






 该文介绍了如何使用机器学习进行音乐风格分类,涉及数据导入、预处理(包括添加类别标签和去除无关特征)、随机森林模型训练以及交叉验证进行超参数调优。通过特征分析和模型验证,评估了模型在不同特征和树数量下的性能。
该文介绍了如何使用机器学习进行音乐风格分类,涉及数据导入、预处理(包括添加类别标签和去除无关特征)、随机森林模型训练以及交叉验证进行超参数调优。通过特征分析和模型验证,评估了模型在不同特征和树数量下的性能。
1 任务介绍
基于机器学习的音乐风格分类,包含数据的导入,特征选择,机器学习模型,超参数调整。
数据集连接:https://download.csdn.net/download/ww596520206/87860225
2 数据导入
data文件夹包含了所有数据,其中文件名为类别名称,可以发现共有6类,分别为:classical、country、edm、jazz、rap、rock,读取文件夹,计算每个类别的数目如下所示
import pandas as pd
import numpy as np
from sklearn.utils import shuffle
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, recall_score, f1_score, confusion_matrix
import matplotlib.pyplot as plt
classical = pd.read_csv("data/classical_csv.csv")
country = pd.read_csv("data/country_csv.csv")
edm = pd.read_csv("data/edm_csv.csv")
jazz = pd.read_csv("data/jazz_csv.csv")
rap = pd.read_csv("data/rap_csv.csv")
rock = pd.read_csv("data/rock_csv.csv")
print("classical num is "+str(len(classical)))
print("country num is "+str(len(country)))
print("edm num is "+str(len(edm)))
print("jazz num is "+str(len(jazz)))
print("rap num is "+str(len(rap)))
print("rock num is "+str(len(rock)))
classical num is 2119
country num is 2011
edm num is 2043
jazz num is 2178
rap num is 2162
rock num is 2035
2 数据处理
2.1 数据预处理,为每个数据添加类别
classical.insert(loc=10, column='class', value=0)
country.insert(loc=10, column='class', value=1)
edm.insert(loc=10, column='class', value=2)
jazz.insert(loc=10, column='class', value=3)
rap.insert(loc=10, column='class', value=4)
rock.insert(loc=10, column='class', value=5)
all_data = pd.concat([classical, country, edm, jazz, rap, rock])
2.2 特征: Unnamed: 0是每个歌曲的编号,对分类没有作用,可以丢掉
all_data.drop(["Unnamed: 0"],axis=1, inplace=True)
2.3 计算每个特征的方差,剔除掉方差过小的特征
all_data.std(axis=0)
all_data.drop(["speechiness"],axis=1, inplace=True)
最后保留的特征为:acousticness、danceability 、energy 、instrumentalness、key、loudness、tempo、valence ,共计8个。
3 特征分析
3.1 绘制每个特征的概率密度函数
for i, col in enumerate(all_data.columns[:-1]):
plt.subplot(2, 4, i + 1)
one_data = all_data.loc[:, col]
one_data.plot(kind="kde")
plt.title(col)
plt.show()
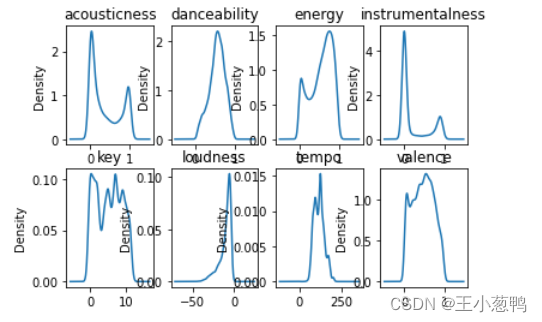
3.2 绘制每个特征的直方图
for i, col in enumerate(all_data.columns[:-1]):
plt.subplot(2, 4, i + 1)
feature_data = all_data.loc[:, col]
feature_data.plot(kind="hist")
plt.title(col)
plt.show()
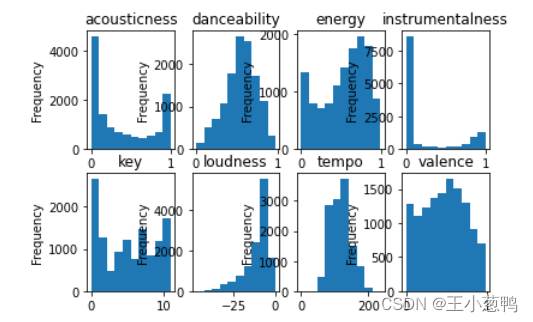
4 模型训练和验证
4.1 对于训练集划分训练集和验证集,训练集占70%,验证集占30%,并且前11列为特征列,最后一列为标签列
all_data = shuffle(all_data)
train_num = int(len(all_data) * 0.7)
train_features, train_labels = all_data.iloc[:train_num, :-1].values, all_data.iloc[:train_num, -1].values
val_features, val_labels = all_data.iloc[train_num:, :-1].values, all_data.iloc[train_num:, -1].values
4.2 数据归一化
scaler = MinMaxScaler()
scaler.fit(train_features)
train_features = scaler.transform(train_features)
val_features = scaler.transform(val_features)
4.3 搭建模型,使用随机森林模型,使用cpu计算,随机森林是集成模型,包含了好多树模型。
model = RandomForestClassifier()
model.fit(train_features, train_labels) # 训练模型
train_pred = model.predict(train_features) # 在训练集测试
val_pred = model.predict(val_features) # 在验证集测试
print("train acc: {}".format(accuracy_score(train_labels, train_pred)))
print("val acc:{}".format(accuracy_score(val_labels, val_pred)))
4.4 使用交叉验证评估参数
score_list = []
cv_num = 10
for n_estimators in [25, 50, 70]:
model = RandomForestClassifier(n_estimators=n_estimators)
score = cross_val_score(model, train_features, train_labels, cv=cv_num)
score_list.append(score)
plt.plot(range(cv_num), score_list[0],
range(cv_num), score_list[1],
range(cv_num), score_list[2],)
plt.legend(["n=25","n=50","n=70"])
plt.show()
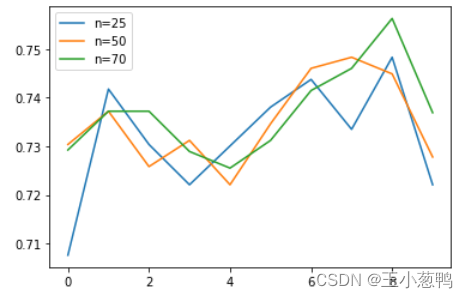



















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











