







目录
12. Encoder-Decoder(Transformer)
论文:Attention Is All You Need
参考网络资源:
李宏毅老师的课程:强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili
月来客栈原理解析博客:This post is all you need(上卷)——层层剥开Transformer - 知乎 (zhihu.com)
迷途小书僮:
The Annotated Transformer的中文注释版(1) - 知乎 (zhihu.com)
The Annotated Transformer的中文注释版(2) - 知乎 (zhihu.com)
这篇笔记的目的是为了帮助入不了门自己更好地理解 Transformer 模型的实现细节。
Part II Transformer 代码理解
这部分参考的是 Harvard 团队的 PyTorch 实现版本:harvardnlp/annotated-transformer
仅仅总结我作为一个代码不入门的小白觉得不好理解的部分。
下面是知乎博主“迷途小书僮”划分的主要代码模块:
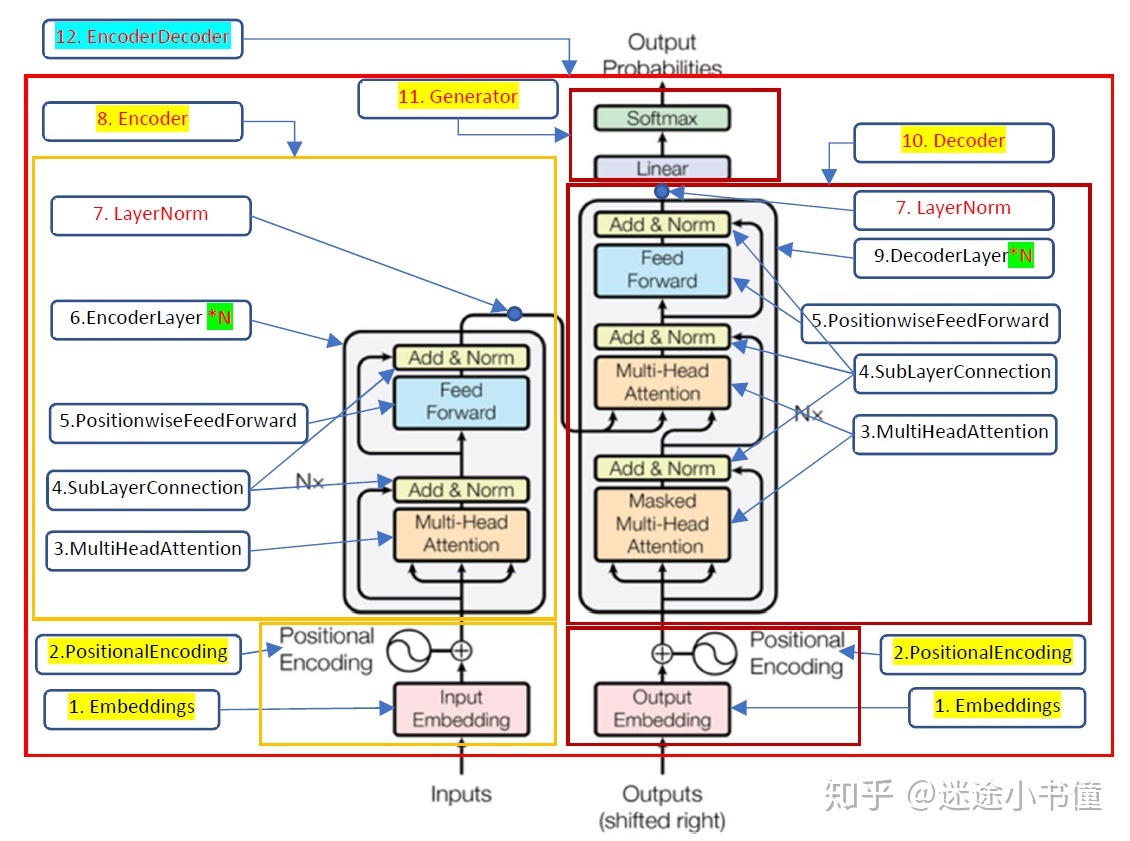
1. Embeddings
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
#d_model=512 表示词嵌入的维度, vocab=当前语言的词表大小
super(Embeddings,self).__init__()
self.lut=nn.Embedding(vocab,d_model)
# one-hot转词嵌入,这里有一个待训练的矩阵E,大小是vocab*d_model
self.d_model=d_model # 512
def forward(self,x):
# x ~ (batch.size, sequence.length, vocab),
return self.lut(x)*math.sqrt(self.d_model) self.lut(x)*math.sqrt(self.d_model) 是对词嵌入(word embedding)的值进行了一定程度的缩放,将词嵌入张量乘以 (具体的效果我也不十分理解,chatGPT说可以适应多头注意力机制的计算,它说“这个数值的选取略微增加了内积值的标准差,从而降低了内积过大的风险,可以使词嵌入张量在使用多头注意力时更加稳定可靠”。)
2. Positional Encoding(位置编码)
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
# 每个位置用一个512维的向量来表示其编码
position = torch.arange(0, max_len).unsqueeze(1)
# position ~ (max_len, 1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x) div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
1)div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
创建一个形状为 (d_model/2, )的张量 div_term,用于在位置编码矩阵的奇数列和偶数列上计算正弦函数和余弦函数的 pos 系数:
,对应论文中 pos 的系数。
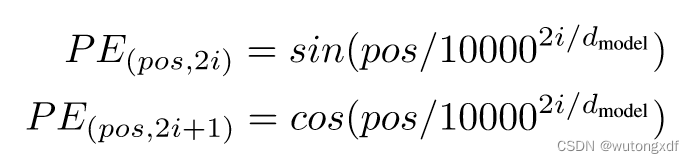
2) pe[:, 0::2] = torch.sin(position * div_term) 和 pe[:, 1::2] = torch.cos(position * div_term)
这两行代码将通过正弦函数和余弦函数计算得到的位置编码向量分别填充到位置编码矩阵 pe 的奇数列和偶数列中。
self.register_buffer("pe", pe)
将位置编码矩阵 pe 注册到 nn.Module 的可训练参数之外的缓冲区(buffer)。PyTorch 中使用 register_buffer 函数将一些常量或固定参数注册为模型的缓冲区,这些缓冲区的数值在模型训练过程中不会被改变,但可以保存在模型的状态字典中,被加载到模型中以提供其他模型的功能。
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
这句代码将位置编码矩阵 pe 中的位置编码向量与输入特征 x 相加,用于将位置信息融合到输入特征中。其中, self.pe[:, : x.size(1)] 表示从位置编码矩阵 pe 中取出前缀子矩阵,其中前缀长度为输入序列的实际长度。
3. MultiHeadedAttention
首先定义 attention 类,作为构建多头注意力模块的基础。
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
# query, key, value ~ (batch_size, num_head, tgt_seq or src_seq, de_model/num_head)scores = scores.masked_fill(mask == 0, -1e9)
mask 掩码张量指示哪些位置需要被屏蔽(即替换为 -1e9),哪些位置需要被保留。当 mask 中某个位置的值为 0 时,表示在对应的位置上需要进行屏蔽(即排除掉该位置的信息)。上述代码即是在计算 softmax 之前,将 scores 得分矩阵中对应位置的值替换为 -1e9,表示这个位置的得分值为负无穷大。这样,在 softmax 函数计算概率分布时,这些无效的位置的权重就会变得非常小,相当于被“抑制”掉了。而那些有效的位置,其对应的得分值不会受到影响,可以继续参与到后续的加权求和中,从而保留有效的信息。
接下来就是 MultiHeadedAttention 类。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
return self.linears[-1](x)上面的代码中,有一个事先定义的 clone 函数:
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) 会构建一个由 N 个深拷贝构成的ModuleList 对象,即每个元素都是原 module 的一个完整副本,深拷贝能确保复制后的对象与原始对象完全独立,修改其中任意一个对象的状态都不会影响其他对象。
MultiHeadedAttention 类的定义中,(我个人认为)最难理解的是下面这两句代码:
self.linears = clones(nn.Linear(d_model, d_model), 4)
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))]
这句代码实现了对 query、key 和 value 三个输入向量进行线性变换,并将变换后的向量进行形状变换和维度调整,以便后续的注意力机制计算。
1)将 self.linears 定义为一个长度为 4 的列表,其中前三个 nn.Linear 对象用于对输入向量进行线性变换;最后一个 nn.Linear 对象用于最终的线性变换操作;
2)在第二行代码的列表解析式中,zip() 函数将 self.linears 的前三个元素与 (query, key, value) 组成一个“键值对”的列表,self.linears 的元素与 (query, key, value)一一对应,分别对 query、key、value 进行线性变换操作;
3)对于每个“键值对”,使用线性层 l 对输入 x 进行线性变换,并将结果reshape为4维张量,然后执行 transpose函数 将第二维和第三维交换,以准备后续矩阵运算。
4. Sub-Layer Conneciton
SubLayerConnection 类主要实现两个功能:残差连接(Add) 以及 LayerNorm 操作。这里所指的 sub-layer 即上述 MultiheadAttention 和后面的第 5 部分 PositionwiseFeedForward 两类子层。
首先,定义模块中需要使用到的 LayerNorm 类:
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2features = d_model = 512(by default)
上面的 a_2,b_2 都是 512-D 的可训练的参数向量。
在上述代码中,若 x 的 shape 是 (batch_size, seq_len, d_model),因为 keepdim=True,则在 x 最后一个维度上进行计算出的 mean 和 std 的形状将是 (batch_size, seq_len, 1),最终返回张量的 shape 与 x 相同。
在计算 x - mean 时,会使用广播机制,将 mean 扩展成与 x 相同的形状,即在最后一个维度上进行扩展,得到一个形状为 (batch_size, seq_len, d_model) 的张量,并与 x 在最后一个维度进行计算。
相似的,a_2 是一个形状为 (d_model,) 的张量,当它与形状为 (batch_size, seq_len, d_model) 的 x - mean 的结果张量相乘时,会自动进行广播操作,将 a_2 扩展成形状为 (1, 1, d_model) 的张量,然后与 x - mean 的结果张量在最后一个维度进行逐元素相乘。
接下来是 SubLayerConnection 类:
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))5. Positionwise Feed-Forward
所谓的 positionwise feed-forward 其实就是全连接层,PositionwiseFeedForward 类如下:
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))实现的功能对应于论文中:
先进行维度变换:;之后再投影回原维度:
。
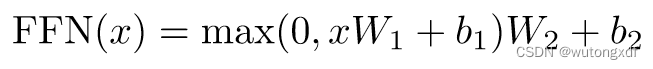
6. Encoder Layer
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)size = d_model = 512 (by default)
self.sublayer = clones(SublayerConnection(size, dropout), 2)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
第一句代码会创建两个 SublayerConnection 的副本,保存在列表 sublayer 中,每个子层连接的功能是将输入张量 x 与经过一定变换的另一个张量进行连接。
第二句代码对输入张量 x 执行第一个子层连接,具体流程如下:
1)lambda 函数中调用(多头)自注意力模块 self_attn,对 x 进行自注意力计算,并在计算过程中使用了掩码张量 mask,以避免未来信息的泄漏;
2)调用 SublayerConnection 中 的 forward 函数,将输入张量 x 与经过自注意力计算后的输出进行残差连接 (Add) & LayerNorm 操作。
第三句代码的流程与第二句类似,只不过第一步中对输入张量 x 进行的是 Positionwise Feed-Forward 操作。
7. LayerNorm
已经在 SubLayerConnection 部分讲过,故略去。
8. Encoder
Encoder 其实就是拼接上 N 个 Encoder Layer,即克隆 N 个 Encoder Layer,保存到 layers 列表中;然后在 Encoder 类的 forward 函数中利用 for 循环,调用 EncoderLayer 内部的 forward 函数,进行前向计算。
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)9. Decoder Layer
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)这部分与 Encoder Layer 很类似,所以就不给自己再解释一遍了。
关于 mask 部分的相关理解,后面会再稍微展开。
10. Decoder
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)这部分也是……略过。
11. Generator
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)这部分其实就是一个全连接层,权重矩阵的形状为 (d_model, trg_vocab_size),然后进行 softmax 操作。
12. Encoder-Decoder(Transformer)
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)主要就是将 Encoder、Decoder 两者做一个集成,组成完整的 Transformer 架构。
附1:构造 Transformer 对象
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
上述代码使用 Xavier 初始化方法(Xavier initialization)对 Transformer 模型中的所有参数进行初始化。
附2:Mask
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0通过 torch.triu(torch.ones(attn_shape), diagonal=1) 生成一个上三角矩阵,再通过 subsequent_mask == 0 将其转换为布尔类型并取反,最终生成的掩码张量上三角部分全为 False,下三角部分全为 True。
可以参考博主迷途小书僮的例子:

【注】上述代码仅是基于 harvardnlp/annotated-transformer 版本的 Transformer 代码进行理解。具体使用 Transformer 实现各种任务时,需要对各个部分和训练细节进行适当的调整,如只使用 Encoder/Decoder,在生成 Batch 时对语言序列 padding 成同样长度后,在后续计算中也要使用 padding-mask 等等。
最后,感谢李宏毅老师,上面提到的各位博主,以及 chatGPT。















 1711
1711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









