







 这篇论文介绍了一种新的方法,将LLM生成的高质量文本作为记忆扩展,提出了Selfmem框架,通过结合检索结果和自身的生成输出,提升了文本生成的性能。论文还详细阐述了检索增强的Generator、MemorySelector以及两种Generator模式的应用。
这篇论文介绍了一种新的方法,将LLM生成的高质量文本作为记忆扩展,提出了Selfmem框架,通过结合检索结果和自身的生成输出,提升了文本生成的性能。论文还详细阐述了检索增强的Generator、MemorySelector以及两种Generator模式的应用。
论文:Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory
⭐⭐⭐⭐
NeurIPS 2023,北大
一、论文速读
在以为 RAG 中,LLM 使用 user query 和检索到的文档(本文中称之为 memory)作为输入来生成回复。然后,这样检索到的 memory 是来自于一个固定的 corpus 并受限于 corpus 的质量,这样有界的 memory 明显限制了 memory-augmented generation model 的效果,因此本文提出:better generation also prompts better memory,意思也就是说,LLM 所生成的好的 generation 也可以作为一种好的 memory,从而将有界的 memory 推广到了无界中。
因此在这篇论文扩展了 LLM 输入的上下文,提出 LLM Generator 的输入应该是 user query + memory,其中 memory 既包含检索到的文档,也包含 LLM 自己的输出。这种将 generation 也作为 memory 的思路,是本文重点强调的创新点。
另外,本论文还抽象了 RAG 中各个概念,将 RAG 用了在诸如机器翻译等多个场景中。
本论文提出 Selfmem 框架:
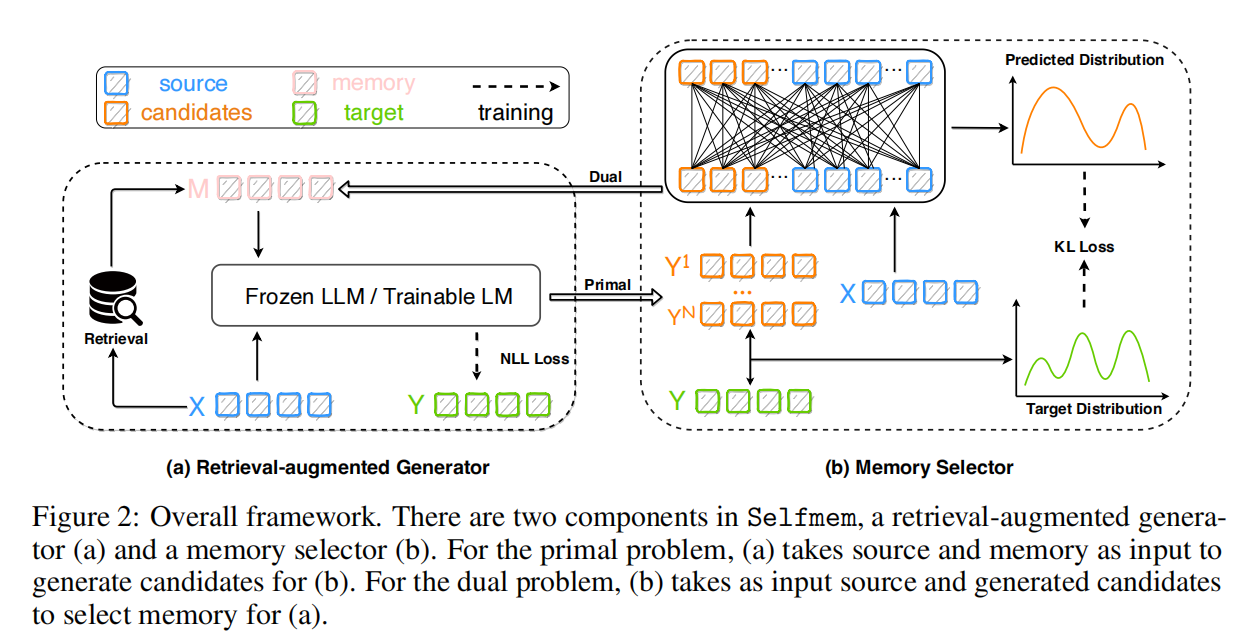
上图以机器翻译的场景为例,训练数据包含 source X X X 和 target Y Y Y。Selfmem 框架包含两个部分:
- 检索增强的 Generator:它拿到 source X X X,调用 retriever 进行检索,形成 memory M M M。然后把 memory M M M 和 source X X X 输入给 LM 得到生成多个候选回复 candidates。
- Memory Selector:Selector 接收到前面 LM 生成的多个 candidates,将其与 source X X X 做计算,根据某个评价指标 metric(比如 BLEU)从 candidates 中选出一个 candidate 作为选择结果,然后把这个选择结果输送给 Generator,这样下一次 Generator 部分在形成 memory 时,会把 candidate 选择结果和 retrieval 结果一同用于形成 memory 作为下一轮 LM 的输入。
可以看到,Selfmem 的关键创新就是,改造了 RAG 框架中输入给 LLM 的上下文,这个上下文不仅仅包含了检索到的文档,还包含了 LLM 在上一轮中生成的回复,这个回复是由 Memory Selector 从多个候选回复中根据 metric 选出来的一个。
二、实现细节
2.1 检索增强的 Generator
文中提到,Generator 既可以是 frozen LLM,也可以是 trainable LM。对于一个任务,输入是 x x x,输出是 y y y,在不同的下游任务中,输入和输出的含义不同,比如 summarization 任务中,就是 (document, summary),在对话任务中,就是 (context, response),在机器翻译中,就是 (source, target)。
Generator 的输入包含任务的输入 x x x 和 memory m m m,为了连接 x x x 和 m m m,其架构可以有两种:
- Joint-Encoder:将 x x x 和 m m m join 成一个 sequence 做 encode: e n c o d e r ( x [ S E P ] m ) encoder(x [SEP] m) encoder(x[SEP]m),然后再解码。
- Dual-Encoder:使用两个 encoder —— SourceEncoder 和 MemoryEncoder —— 分别对 x x x 和 m m m 进行编码,并将两个编码做 Cross Attention 后再解码。
两种架构都可以统一为 Transformer 的结构封装为一个 block,然后使用 NLL loss 做 optimize。
2.2 Memory Selector
Memory Selector 的目标就是从 LM 生成的多个 candidates 中,按照某个特定的 metric 从中选出一个作为选择的结果,用于送给 Generator 形成下一轮的 memory。
具体来说,内存选择器的目标是从生成器产生的候选池中选择一个最佳候选项作为新的记忆。为了做到这一点,内存选择器需要学习一个评分函数,该函数能够根据某些性能指标(如BLEU、ROUGE等)对候选项进行评分。在训练内存选择器时,KL散度被用来量化内存选择器的预测分布与真实分布之间的差异:
- 真实分布:这是根据性能指标(如 BLEU 分数)得到的候选项的分布,其中每个候选项的概率与其性能指标的分数成比例。
- 预测分布:这是内存选择器对候选项的预测分布。
通过最小化 KL 散度损失,内存选择器学习如何根据性能指标更准确地对候选项进行评分,从而选择更好的记忆用于下一轮的生成过程。
2.3 Generator 的两种 mode
Generator 有两种 mode:
- hypothesis mode:只生成一个 output,这用于 inference 或者 system evaluation 时。
- candidate mode:会生成多个 candiates,这用于训练 memory selector 和 memory selection 的时候。
总结
Selfmem 是一个让生成模型利用自己的输出提升自己来实现检索增强文本生成的通用框架,并将其用在了多个任务场景中。















 2507
2507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









