







1、数据集说明
从给的Sort_1000pics数据集中了解到,该数据集中包括10类图片,对图片进行查看了解到,0-99对应与人(people);100-199对应与沙滩(beaches);200-299对应与建筑(buildings);300-399对应与大卡车(trucks);400-499对应与恐龙(dinosaurs);500-599对应与大象(elephants);600-699对应与花朵(flowers);700-799对应与马(horses);800-899对应与山峰(mountains);900-999对应与食品(food)。
2、 算法介绍
数据预处理:将数据集按照类别进行分组处理,分别对应的目录为0-9,读取图片,保存数据集;
将数据集和标签按照相同的种子进行打乱处理,然后按照标签的比例进行分割数据集,80%作为训练集(训练集中的10%作为验证集,查看是否过拟合),20%作为测试集。
构建CNN模型,这里是基于TensorFlow2.0进行搭建的,具体代码如图所示:

结构视图如下图所示:

其中包括输入层(32*32的图像,3通道),两个卷积层,1个池化层,重复一次,展平经过全连接层,最后输出层,除了输出层的激活函数是softmax,其他的都是relu。
模型训练,将处理后数据经过模型训练
模型预测,将处理后的测试集数据经过模型进行预测,分别输出模型对于测试集的召回率,精确率和F1测度。
根据预测结果和实际结果构建混淆矩阵。
3、结果分析
(1)召回率、准确率与F1测度
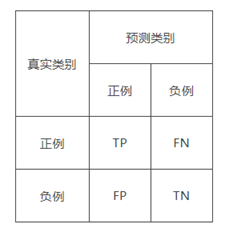
对于二分类问题中,可将样例根据其真实类别和分类器预测类别划分为:
- 真正例(True Positive,TP):真实类别为正例,预测类别为正例。
- 假正例(False Positive,FP):真实类别为负例,预测类别为正例。
- 假负例(False Negative,FN):真实类别为正例,预测类别为负例。
- 真负例(True Negative,TN):真实类别为负例,预测类别为负例。
然后可以构建混淆矩阵如下表所示:
准确率的计算公式为(Precision,P):表示在所有样本中预测正确的概率
P=TPTP+FP
召回率的计算公式为(Recall,R):表示在所有正例中预测为正例的概率
R=TPTP+FN
F1测度的计算公式为:
F1=2*P*RP+R
对于本实例中的多分类问题,也可以建立混淆矩阵,比如真实是人的正例中,实际预测为人的为TP,其余预测结果都为FN
(2)实验结果:

模型结构图

CNN模型分类预测指标图


(3)结果分析
从CNN模型的召回率、精确率和F1测度可以看出该模型相较于bytes等模型,有稍微的提升。从海滩的预测中我们可以发现它的正确率较低,经常被误认为山脉,这是由于海滩的图片中经常有大山的出现,同样也经常会被预测为人。这是由于抽取的特征向量对该图像不够抽象或泛化。
从混淆矩阵我们发现对于卡车、恐龙与大象等特征明显的图片时,它的预测效果就优于其他种类。
同时我们也发现如果训练参数过多或者训练次数过多,容易导致模型过拟合,这是由于数据集的数据有限,学习的特征过多。所以这里我使用了验证集进行查看是否数据过拟合(在训练集上的效果好,验证集上的效果差)















 2164
2164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









