







全连接前馈神经网络DNN
| 模型结构 | 模型训练/学习 | 说明 |
|---|---|---|
| 前馈神经网络DNN | 反向传播算法BP 梯度消失/溢出问题 | DNN模型结构及训练算法 |
| 人工神经元模型 | 梯度下降法 | 神经网络基础知识 |
人工神经元模型
 输入:X
输入:X
输出:Y
参数:w,b
函数关系:
Z
=
x
1
w
1
+
x
2
w
2
+
.
.
.
+
x
n
w
n
+
b
Z=x_{1}w_{1}+x_{2}w_{2}+...+x_{n}w_{n}+b
Z=x1w1+x2w2+...+xnwn+b
Y
=
σ
(
z
)
=
σ
(
W
T
+
b
)
Y=\sigma(z)=\sigma(W^{T}+b)
Y=σ(z)=σ(WT+b)
激活函数
为了增强网络的表达能力,需要引入连续的非线性激活函数
激活函数的性质:
- 连续并可导(允许少数点上不可导)的非线性函数
– 可导的激活函数可以直接利用数值优化的方法来学习网络参数- 激活函数及其导数要尽可能简单
– 有利于提高网络计算效率- 激活函数的导函数的值域要在一个合适的区间内
– 不能太大或太小,否则会影响训练的效率和稳定性
常用的激活函数
-
σ ( x ) = 1 1 + e x p ( − x ) ( S i g m o i d / l o g i s t i c ) \sigma(x)=\frac{1}{1+exp(-x)}(Sigmoid/logistic) σ(x)=1+exp(−x)1(Sigmoid/logistic)
-
t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) tanh(x)=\frac{exp(x)-exp(-x)}{exp(x)+exp(-x)} tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)
-
R e L U ( x ) = { x x ≥ 0 0 x < 0 = m a x ( 0 , x ) ReLU(x)=\left\{\begin{matrix} x& x\geq 0 \\ 0& x< 0\\ \end{matrix}\right.=max(0,x) ReLU(x)={x0x≥0x<0=max(0,x)
-
L e a k y R e L U ( x ) = { x x > 0 γ x x ≤ 0 = m a x ( 0 , x ) + γ m i n ( 0 , x ) LeakyReLU(x)=\left\{\begin{matrix} x& x> 0 \\ \gamma x& x\leq 0\\ \end{matrix}\right.=max(0,x)+\gamma min(0,x) LeakyReLU(x)={xγxx>0x≤0=max(0,x)+γmin(0,x)
-
E L U ( x ) = { x x > 0 γ ( e x p ( x ) − 1 ) x ≤ 0 = m a x ( 0 , x ) + m i n ( 0 , γ ( e x p ( x ) − 1 ) ) ELU(x)=\left\{\begin{matrix} x& x> 0 \\ \gamma (exp(x)-1)& x\leq 0\\ \end{matrix}\right.=max(0,x)+min(0,\gamma(exp(x)-1)) ELU(x)={xγ(exp(x)−1)x>0x≤0=max(0,x)+min(0,γ(exp(x)−1))
-
s o f t p l u s ( x ) = l o g ( 1 + e x p ( x ) ) softplus(x)=log(1+exp(x)) softplus(x)=log(1+exp(x))
激活函数的导数
 ### DNN模型结构
### DNN模型结构
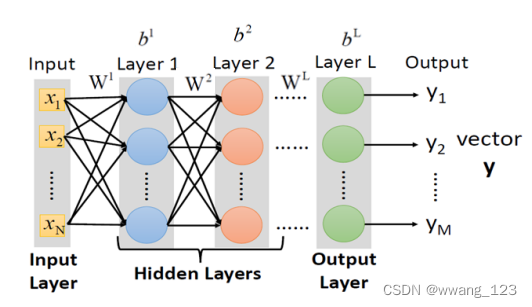
模型输入:X
模型输出:Y
模型参数:层间连线权重w1,w2,…,wL,各层偏置b1,b2,…bL
Y
=
f
(
x
,
θ
)
θ
=
w
1
,
b
1
,
.
.
.
,
w
L
,
b
L
Y=f(x,\theta) \theta={w^{1},b^{1},...,w^{L},b^{L}}
Y=f(x,θ)θ=w1,b1,...,wL,bL
y
=
f
(
x
)
=
σ
(
w
L
.
.
.
σ
(
w
2
σ
(
w
1
x
+
b
1
)
+
b
2
)
.
.
.
+
b
L
)
y=f(x)=\sigma(w^{L}...\sigma(w^{2}\sigma(w^{1}x+b^{1})+b^{2})...+b^{L})
y=f(x)=σ(wL...σ(w2σ(w1x+b1)+b2)...+bL)
梯度下降法
通过调整参数,让模型输出递归性地逼近标准输出
步骤:
- 定义目标函数(损失函数):一般将问题转化成求极值问题
- 优化目标函数:通过求目标函数的极值来确定参数
常见的损失函数:


求解过程:
- 定义目标函数
绝对值损失函数:
C ( θ ) = L ( Y , f ( x m θ ) ) = ∣ Y − f ( x , θ ) ∣ C(\theta)=L(Y,f(xm\theta))=|Y-f(x,\theta)| C(θ)=L(Y,f(xmθ))=∣Y−f(x,θ)∣
优化目标:求 m i n C ( θ ) minC(\theta) minC(θ) - 优化目标函数:
通过求目标函数的极值来确定参数
原理:
泰勒展开:如h(x)在 x = x 0 x=x_{0} x=x0附近无限可微
h ( x ) = ∑ k = 0 ∞ h k ( x 0 ) k ! ( x − x 0 ) k = h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) + h ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + . . . h(x)=\sum_{k=0}^{\infty }\frac{h^{k}(x_{0})}{k!}(x-x_{0})^{k} =h(x_{0})+h^{'}(x_{0})(x-x_{0})+ \frac{h^{''}(x_{0})}{2!}(x-x_{0})^{2}+... h(x)=∑k=0∞k!hk(x0)(x−x0)k=h(x0)+h′(x0)(x−x0)+2!h′′(x0)(x−x0)2+...
当x与 x 0 x_{0} x0足够接近时
h ( x ) ≈ h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) h(x)\approx h(x_{0})+h^{'}(x_{0})(x-x_{0}) h(x)≈h(x0)+h′(x0)(x−x0)
h ( x i + 1 ) = h ( x i ) + h ′ ( x i ) ( x i + 1 − x i ) h(x_{i+1})= h(x_{i})+h^{'}(x_{i})(x_{i+1}-x_{i}) h(xi+1)=h(xi)+h′(xi)(xi+1−xi)
每次取 x i + 1 x_{i+1} xi+1应满足 h ( x i + 1 ) < h ( x i ) h(x_{i+1})<h(x_{i}) h(xi+1)<h(xi)
h ( x i + 1 ) − h ( x i ) = h ′ ( x i ) ( x i + 1 − x i ) < 0 h(x_{i+1})-h(x_{i})=h^{'}(x_{i})(x_{i+1}-x_{i})<0 h(xi+1)−h(xi)=h′(xi)(xi+1−xi)<0
即满足 h ′ ( x i ) ( x i + 1 − x i ) < 0 h^{'}(x_{i})(x_{i+1}-x_{i})<0 h′(xi)(xi+1−xi)<0条件h(x)将趋于变小
每步参数调整:
x i + 1 = x i − η h ′ ( x i ) x_{i+1}=x_{i}-\eta h^{'}(x_{i}) xi+1=xi−ηh′(xi)

反向传播算法
核心思想
将输出误差以某种形式反传给各层所有的单元,各层按本层误差修正各单元连接权值
-
定义损失函数
 各层参数与损失函数的关系:
各层参数与损失函数的关系:

-
调参数优化目标函数
各层均采用梯度下降法调整参数
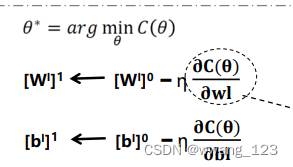
DNN训练过程
- 先前馈计算每一层的状态和激活值,直到最后一层
- 反向传播计算每一层的误差
- 计算每一层的偏导数并更新参数
梯度消失问题
激活函数导数值小于1时,误差经过每一层传递都会不断衰减,当网络很深时甚至消失
解决梯度消失问题的方法
- 选择合适的激活函数
- 用复杂的门结构代替激活函数
- 残差结构
解决过拟合问题方法
- 选择合适的正则方法
- Droupout
- 损失函数加入适当的正则项















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









