







新智元报道
编辑:乔杨
如何判断一个 AI 模型是否属于开源阵营?开源 or 闭源,到底哪种系统才更安全?最近,两位荷兰学者发表的一篇 ACM FAccT 论文给出了富有卓见的回答。
当我们在谈论「开源」时,我们到底在谈论什么?
在软件时代,「开源」的概念并不模糊。我们可以非常清楚自信地说,Linux 是开源的,Windows 是闭源的。
更具体地说,曾经的「开源」是指能够访问、修改源代码,并对程序的使用或发行不加限制。
但进入 AI 时代,这个概念变得愈发模糊。关于人工智能模型的「开源」到底如何界定,社区和行业专家仍未达成一致。
成立于 1998 年的 Open Source Initiative(OSI)就始终在主持一个在线论坛,方便对开源 AI 模型的定义进行公开讨论。
他们在官方网站上表示:「对于开源代码和使用许可的传统观点不再适用于 AI 组件,已经不足以保证使用、研究、共享和修改系统的自由。」
OSI 的开源 AI 定义草案从 2022 年发起,已经修改到了版本 0.0.8,最新一版中宣称,开源 AI 系统应该提供以下三个方面的信息:
-
训练数据的详细信息,包括数据集、数据来源、数据范围和特征、获取和数据选择方式、标注程序、数据清理方法等,以便技术人员可以用相同或相似的数据复现模型的效果
-
用于训练和运行的源代码,包括支持库以及预处理、训练、验证和测试、推理、模型架构等多步骤的代码
-
模型参数,包括训练阶段中间关键的检查点(checkpoint)以及最终的优化器状态
这相比我们平常认知中的「开放源代码」已经扩展了不少内容。
最近,荷兰的两位学者也注意到了 AI 行业「开源」这个定义的模糊性,于是发表了一篇论文讨论这个问题。
文章已被 ACM 下辖的 FAccT 会议(Fairness, Accountability and Transparency)接收,并得到了 Nature 的报道。

本文创建了一个排行榜,用于识别最「开放」和最「不开放」的模型,并谴责了大公司「挂羊头卖狗肉」的行为。
共同一作 Dingemanse 表示,一些大公司声称自己的模型开源并从中获益,却试图尽可能少地披露模型信息。论文将这种行为幽默地比喻为 open-washing(源于「洗白」white-washing 一词)。
这篇论文也得到了同行的认可,Mozilla 基金会可信 AI 方面的高级研究员 Abeba Birhane 称赞这项研究「戳破了当前开源讨论中的大量炒作和废话」。
大公司 open-washing,开源≠开放
给模型贴上「开源」的标签,不仅对社区和开发者有不可抗拒的诱惑力,也能在法律和商业层面带来丰厚回报。
将模型开源的行为,似乎让研发团队显得更加严谨、透明,而且看起来不那么钻营于短期利益,而是致力于整个 AI 行业的长远发展。
此外,欧盟今年通过的人工智能法案也对开源的通用模型有一定的豁免,没有那么高的透明度要求,让它们承担「较少且尚未定义」的义务。
在这样的背景下,许多 LLM 都是顶着「开源」光环出道的,标志之一就是使用博客文章发布模型。
论文发现,大公司发布模型的博客文章中会包含精心设计的表格,并在 MMLU、HumanEval、TruthQA 等基准上进行打分测试。
这让发布者保留了科学研究的光环,但又巧妙避免了真正发布科研论文时需要面临的详细审查与同行评审,从而不必被迫披露不想公开的数据。
那么到底应该用什么样的标准定义「开源」?
论文提出,鉴于 GenAI 系统的复杂性,最有效的方法将是把「开放性」视为一个复合且分级的概念。
「复合」体现在由多个因素组成,其中每个因素都可以单独进行评估;「分级」是因为每个维度都能以不同的程度实现开放,不能赋以「开放/封闭」这样简单的二元划分。
于是,对 46 个声称「开源」或「开放」的大模型以及众多小型模型,作者进行了多维度的评估与对比,在 14 个参数上进行了三分类:开放(open)、部分开放(partially open)还是封闭(closed)。
专注于开放技术的非营利公司 OpenUK 的 CEO 认为,在分析开放程度时,使用这种滑动尺度取代简单粗暴的分类,是更加实际且有用的方法。
14 个参数涵盖了 3 个方面——
-
可用性:包括代码、数据、模型权重、指令微调的数据、微调后的权重
-
文档:源代码、模型架构的说明文档,模型卡(model card)、数据表(data sheet)、是否发布了预印本和经过同行评审的论文
-
访问与许可:是否把模型放到公开代码库上(如 PyPI)作为软件包发行,是否提供 API 访问,以及模型的许可证

绿色表示开放,黄色表示部分开放,红色表示封闭
评估结果
于是有了下面这种文本生成模型的开放性概览图,几乎囊括了你能叫上来名字的所有模型。
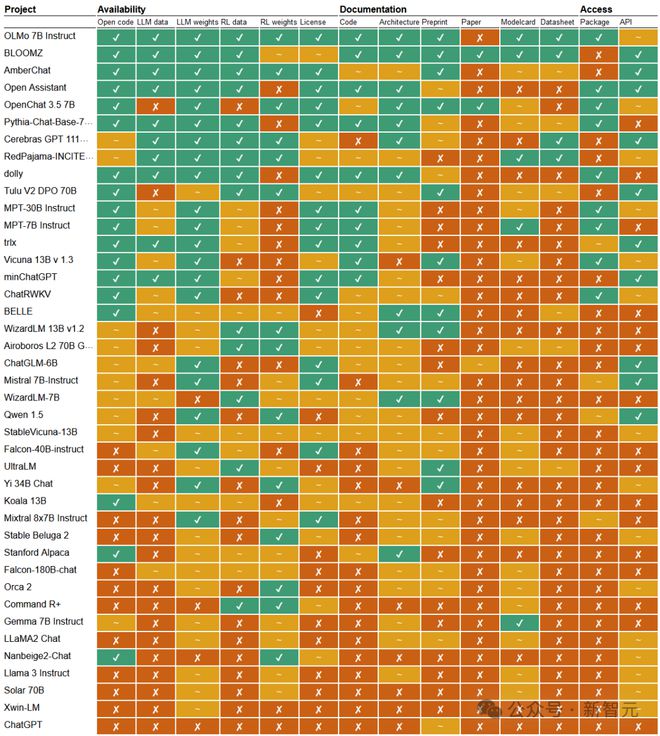
可以看到,前十名中除了 BLOOMZ 和 OLMo,几乎没有我们认识的模型。这是因为较小的团队希望通过高标准的公开和透明,来弥补模型在规模和性能方面的不足。
Allen AI 发布的 OLMo 系列以及 BigScience 的 Bloom 可以说是开源的典范,排在前两名,接近完全开放的状态。
这两个模型的研发团队都在竭尽所能地提供训练数据、代码、文档和整个模型的 pipeline。值得注意的是,Allen AI 与 Big Science 都是非营利机构。

这种做法实在是少数中的少数。相比之下,三分之一的系统选择只提供模型权重,但其他方面几乎不公开任何细节。
那么科技巨头的表现如何呢?
ChatGPT 无疑排名倒数第一,Cohere、谷歌、微软等大型玩家都吊在车尾,包括被 Meta 包装成开源模型的 LLaMA。
在 14 个维度中,有两项格外让人担忧:一是所有模型几乎都没有发布严谨的、经过同行评审的论文,二是训练数据的整体不透明性。
除了文本模型,论文也对文生图模型进行了评估。

在这个排行榜上,OpenAI 的 DALL-E 倒数第一也在意料之内,但 Stable Diffusion 的表现尤为突出,也几乎公开了所有信息,相比文本模型榜首的 OLMo 开放程度更高。
为什么论文只给概览图不给评分?是作者在水工作量吗?
完全不是。对于「评分」这个问题,论文有进一步的考量和阐述。
对同一个概览图结果,用不同的派生方法和权重,你就能得到不同的评分。
换言之,评分是可以被操纵的。
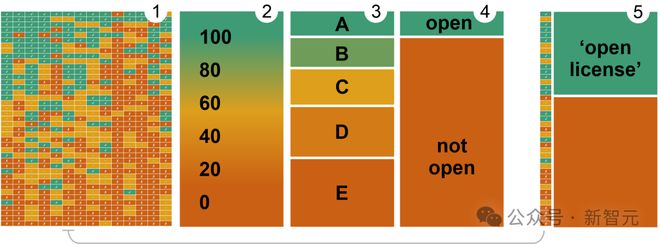
给所有维度分配相同的权重,并分别用 1 分、0.5 分、0 分赋给开放、部分开放、封闭三个结果,就能得到图 2 中基于梯度测量的累积性分数。
想要从分数转换成分类标签,可以设置不同的权重和阈值,用不同的方法划分评分空间就会得到不同的结果,比如图 3 和图4。
我们目前所面临的现实,更加接近上面图 5 中的情况,也就是让唯一的指标「一叶障目」,只通过是否有开放许可证或者是否公开了模型权重,判断系统的开放性。
安全 AGI,需要不盲目的开放
应不应该开放?对这个颇有争议的问题,作者在论文最后给出了自己的观点。
在完全共享模型每个组件和所有数据的「激进式开放」,和被稀释到极其微弱的「顺势疗法开放」(如只公开模型权重)之间,还存在着许多条道路。
完全开放并不是最完美的解决方案,比如 AI 的不正当使用、有害数据的泄露,都是不能忽视的问题。
开放性有不同的程度和维度,对生成式 AI 的监管应该鼓励有意义的开放。比如训练和微调数据,有可能在公众审查和专业审核的目光下变得更加安全。
但是,在大多数情况下,开放依旧要好过封闭,这对于系统的风险分析(公众需要知道)、可审查性(评估人员需要知道)、科学可复现性(科研工作者需要知道)以及法律责任(用户需要知道)都有重要意义。
对评估人员而言,设计更好的评估框架,得出有意义、基于证据、多维度的开放性判断,避免被操纵、偏颇的指标,能够帮助我们做出更好的决定。
参考资料:
The Open Source AI Definition – draft v. 0.0.8 – Open Source Initiative
Not all ‘open source’ AI models are actually open: here’s a ranking
来自: 网易科技

















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











