






文章目录
Scale-Aware Trident Networks for Object Detection
Abstract
Scale variation是目标检测中的一个关键挑战。在这项工作中,我们首先进行了一项controlled实验,以研究感受野在目标检测的 scale variation中的影响。基于探索实验的结果,我们提出了一种新颖的三叉网络(TridentNet),旨在生成具有uniform representational能力的scale-specif的特征图。我们构建了一个并行的多分支架构,每个分支共享相同的 transformation parameters,但具有不同的感受野。然后,我们采用一种scale-aware的训练方案,通过对适当尺度的目标实例进行采样进行特定分支的训练。三叉网络的fast approximation version 可以在不增加任何额外参数和计算成本的情况下显著改善性能。在COCO数据集上,我们的TridentNet使用ResNet-101主干网络实现了48.4的mAP,达到了单模型的最佳结果。
1. Introduction
近年来,深度卷积神经网络(CNNs)在目标检测方面取得了巨大的成功。通常,这些基于CNN的方法可以大致分为两类:one-stage方法,如YOLO或SSD,直接利用前向传播CNN来预测bounding boxes of interest;而two-stage方法,如Faster R-CNN 或R-FCN,首先生成 proposals,然后利用从CNN中提取的区域特征进行进一步的精炼。然而,这两种方法都面临着一个核心问题,即如何处理scale variation。目标实例的尺度可能在很大范围内变化,这会阻碍检测器,尤其是那些非常小或非常大的目标实例。
为了解决尺度变化的问题,一种直观的方法是利用多尺度图像金字塔,这在hand-crafted特征方法和当前的深度CNN方法中都很流行(如图1(a)所示)。deep detectors可以从多尺度的训练和测试中受益。为了避免训练极端尺度的目标(较小/较大的目标在较小/较大的尺度上),SNIP 提出了一种尺度归一化方法,选择性地在每个图像尺度上训练适当大小的目标。然而,推理时间的增加使得图像金字塔方法在实际应用中不太理想。
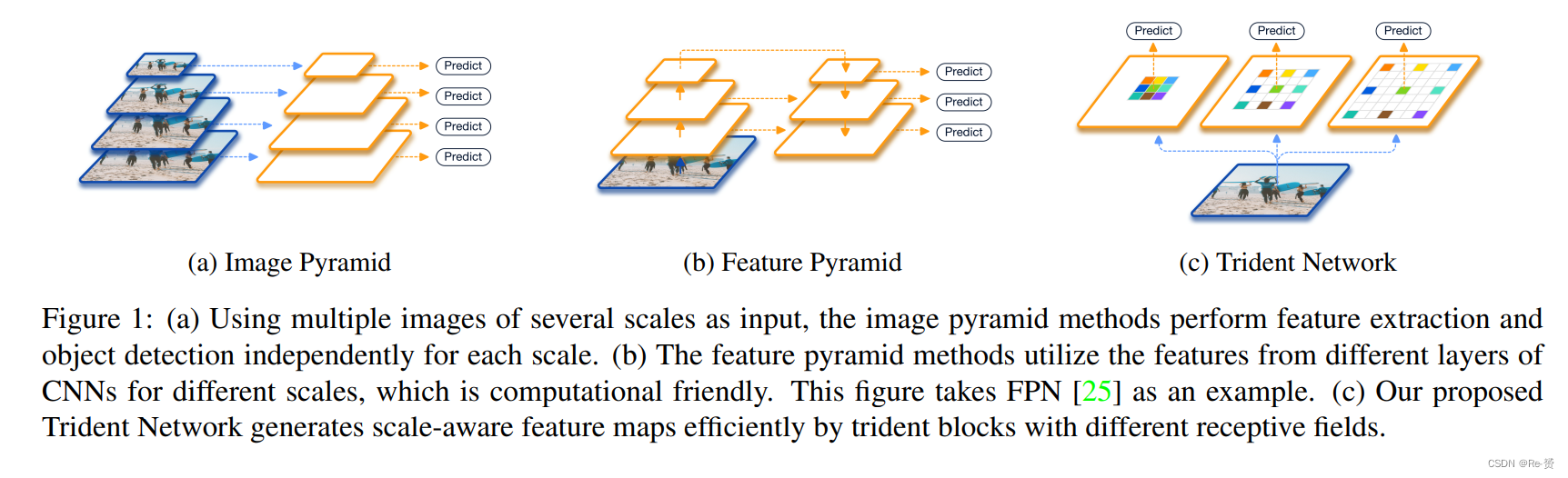
另一方面,有一些努力致力于利用网络内部的特征金字塔来近似图像金字塔,从而减少计算成本。通过从附近的尺度层插值一些特征通道,构建了一个快速的目标检测特征金字塔。在深度学习时代,这种近似变得更加容易。SSD 利用来自不同层的多尺度特征图,在每个特征层上检测不同尺度的目标。为了弥补低层特征中缺乏语义信息的问题,FPN (图1(b))进一步增加了自顶向下的路径和横向连接,将强的语义信息融入高层特征。然而,FPN主干的不同levels提取了不同尺度的region features,而这些levels又是由不同的参数集生成的。这使得特征金字塔对图像金字塔来说并不是一个令人满意的替代方法。
image pyramid和feature pyramid都有一个共同的动机,即模型应该具有不同感受野,以适应不同尺度的目标。尽管图像金字塔方法效率较低,但它充分利用了模型的representational power 来平等地处理所有尺度的目标。相比之下,特征金字塔方法生成多层级特征,从而在不同尺度上牺牲了feature consistency。这导致有效训练数据减少,并且每个尺度存在过拟合的风险。本论文的目标是通过高效地创建具有统一表示能力的特征,从两种方法中获得最佳效果。
我们不像image pyramid那样输入多尺度的图像,而是提出了一种新颖的网络结构来适应不同尺度的目标。具体而言,我们使用所提出的trident blocks在不同尺度上创建多个scale-specific的特征图,如图1(c)所示。借助dilated convolutions的帮助,trident blocks的不同分支具有相同的网络结构和共享相同的参数,但具有不同的感受野。此外,为了避免训练极端尺度的目标,我们采用scale-aware的训练方案,使每个分支具有与其感受野相匹配的scale range。最后,由于整个多分支网络通过权重共享,我们在推理过程中可以用一个 major branch近似整个TridentNet。这种近似只会带来微小的性能下降。因此,它可以在不牺牲推理速度的情况下显著改善single-scale baseline。
总结一下,本文的贡献如下:
-
我们展示了关于receptive field在尺度变化中的影响。据我们所知,我们是第一个在目标检测任务上设计controlled experiments来探索感受野的研究。
-
我们提出了一种新颖的Trident Network,用于解决目标检测中的尺度变化问题。通过multibranch structure 和scale-aware training,TridentNet可以生成具有uniform representational的尺度特定的特征图。
-
我们通过权重共享的trident-block,提出了一种fast approximation版本TridentNet Fast,仅使用一个主要分支,在推理过程中不引入任何额外的参数和计算成本。
-
我们通过全面的ablation studies验证了我们方法的有效性,将其应用于标准的COCO基准测试。与最先进的方法相比,我们提出的方法使用ResNet-101主干网络的single model达到了48.4的mAP。
2. Related Work
Methods for handling scale variation 在目标检测中,最具挑战性的问题之一是目标实例之间的scale variation较大,这影响了检测器的准确性。multi-scale image pyramid是一种常见的方法。基于图像金字塔策略,SNIP提出了一种尺度归一化方法,用于在多尺度训练中将目标训练在所需的尺度范围内的每个分辨率上。为了更高效地进行多尺度训练,SNIPER 仅在训练过程中选择围绕真实目标实例和采样的背景区域的上下文区域。然而,SNIP和SNIPER仍然面临不可避免的推理时间增加问题。
有些方法不使用多个图像作为输入,而是利用不同spatial resolutions的多层级特征来减轻尺度变化。像HyperNet 和ION 这样的方法将不同层级的低级和高级特征连接在一起,生成更好的特征图用于预测。由于不同层级的特征通常具有不同的分辨率,因此在融合多层级特征之前需要设计特定的归一化或转换操作。而SSD和MSCNN则在多个层级上进行目标检测,对不同尺度的目标没有进行特征融合。TDM 和FPN 进一步引入自顶向下的路径和横向连接来增强底层特征的语义表示。PANet通过额外的自底向上路径增强FPN中的特征层次,并提出adaptive feature pooling来聚合来自所有层级的特征以进行更好的预测。而我们提出的TridentNet不使用来自不同层级的特征,而是通过多个并行分支生成scale-specific的特征,从而赋予我们的网络在不同尺度目标上相同的表示能力。
Dilated convolution 扩张卷积(又称为Atrous卷积)通过在sparsely sampled的位置上执行卷积,从而使用 original weights 扩大卷积核,从而增加感受野的大小而无需额外的计算成本。扩张卷积在语义分割中被广泛用于融入大范围的上下文信息。在目标检测领域,DetNet 设计了一个特定的检测主干网络,使用扩张卷积来保持空间分辨率并扩大感受野。Deformable convolution通过自适应地学习采样位置进一步推广了扩张卷积。在我们的工作中,我们在多分支架构中使用不同dilation rates的扩张卷积,以适应不同尺度的目标的感受野。
3. Investigation of Receptive Field
backbone网络的设计可能会影响目标检测器的性能,包括下采样率、网络深度和感受野。已有的一些研究已经讨论了它们的影响。前两个因素的影响是直观的:更深的网络和较低的下采样率可能会增加复杂性,但通常有利于检测任务。然而,据我们所知,还没有先前的研究仅研究感受野的影响。
为了研究感受野对不同尺度目标检测的影响,我们用其 dilated variants替换骨干网络中的一些卷积操作。我们使用不同的dilation rates来控制网络的感受野大小。
扩张卷积使用扩张率ds,在consecutive filter values之间插入ds-1个零,从而扩大卷积核的大小而不增加参数和计算量。具体来说,一个dilated的3×3卷积可以具有与3 + 2(ds − 1)大小卷积核相同的感受野。假设当前特征图的总stride为s,那么扩张率为ds的扩张卷积可以将网络的感受野增加2(ds−1)s。因此,如果我们将n个卷积层修改为ds dilation rate,感受野可以增加2(ds − 1)sn。
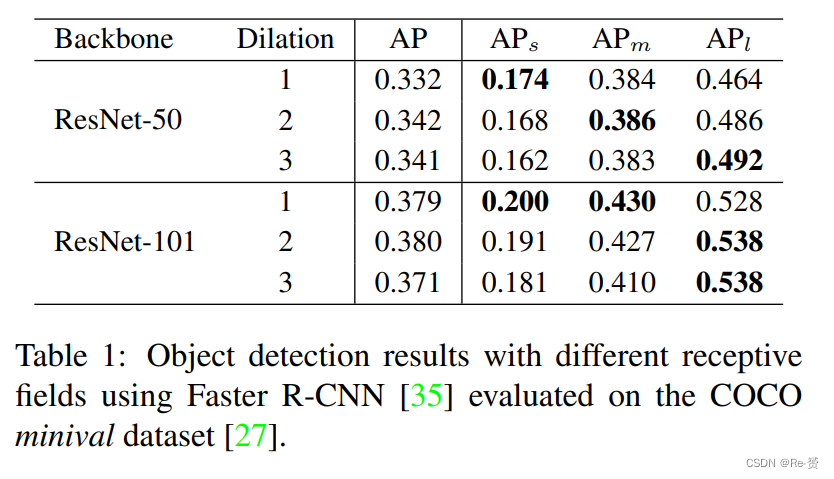
我们在COCO 数据集上使用Faster RCNN检测器和ResNet-C4作为backbone进行了初步实验。结果分别在所有对象和小、中、大尺寸对象上以COCO风格的mmAP进行报告。我们使用ResNet-50和ResNet-101作为骨干网络,并将3×3卷积中conv4阶段的残差块的扩张率ds从1变化到3。
表1总结了实验结果。我们可以发现,随着感受野的增加(即larger dilation rate),在ResNet-50和ResNet-101上检测器在小目标上的性能持续下降。然而,对于大目标,随着感受野的增大,检测器的性能有所提升。
以上发现表明:
- 1.不同尺度对象的检测性能受感受野影响。最适合的感受野与scale of objects强相关。
- 2.尽管ResNet-101在理论上具有足够大的感受野来覆盖COCO中大对象(大于96×96分辨率),但在扩大扩张率时,大对象的性能仍然可以改进。我们假设检测网络的 effective receptive field需要在小对象和大对象之间取得平衡。增加扩张率通过强调大对象来扩大有效感受野,从而影响了小对象的性能。
The aforementioned experiments motivate us to adapt the receptive field for objects of different scales as detailed in the next section.
4. Trident Network
在这一部分中,我们描述了用于目标检测的 scale-aware Trident网络(TridentNet)。TridentNet由权重共享的trident blocks和经过精心设计的 scale-aware training scheme组成。最后,我们还介绍了TridentNet的推理细节,包括一个fast inference approximation method。
4.1. Network Structure
我们的目标是继承不同receptivefield sizes的优点,并避免目标检测网络的drawbacks 。为了实现这一目标,我们提出了一种新颖的Trident架构,如图2所示。具体而言,我们的方法以single scale image作为输入,然后通过并行分支创建scale-specific的特征图,其中卷积操作共享相同的参数,但具有不同的dilation rates。
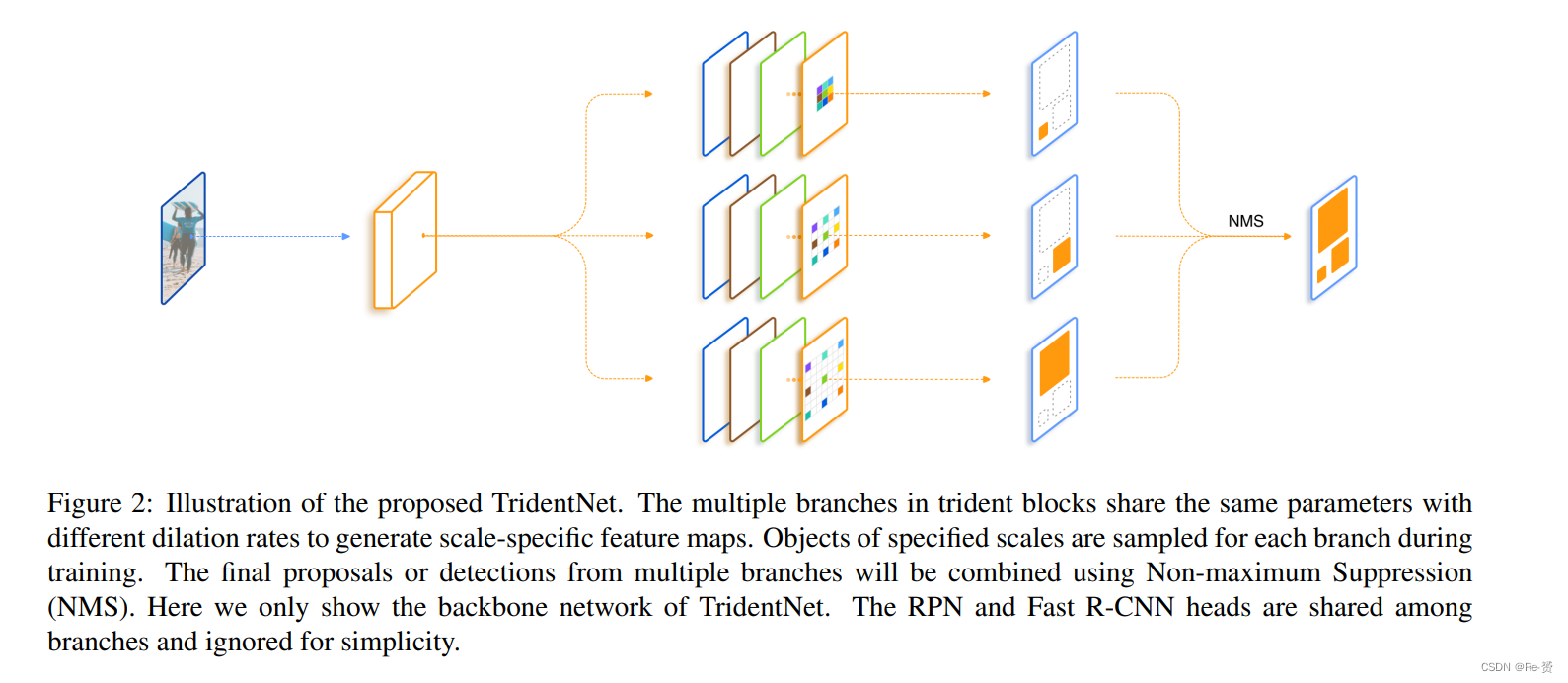
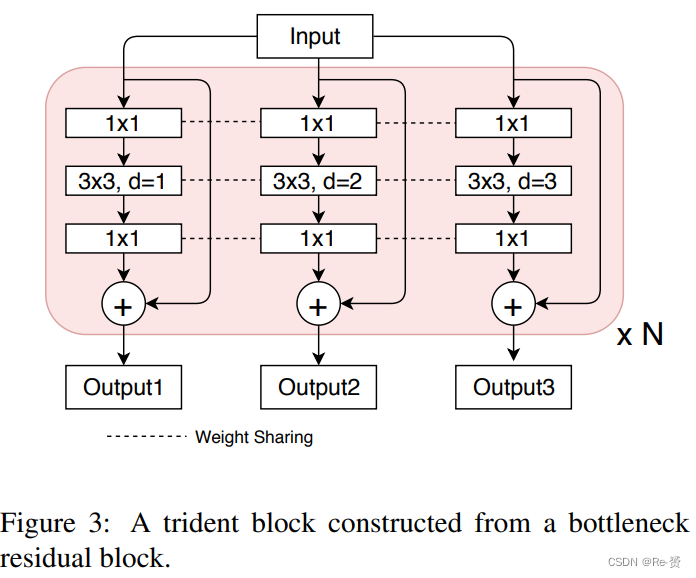
Multi-branch Block 我们通过将一些卷积块替换为所提出的trident blocks来构建TridentNet,这些块位于检测器的backbone网络中。一个trident blocks由多个并行分支组成,每个分支与原始的卷积块具有相同的结构,只是扩张率不同。
以ResNet为例,对于一个采用bottleneck style的单个残差块,它由三个卷积组成,分别是1×1、3×3和1×1的卷积,相应的trident blocks则是由多个并行的残差块构成,其中3×3卷积具有不同的扩张率,如图3所示。堆叠trident blocks使我们能够以类似于第3节中的实验方式有效地控制不同分支的感受野。通常情况下,我们将骨干网络的最后一阶段的块替换为trident blocks,因为较大的strides会导致所需的感受野差异更大。详细的设计选择可以参考第5.2节。
Weight sharing among branches 我们的 multi-branch trident block 带来的一个直接问题是引入了几倍的参数,这可能会导致过拟合。幸运的是,不同的分支共享the same structure(除了扩张率),从而使权重共享变得简单。在这项工作中,我们共享所有分支及其相关的RPN和R-CNN头部的权重,只改变每个分支的扩张率。
权重共享的优势有三个方面。首先,它减少了参数的数量,使得TridentNet与原始检测器相比不需要额外的参数。它也与我们的动机相呼应,即objects of different scales should go through a uniform transformation with the same representational power。最后一个点是,可以使用来自所有分支的更多目标样本来训练 transformation parameters 。换句话说,在不同的感受野下,不同尺度范围内的目标使用相同的参数进行训练。
4.2. Scale-aware Training Scheme
TridentNet架构根据预定义的扩张率生成尺度特定的特征图。然而,表1中由于尺度不匹配(例如,小目标在扩张率过大的分支上)而导致的性能下降仍然存在于每个分支中。因此,在不同的分支上检测不同尺度的目标是natural的。为此,我们提出了一种scale-aware的训练方案,以提高每个分支的尺度感知能力,并避免在不匹配的分支上训练极端尺度的目标。
类似于SNIP ,我们为每个分支i定义一个有效范围[li,ui]。在训练过程中,我们只选择每个分支相应的有效范围内的 proposals and ground truth boxes。具体而言,对于输入图像(未调整大小)上的一个区域感兴趣(RoI)的宽度w和高度h,当满足以下条件时,它对于分支i是有效的:
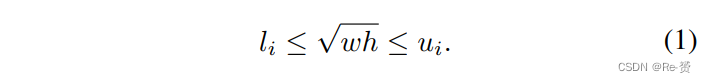
这种scale-aware的训练方案可以应用于RPN和R-CNN。对于RPN,我们根据公式1为每个分支选择与其有效范围相符的 ground truth boxes。同样,在训练R-CNN期间,我们删除所有对于每个分支无效的proposals。
4.3. Inference and Approximation
在推理阶段,我们为所有分支生成检测结果,过滤掉超出每个分支有效范围的边界框。然后,我们使用NMS或soft-NMS 来合并多个分支的检测输出,并获得最终的结果。这样做可以确保最终的检测结果包含了不同尺度目标的检测结果,并且有效避免了因尺度不匹配而导致的性能下降。
Fast Inference Approximation TridentNet的一个主要缺点是由于其分支结构而导致的推理速度较慢。因此,我们提出了TridentNet Fast,这是TridentNet的一个快速近似版本,在推理阶段只使用一个分支。对于Figure 2中的three-branch网络,我们选择使用中间分支进行推理,因为其有效范围涵盖了大尺寸和小尺寸的目标。通过这种方式,TridentNet Fast在推理阶段不会增加额外的时间开销。令人惊讶的是,我们发现这种近似方法与原始的TridentNet相比,仅会略微降低性能。这可能是因为我们的weight-sharing 策略,通过这种方式,多分支训练等同于在网络内进行尺度增强。有关TridentNet Fast的详细剖析可在第5.3节中找到。
5. Experiments
在本节中,我们在COCO数据集上进行实验。我们在80k训练图像和35k验证图像的子集上训练模型,并在5k验证图像(minival)上进行评估。我们还在20k测试图像(test-dev)上报告最终结果。首先,我们在第5.1节中描述了TridentNet的实现细节和训练设置。然后,在第5.2节中进行了全面的ablation experiments,以验证所提出的方法。最后,第5.4节将TridentNet与测试集上的最新方法进行比较。
5.1. Implementation Details
我们在MXNet中重新实现了Faster R-CNN作为我们的baseline方法。与其他标准检测器一样,网络的骨干在ImageNet上进行了预训练。stem、第一个残差阶段和所有BN(Batch Normalization)参数都被冻结。输入图像被调整为800像素的。在训练期间采用随机水平翻转。模型在8个GPU上的批量大小为16进行训练。默认情况下,模型在12个周期内进行训练,学习率从0.02开始,并在第8和第10个周期后减小0.1倍。2×或3×训练方案意味着相应地将总训练周期和学习率计划翻倍或翻三倍。我们采用ResNet 中的conv4阶段作为backbone feature map,并将conv5阶段作为baseline和TridentNet中的R-CNN头。除非另有说明,否则我们默认采用三个分支作为TridentNet的结构。对于TridentNet中的每个分支,在NMS(非极大抑制)之前/之后保留前12000/500个proposals,并采样128个ROI(感兴趣区域)进行训练。扩张率分别设置为1、2和3。在为TridentNet采用尺度感知的训练方案时,我们将三个分支的有效范围设置为[0, 90]、[30, 160]和[90, ∞]。
在评估中,我们得到标准的COCO平均精度(AP),以及AP50/AP75。我们还得到COCO风格的APm和APl,分别是小尺寸(小于32×32)、中尺寸(从32×32到96×96)和大尺寸(大于96×96)的目标的AP。
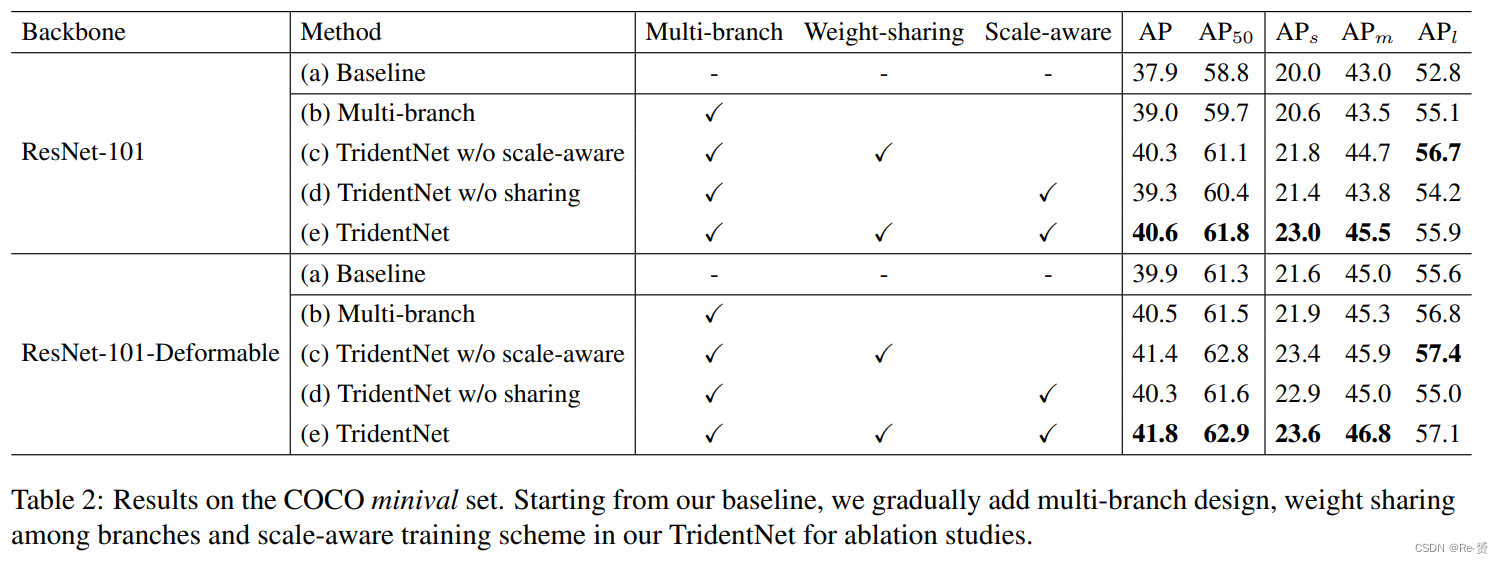
5.2. Ablation Studies && 5.4. Comparison with State-of-the-Arts
略过
5.3. Fast Inference Approximation
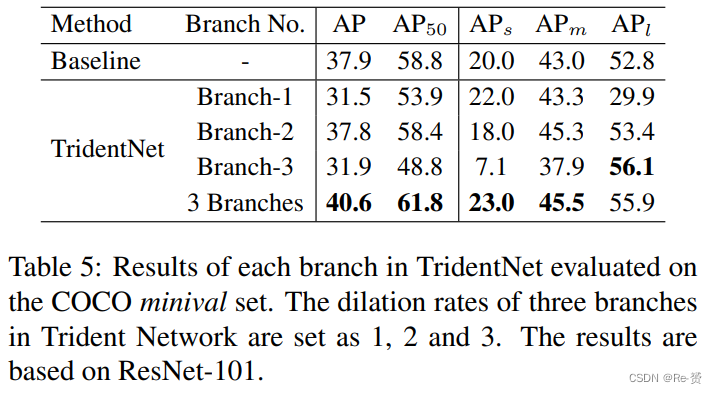
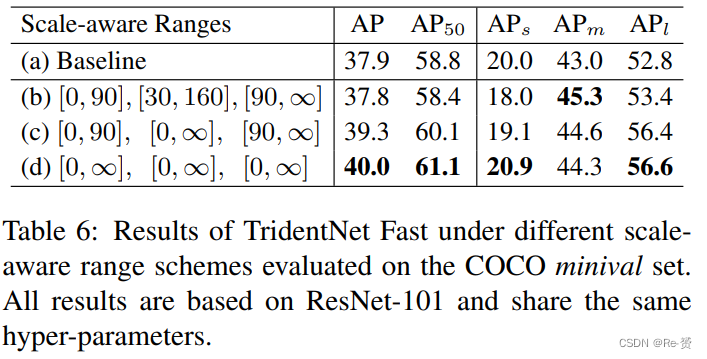
为了减少TridentNet的推理时间,我们提出了TridentNet Fast,该方法在推理阶段使用单个主要分支来近似三个分支的结果。正如表5所示,第二个分支是作为主要分支的自然选择,因为它的尺度感知范围覆盖了大多数目标。我们在表6中研究了尺度感知训练中 scale-aware ranges的影响。如表6©所示,通过将主要分支的尺度感知范围扩大到包含所有尺度的目标,Trident Fast的性能比默认的尺度感知范围设置提高了1.5个AP。此外,将所有三个分支的尺度感知范围扩展到达到了最佳性能,达到了40.0个AP,接近原始TridentNet的结果40.6个AP。我们假设这可能是由于权重共享策略。由于主要分支的权重在其他分支上共享,将所有分支在尺度不可知的方案下训练等同于进行网络内的多尺度增强。
6. Conclusion
In this paper, we present a simple object detection method called Trident Network to build in-network scalespecific feature maps with the uniform representational power. A scale-aware training scheme is adopted for our multi-branch architecture to equip each branch with the specialized ability for corresponding scales. The fast inference method with the major branch makes TridentNet achieve significant improvements over baseline methods without any extra parameters and computations.
















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









