







在使用pytorch训练自己的模型的时候,需要用到Dataset,我们自定义数据集的时候一般要继承Dataset类,为了更清楚的看到Dataset做的操作,我尝试了一些数据。
from torch.utils.data import Dataset
import torch
class ClsDataset(Dataset):
# x,y是接受的数据,此处x一般是特征向量,y一般是标签
def __init__(self,x,y):
self.x = x
self.y = y
def __getitem__(self, item):
return self.x[item],self.y[item]
def __len__(self):
return len(self.x)
# 尝试使用二维的list
x = [[1,2,3],[2,5,6],[6,7,8]]
y = [2,2,7]
cls = ClsDataset(x,y)
print(cls[0])
# 尝试使用元组类型的list
x1=[(1,2,3),(2,3,4),(7,7,7)]
y1 = [1,2,3]
cls1 = ClsDataset(x1,y1)
print(cls[1])
# 尝试使用字典的列表
x2 = [{'tom',2},{'cat',4},{'tyson',6}]
y2 = (9,1,2)
cls2 = ClsDataset(x2,y2)
print(cls2[2])
# 尝试使用torch的类型
x3 = torch.randn(3,4)
y3 = torch.tensor([2,4,5])
cls3 = ClsDataset(x3,y3)
print(cls3[0])
# 遍历
print('遍历dataset')
for i,data in enumerate(cls):
print('----第{}次取数据-----'.format(i+1))
x, y = data
print('x={}'.format(x))
print('y={}'.format(y))
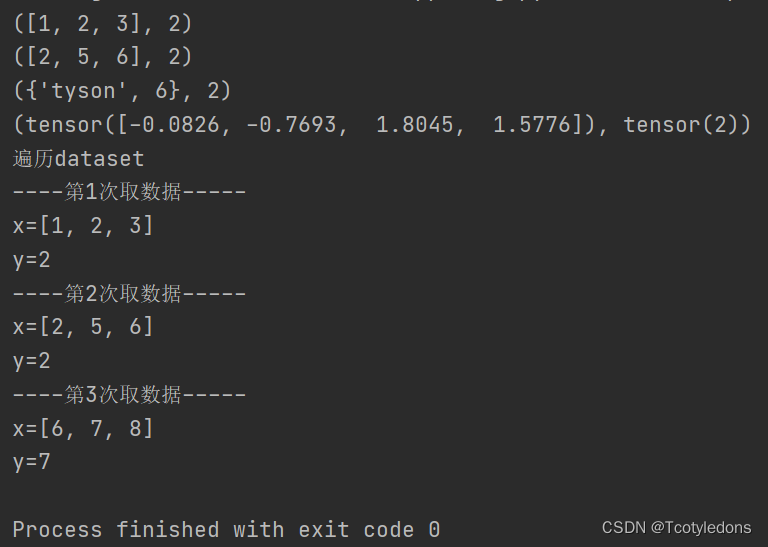
最后的输出如下显示,这样就大概知道了数据从输入到输出的一个大致的模式:















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









