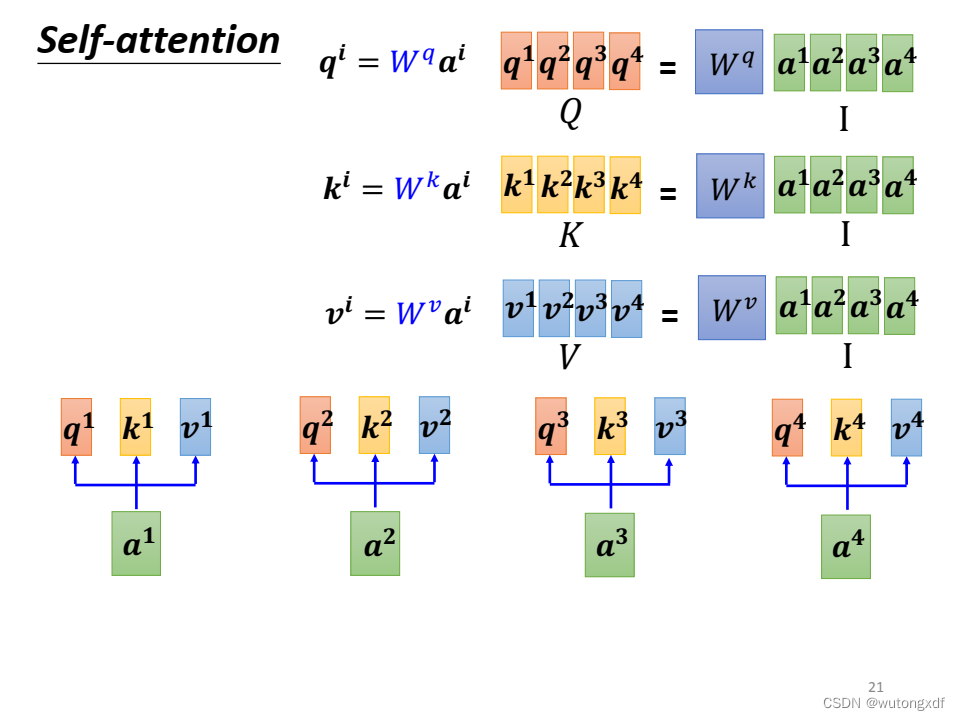
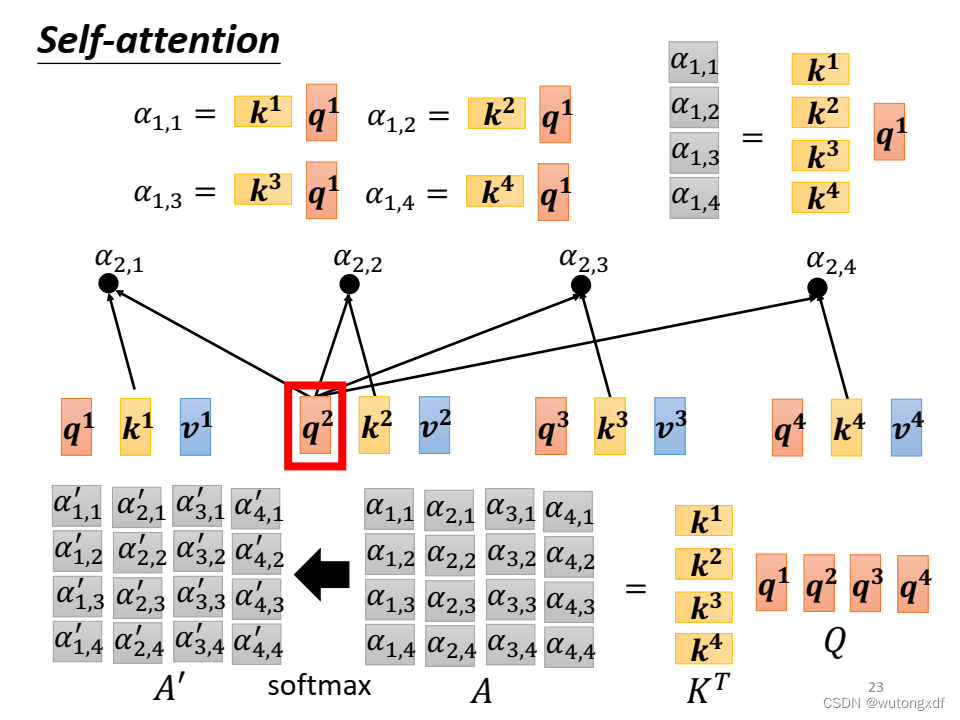
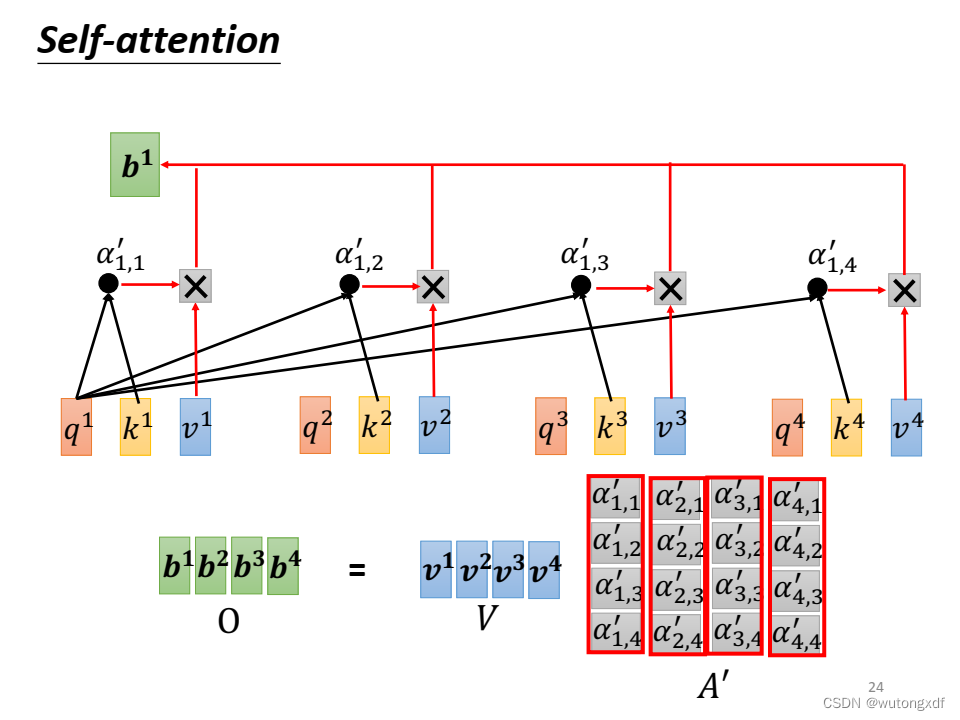
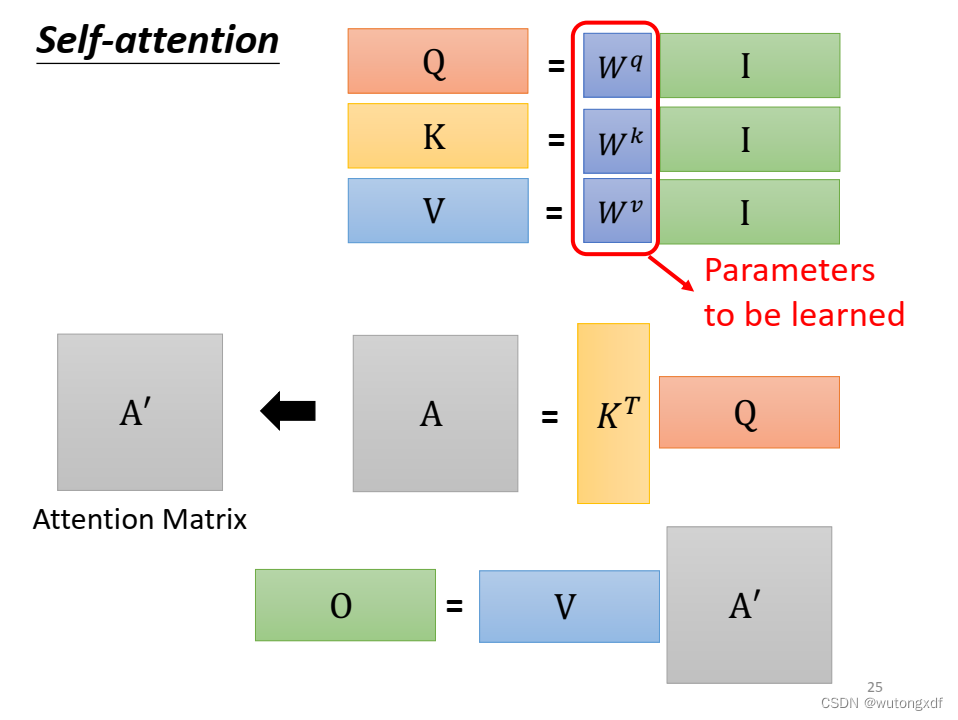
(图片截取自李宏毅老师PPT)
1.2 Scaled Dot-Product Attention
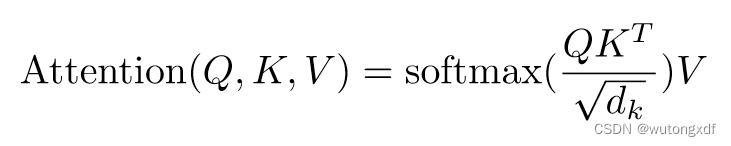
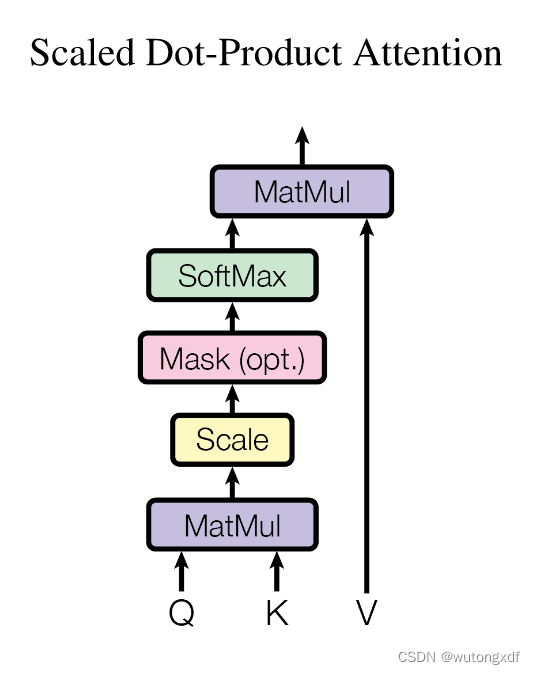
Compatibility Function: 指“兼容性函数”。在这篇论文中,它是指用于计算两个向量之间的相似度的函数。在第3.2节中,论文提到了两种兼容性函数:点积兼容性函数和广义点积兼容性函数。点积兼容性函数是两个向量的点积,而广义点积兼容性函数是两个向量的点积加上一个可学习的偏置项。这些兼容性函数用于计算注意力分布。
1.3 Mask
在一般的 self-attention 中,每个 query 都会关注到所有的 key-value 对,然而在进行文本生成等任务时,需要加入 masking 以屏蔽未来信息。例如,在进行机器翻译时,生成每个目标语言单词时,只能使用源语言句子中已经处理过的部分,并且不能使用尚未翻译的部分,因为我们在预测当前位置时不能依赖于其后面的信息。
因此,为了防止训练时模型利用未来信息进行预测,需要在 mask 中将未来的位置标记为不可见。这样就可以有效地将未来的信息屏蔽掉,防止泄露。Masking 将第 i 位之后的的输出换成非常大的负值,经过 softmax 之后就会转换为0(屏蔽第 i 位之后的输出)。
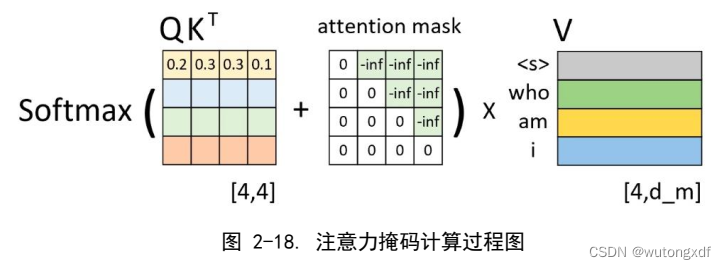
(图片截取自月来客栈《This post is all you need》)
1.4 Multi-Head Attention
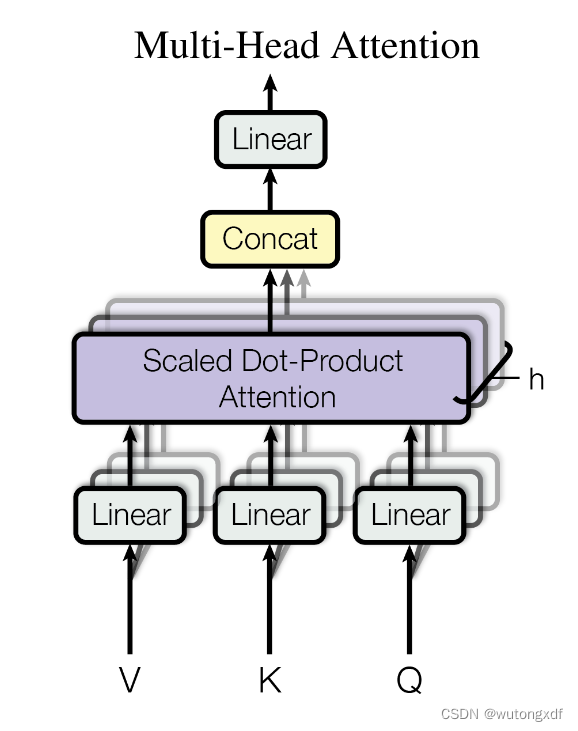
在 Transformer 模型中,使用 Multi-Head Attention 可以使模型更好地捕捉不同位置的语义信息,并且可以并行化计算以提高效率。
Multi-Head Attention 将输入的向量按照头数进行拆分,并在每个头上执行单独的注意力操作。
Q、K、V被切分后,不同的小矩阵经过了不同的线性层变换,因此可以学习到不同的参数。也就是说,在每个注意力头中,Q、K、V矩阵都是通过不同的模型进行映射的。这样,所有的头都可以学习到不同的特征和关系,从而使模型能够更全面地捕捉输入序列中的信息。
通过这种方式,模型可以同时关注输入中不同位置的信息,以及不同的语义方面(例如,单词之间的依赖关系和句子之间的关系),从而提高了模型对输入的表示能力。
此外,由于每个头都是独立地进行计算的,因此可以并行处理,从而加快了训练和推理速度。
使用多头注意力的优点如下:
-
提高模型的表达能力:多头注意力可以同时关注不同位置的信息,使模型能够更好地捕捉不同的特征及其关系。
-
减少过拟合的风险:多头注意力将原本需要一个大的注意力矩阵计算的操作分解成多个较小的注意力矩阵计算,从而减少了参数量,避免了过拟合。
-
加速训练和推理的速度:多头注意力可以通过并行计算来加速训练和推理的速度。 —— ChatGPT
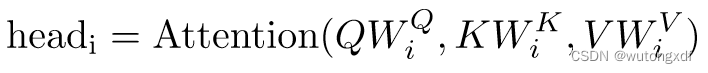
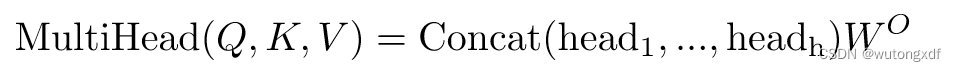
2. SubLayer II:PositionwiseFeedForward 模块
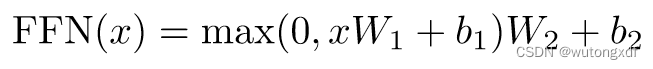
简单来说, 将 512-D 的 x 投影成 2048-D,
再将其投影回 512-D。
3. 模型总体架构
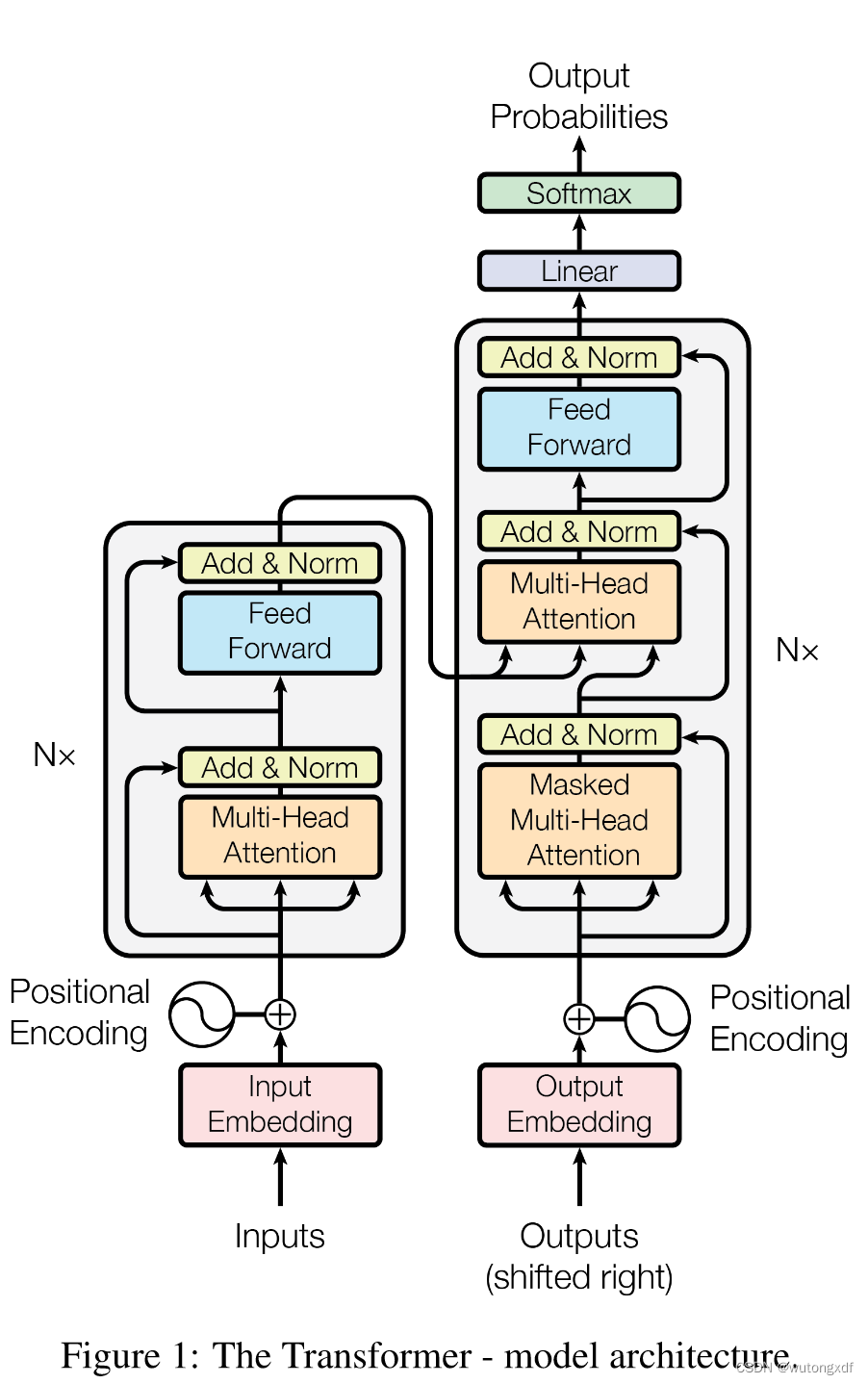
3.1 Encoder
Batch normalization (BN): 对于一个 mini-batch 的所有样本,在每个特征维度上计算其均值和方差;
Layer normalization (LN): 对于每一个样本的所有特征进行标准化。
3.2 Decoder
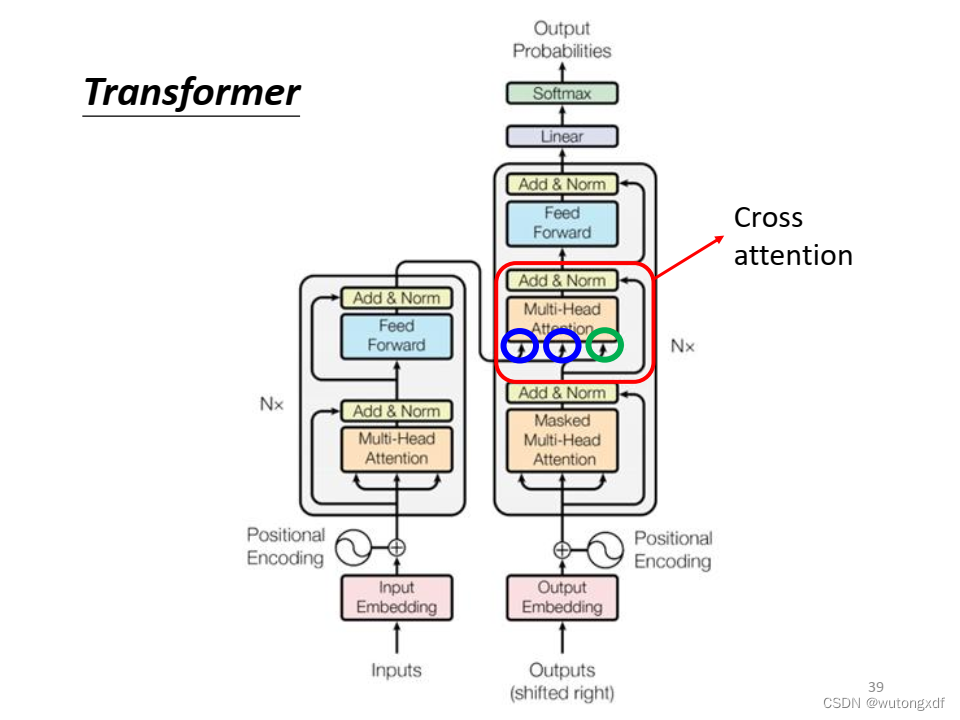
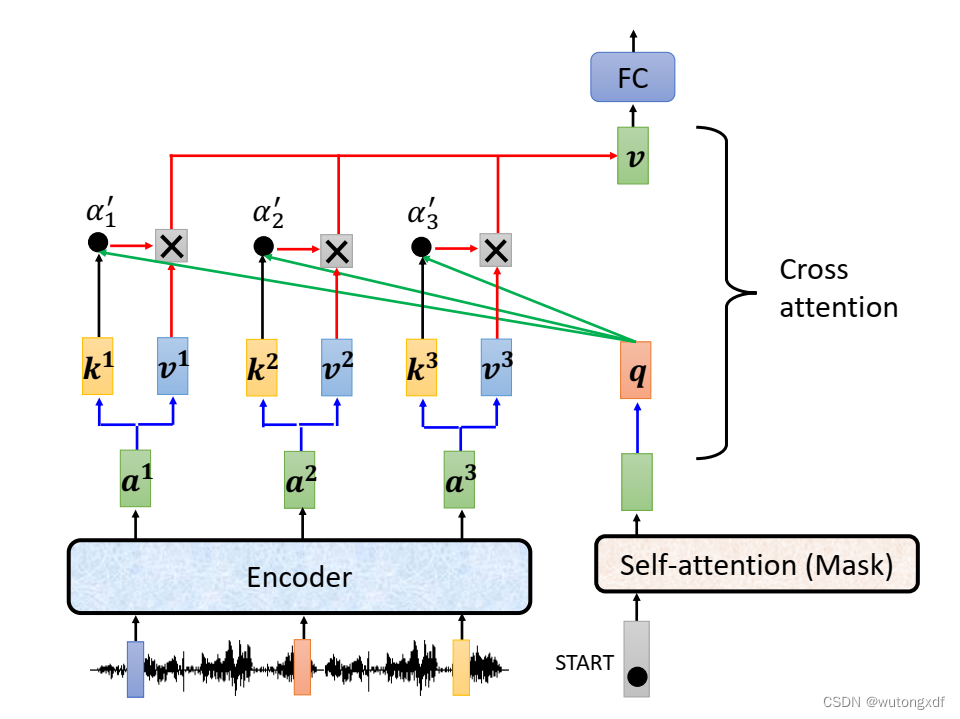
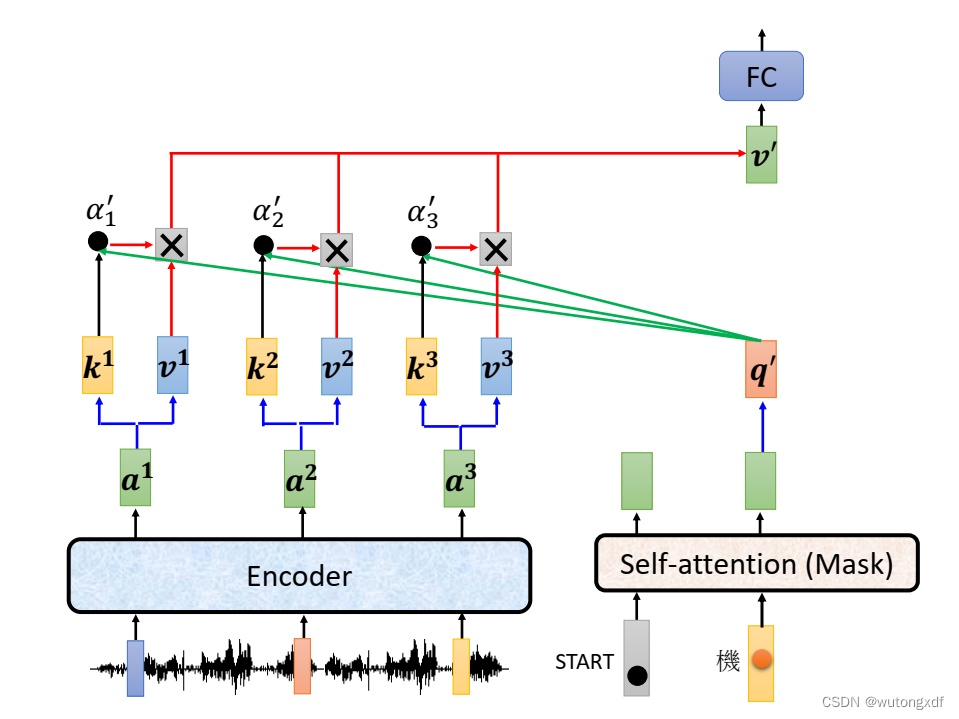
(图片截取自李宏毅老师PPT)
3.3 Positional Encoding
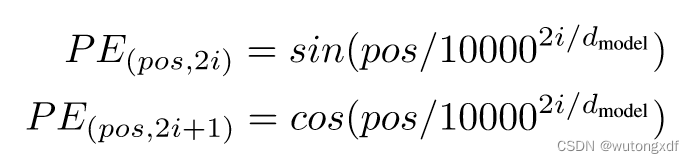
位置编码是为了让模型能够区分不同位置的词或字符而引入的。因为在 self-attention 的计算中,所有输入都是独立的向量,没有体现它们在序列中的相对位置信息,如果不加以区分,可能会使 Transformer 模型难以处理含有相对位置信息的序列数据,造成性能下降。 —— ChatGPT
3.4 Label Smoothing
Label Smoothing 主要解决模型在训练时对于训练数据过度拟合的问题。它通过调整训练集标签的分布,在标签数据分布中引入一些噪声,使得模型在训练时不再那么“自信”和过度拟合,从而提高模型的泛化能力。
给定一个真实标签 y,计算交叉熵损失时,不是直接将 1 分配到真实类别 y 上,而是将一部分概率分布分配到其它非真实类别上,以缓解模型对于真实类别的过度拟合。
相当于若共有 K 个类别,其中真实标签的置信度不再设为1,而是设为 (1−ϵ),其它(K-1)个非真实标签的置信度全部设为 ϵ/(K-1)。
4. 注意事项
【注1】在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
——月来客栈《This post is all you need》
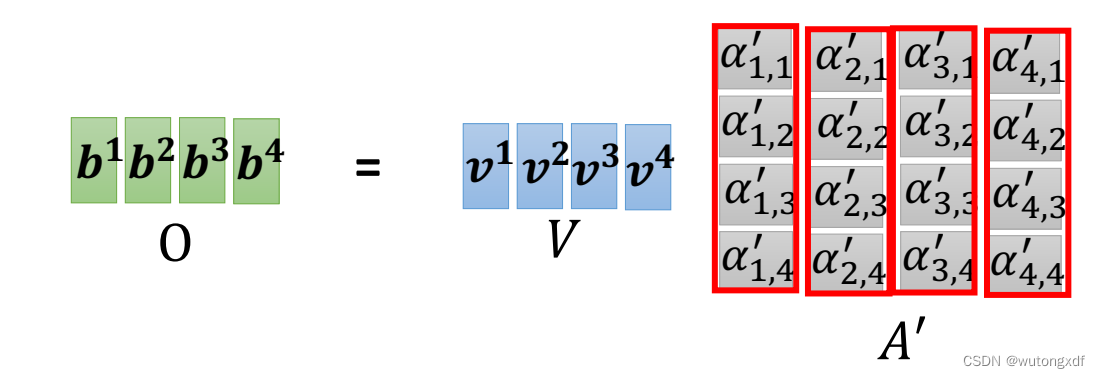
【注2】在通过模型进行实际的预测时,只取解码器输出的其中一个向量进行分类,然后作为当前时刻的解码输出。
类似于下图中,只选 作为解码输出。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









