







本文内容学习自: https://www.pytorch123.com/、 https://pytorch.org/tutorials/
Tensors(张量)
#引用torch
import torch
#构造一个2×3矩阵
x=torch.empty(2,3)
#tensor([[2.6223e-09, 1.3096e-11, 1.0921e-05],
# [1.6690e-07, 5.3686e-05, 1.0082e-08]])
#构造一个随机初始化的矩阵
x=torch.rand(2,3)
#tensor([[0.7821, 0.0928, 0.0124],
# [0.4690, 0.0199, 0.7196]])
#构造一个全为0的矩阵,数据类型为long
x=torch.zeros(2,3,dtype=torch.long)
#tensor([[0, 0, 0],
# [0, 0, 0]])
#构造一个张量
x=torch.tensor([1.1,2.2])
#基于已存在tensor创建tensor
x = x.new_ones(5, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
print(x)
#获取维度信息
x.size()
#torch.Size([5,3)
#常见操作
#加法
x+y
torch.add(x,y)
torch.add(x,y,out=z)
y.add_(x)
#改变大小
x=torch.randn(4,4)
y=x.view(16)
z=x.view(-1,8)
a=x.view(2,8)
b=x.view(8,2)

#只有一个元素的tensor,可以使用.item()来获得值
x = torch.randn(1)
x
x.item()
#tensor([0.1021])
#0.10205964744091034
自动微分
- torch.tensor的属性 .requires_grad 设置为True,会开始跟踪针对tensor的所有操作
- .backward() :自动计算所有梯度
- 梯度累计到 .grad 属性中
- 停止历史记录的跟踪,可以调用 .detach() ,还可以将代码块使用 with torch.no_grad(): 包装起来
x=torch.ones(2,2,requires_grad=True)
print(x)
y=x**3+1
print(y)
y.backward(torch.ones_like(y))
print(x.grad)

x=torch.ones(2,2,requires_grad=True)
y=x+2
z=y*y*3
out=z.mean()
out.backward()
print(x.grad)
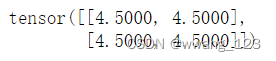
自定义数据集
自定义Dataset类必须实现三个函数:
__init__、__len__、__getitem__
实例:FashionMNIST 图像存储在一个目录img_dir中,它们的标签分别存储在一个 CSV 文件annotations_file中
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
猫狗二分类数据集实例:data目录中包含train和val两个文件夹,其中每个文件夹里面都是猫和狗的图片,文件名分别为cat.序号.jpg和dog.序号.jpg
代码引用自https://blog.csdn.net/m0_63567560/article/details/125913787(有一点点修改)
class CatDogDataset(Dataset):
def __init__(self, filepath,transform=None):
self.images = []
self.labels = []
self.transform = transform
for filename in tqdm(os.listdir(filepath)):
image = Image.open(filepath +"/"+ filename)
image = self.transform(image)
self.images.append(image)
if filename.split('.')[0] == 'cat':
self.labels.append(0)
elif filename.split('.')[0] == 'dog':
self.labels.append(1)
self.labels = torch.LongTensor(self.labels)
def __getitem__(self, index):
return self.images[index], self.labels[index]
def __len__(self):
images = np.array(self.images)
len = images.shape[0]
return len
torch.utils.data.DataLoader类
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
遍历DataLoader
每次迭代都会返回一批train_features和train_labels
for data in train_loader:
inputs,targets = data
数据转换
所有TorchVision数据集都有两个参数
- transform (修改特征)
- target_transform (修改标签)
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
ToTensor 将 PIL 图像或 NumPyndarray转换为FloatTensor. 并在 [0., 1.] 范围内缩放图像的像素强度值
Lambda 转换应用任何用户定义的 lambda 函数。在这里,我们定义了一个函数来将整数转换为 one-hot 编码张量。它首先创建一个大小为 10 的零张量(我们数据集中的标签数量)并调用 scatter_,它在标签上分配 value=1给定的索引y。
构建神经网络
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
定义类
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)

nn.Flatten()
将每个2D 28×28图像转换为784个像素值的连续数组
input_image = torch.rand(3,28,28)
#torch.Size([3, 28, 28])
input_image = torch.rand(3,28,28)
#torch.Size([3, 784])
nn.Linear()
线性层使用存储的权重和偏差对输入进行线性变换
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
#torch.Size([3, 20])
nn.ReLU()
非线性激活是在模型的输入和输出之间创建复杂映射
hidden1 = nn.ReLU()(hidden1)
nn.Sequential
是一个有序的模块容器。可以使用它来构建一个快速网络。
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
nn.Softmax
神经网络中最后一层返回值传递给softmax模块,值被缩放到[0,1],表示对每个类别的预测概率大小。dim参数指示值必须总和为 1 的维度。
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
模型参数
model.parameters()
model.named_parameters()
for name,param in model.named_parameters():
print(name,param)
保存和加载模型方法
方法一、保存和加载模型
- 将学习到的参数存储在内部状态字典(state_dict)中
- 在加载时,要预先创建一个相同的模型实例,然后使用load_state_dict()方法加载参数。
model = models.vgg16(pretrained=True)
torch.save(model.state_dict(), 'model_weights.pth')
model = models.vgg16()
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
方法二、保存模型形状加载模型
此种方法可以将类结构和模型参数一起保存
torch.save(model, 'model.pth')
model = torch.load('model.pth')














 2252
2252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









