







图嵌入方法之Node2vec
(Ⅰ)主要思想
node2vec的思想同DeepWalk一样:生成随机游走,对随机游走采样得到(节点,上下文)的组合,然后用处理词向量的方法对这样的组合建模得到网络节点的表示。不过在生成随机游走过程中做了一些创新。
DeepWalk介绍见我另一篇博客
(Ⅱ)核心介绍
Node2vec是DeepWalk的一个改进,只是随机游走的差异很小。它有参数P和Q。参数Q定义了random walk发现图中未发现部分的概率,而参数P定义了random walk返回到前一个节点的概率。参数P控制节点周围微观视图的发现。参数Q控制较大邻域的发现。它可以推断出社区和复杂的依赖关系。
下图中显示了Node2vec中一个随机行走步长的概率。我们只是从红结点走了一步到绿结点。返回到红色节点的概率是1/P,而返回到与前一个(红色)节点没有连接的节点的概率是1/Q。到红结点相邻结点的概率是1。
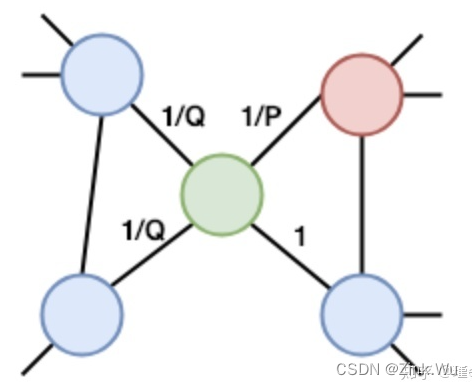
所以node2vec节点采样的概率如上所示。
参数p、q的意义分别如下:
返回概率p:
- 如果 p > max(q,1) ,那么采样会尽量不往回走,对应上图的情况,就是下一个节点不太可能是上一个访问的节点t。
- 如果 p < max(q,1) ,那么采样会更倾向于返回上一个节点,这样就会一直在起始点周围某些节点来回转来转去。
出入参数q:
- 如果 q > 1 ,那么游走会倾向于在起始点周围的节点之间跑,可以反映出一个节点的BFS特性。
- 如果 q < 1 ,那么游走会倾向于往远处跑,反映出DFS特性。
当p=1,q=1时,游走方式就等同于DeepWalk中的随机游走。
(Ⅲ)伪代码赏析

首先看一下算法的参数,图G、表示向量维度d、每个节点生成的游走个数r,游走长度l,上下文的窗口长度k,以及之前提到的p、q参数。
- 根据p、q和之前的公式计算一个节点到它的邻居的转移概率。
- 将这个转移概率加到图G中形成G’。
- walks用来存储随机游走,先初始化为空。
- 外循环r次表示每个节点作为初始节点要生成r个随机游走。
- 然后对图中每个节点。
- 生成一条随机游走walk。
- 将walk添加到walks中保存。
- 然后用SGD的方法对walks进行训练。
第6步中一条walk的生成方式如下:
- 将初始节点u添加进去。
- walk的长度为l,因此还要再循环添加l-1个节点。
- 当前节点设为walk最后添加的节点。
- 找出当前节点的所有邻居节点。
- 根据转移概率采样选择某个邻居s。
- 将该邻居添加到walk中。
https://zhuanlan.zhihu.com/p/100586855
https://zhuanlan.zhihu.com/p/46344860















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









