







1.研究背景
1.1 图像金字塔
图像金字塔如下图Fig1所示是一种以多分辨率来解释图像的结构,通过对原始的图像进行不同尺度的像素采样的方法,生成多个不同分辨率的图像。将生成的图像按照分辨率的大小从大到小进行排列,这就构成了一个图像金字塔,图像金字塔可以用在解决目标检测在处理多尺度变化问题。

1.2 特征金字塔
在绝大多数目标检测网络中,如下图Fig2特征金字塔(Feature Pyramid Network,FPN)是一个不可缺少的部分,FPN网络主要解决的问题是目标检测在处理多尺度变化问题的不足。FPN主要有以下两个作用:1)多尺度特征融合,提高了特征的丰富程度;2)使用分治法,将目标检测任务按照目标尺寸不同,分成若干个检测子任务。

2.存在的问题
在目标检测中兼顾大尺寸目标和小尺寸目标是一个难点,图像金字塔与特征金字塔可以解决多尺度变化的问题,但还是存在一下问题:
1)图像金字塔通过缩放输入图像实现不同尺寸的目标检测,虽然效果很好,但是速度很慢。
2)FPN虽然在速度上会比图像金字塔要快一些,但是还是存在一些问题,第一是由于不同尺寸的目标会被分配到不同的特征层上可能会导致过拟合;第二是在特征金字塔中,小尺度目标使用低层特征,大尺度目标使用高层特征,对于低层特征来自网络的浅层,而高层特征来自网络的深层,这就使得高层网络的能力更强,对于低层网络在检测上存在不公平。
3.TridentNet
3.1 网络结构
针对以上的问题,文章提出了TridentNet,网络结构如下图Fig3所示,网络中包含3个使用膨胀卷积的特征图分支,它们的网络结构相同只有膨胀卷积的膨胀率不同,膨胀率为1,2,3。网络中使用这三个分支来检测不同尺寸的物体,并且每个检测分支的深度相同这对于检测不同尺寸的物体就保持了公平性。

3.2 网络细节
TridentNet网络中的具体结构如下图Fig4所示,TridentNet网络中包含了三个带有膨胀卷积的残差块,在训练的过程中,网络会对每一个分支都进行优化。因此,需要对图片中的ground truth进行一个分配,公式为:,其中w,h为ground truth的宽,高。
,
为人工定义的参数。由于网络中三个分支的结构相同只是膨胀卷积的膨胀率不同,文中提出可以实现三个分支的参数共享,这样对于不同尺寸的目标包含的信息都会保存在一套参数中。如此,网络可以近似成为一个只有主要分支的网络。
网络在预测的时候,由于网络中有三个分支,所以每个分支都会产生检测结果,对于每个分支使用NMS或者soft-NMS处理掉在该分支之外的bbox,如果对每个分支都进行检测那这样预测的速度是很慢的。为此,文中提出了Fast Inference Approximation,在预测的时候只是用中间的那个分支,因为中间的分支有效的覆盖了大目标和小目标。这样做与原始的三分支预测相比性能只有很小的下降。这也就是使用了参数共享的一个有点。

4.实验
1)下图Fig5为TridentNet模块分支数的实验
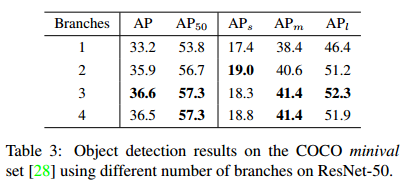
2)下图Fig6为TridentNet各分支检测结果的评估

3)下图Fig7为TridentNet中间分支在coco测试的结果

4)下图Fig8为TridentNet与其他网络在coco数据集上的比较

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











