







 本文详细解析了inode(索引节点)的概念及其在文件系统中的作用,包括inode的结构、inode与文件数据块的关系、inode在Ext2文件系统中的应用,以及进程与文件之间的交互机制。
本文详细解析了inode(索引节点)的概念及其在文件系统中的作用,包括inode的结构、inode与文件数据块的关系、inode在Ext2文件系统中的应用,以及进程与文件之间的交互机制。
一、inode(索引节点)
(1) 理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。“块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
(2) 通常情况下,文件系统会将文件的实际内容和属性分开存放:
- 文件的属性保存在 inode 中(i 节点)中,每个 inode 都有自己的编号。每个文件各占用一个 inode。不仅如此,inode 中还记录着文件数据所在 block 块的编号;
- 文件的实际内容保存在 data block 中(数据块),类似衣柜的隔断,用来真正保存衣物。每个 block 都有属于自己的编号。当文件太大时,可能会占用多个 block 块。
如图所示:文件系统先格式化出 inode 和 block 块,假设某文件的权限和属性信息存放到 inode 4 号位置,这个 inode 记录了实际存储文件数据的 block 号有 4 个,分别为 2、7、13、15,由此,操作系统就能快速地找到文件数据的存储位置。

note:
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,分析 inode 所记录的权限与用户是否符合,找到文件数据所在的block,读出数据。
(3) 联系平时实践,大家格式化硬盘(U盘)时发现有:快速格式化和底层格式化。快速格式化非常快,格式化一个32GB的U盘只要1秒钟,普通格式化格式化速度慢。这两个的差异?其实快速格式化就是只删除了U盘中的硬盘内容管理表(其实就是inode),真正存储的内容没有动。这种格式化的内容是有可能被找回的。
由于inode也占用一定的磁盘空间,所以当inode使用空间用完的时候,即使磁盘仍有存储空间也无法使用!所有当磁盘显示仍有可用空间,但使用时却提示空间不足,就有可能是inode使用完毕所造成的。
(4) inode本质上是一个结构体,定义如下
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
} u;
};可以用stat命令,查看某个文件的inode信息:
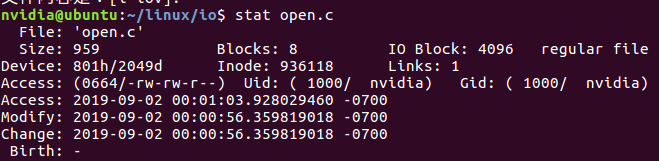
(5)其他
- 每个 inode 大小均固定为 128 bytes;
- 每个文件都仅会占用一个 inode ;
- 承上,因此文件系统能够创建的文件数量与 inode 的数量有关;
二、文件系统对磁盘数据的管理划分

2.1、data block
数据块是真正保存数据原始内容的。
linux EXT2 中所支持的 block 大小有 1k、2k 及 4k 三种。在格式化时 block 的大小就固定了,并都有编号,方便 inode 的记录。
block 的基本限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个 block 内最多只能够放置一个文件的数据;
- 承上,如果文件大于 block 的大小,则一个文件会占用多个 block 数量;
- 承上,若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
2.2、inode table block
从第一章我们知道,一个inode节点固定大小是128bytes,如果一个block是1K,那么一个blk可以存储8个 ionde节点。这些真正存储inode节点有效信息的blk我们称之为 inode table blk。
2.3、inode bitmap和data bitmap
2.1和2.2我们知道,一个物理的blk可以存储用户数据,也可以存储inode节点。那么这些物理blk很多如何进行管理呢?例如怎么知道是否在使用中?我们引入了bitmap的概念。存储这些bitmap的物理blk分别叫做inode bitmap和data bitmap。
2.4、块组描述符
如何inode table block很多,需要占用多个块;或者需要有多个inode bitmap、data bitmap 块。怎么办?我们也选择一个单独的块来记录。这个块就叫做块组描述符吧!
2.5、super blk
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock ,就没有这个 filesystem 了。他记录的信息主要有:
- block 与 inode 的总量
- 未使用与已使用的 inode 、block 数量
- block 与 inode (block 1、2、4k,inode 为 128 、256 bytes)
- filesystem 的挂载时间、最近一次写入时间的时间、最近一次检验磁盘(fsck)的时间等
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0,否则为 1
一般来说, superblock 的大小为 1024bytes
三、inode table的直接索引和间接索引
第一章我们初步了解了通过inode可以索引到具体的data blk,如下图所示。
我们再继续思考一个问题:一个inode大小是 128bytes , 而记录一个 block 号码要花掉 4byte(int) ,假设我一个文件有 400MB 且每个 block 为 4K 时, 那么至少也要十万笔 block 号码的记录呢!这点数据空间是远远不够讲inode和十万笔data blk号相关联的。因此,操作系统讲inode的数据块指针做如下划分:数据块指针数组共有 15 项,前 12 个为直接块指针,后 3 个分别为“一次 间接块指针”、“二次间接块指针”、“三次间接块指针”。
所谓“直接块”,是指该块直接用来存储文件的数据,而“一次间接块”是指该块不存 储数据,而是存储直接块的地址,同样,“二次间接块”存储的是“一次间接块”的地址。 这里所说的块,指的都是物理块。
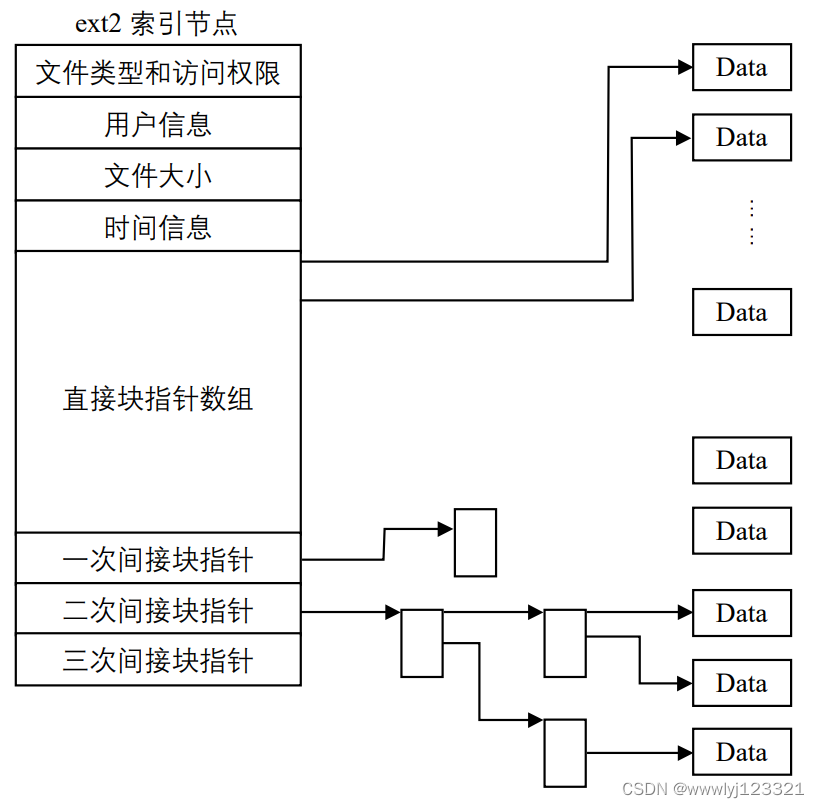
这样子 inode 能够指定多少个 block 呢?我们以较小的 1K block 来说明好了,可以指定的情况如下:
- 12 个直接指向: 12*1K=12K
由于是直接指向,所以总共可记录 12 笔记录,因此总额大小为如上所示;
- 间接: 256*1K=256K
每笔 block 号码的记录会花去 4bytes,因此 1K 的大小能够记录 256 笔记录,因此一个间接可以记录的文件大小如上;
- 双间接: 256*256*1K=2562K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个号码,因此总额大小如上;
- 三间接: 256*256*256*1K=2563K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个第三层,每个第三层可以指定 256 个号码,因此总额大小如上;
- 总额:将直接、间接、双间接、三间接加总,得到 12 + 256 + 256*256 + 256*256*256 (K) = 16GB
此时我们知道当文件系统将 block 格式化为 1K 大小时,能够容纳的最大文件为 16GB,
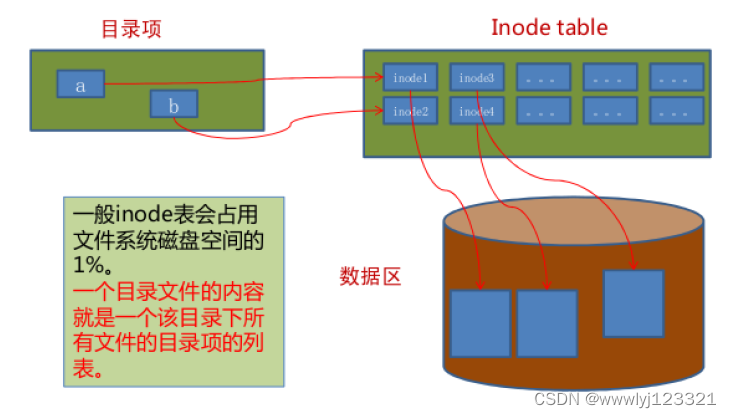
四、Ext2 的目录项及文件的定位
从上述分析我们可以看出,如果要读取文件的内容(data blk),需要先找到inode。那么如何找到inode呢?我们先联想一下:我们调用open函数打开文件的时候,输入的是文件路径。那么文件路径和inode有啥关系呢?
4.1、Ext2 目录项结构
在前面,我们知道了一个普通文件是如何存储的,但还有一个特殊的文件,经常用到的目录,它是如何保存的呢?基于 Linux 一切皆文件的设计思想,目录其实也是个文件,它是由 ext2_dir_entry 这个结构组成的列表。这 个结构是变长的,这样可以减少磁盘空间的浪费,但是,它还是有一定的长度方面的限制, 一是文件名最长只能为 255 个字符。二是尽管文件名长度可以不限(在 255 个字符之内), 但系统自动将之变成 4 的整数倍,不足的地方用 NULL 字符(\0)填充。目录中有文件和子目 录,每一项对应一个 ext2_dir_entry_2。该结构在 include/Linux/ext2_fs.h 中定义如下
struct ext2_dir_entry_2 {
__u32 inode; /* Inode number */
__u16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT2_NAME_LEN]; /* File name */
};- 每个目录文件数据块包含多个目录项,每条目录项包含目录下
- 文件 Inode 号
- 目录项长度
rec_len - 文件名长度
name_len - 文件类型
0:未知1:普通文件2:目录3:*character devicev4:block device5:命名管道6:socket7:符号链接
- 文件名:文件名、一级子目录名、
.、..
4.2、open的时候是如何找到文件内容的?
表面上,用户通过文件名打开文件。实际上,系统内部这个过程分成三步:
- 从目录文件数据块中的所有目录项找到和这个文件名path相匹配的目录项(通俗理解哈,实际要复杂),从而找对对应的inode号;
- 通过inode号码,获取inode信息;
- 根据inode信息,找到文件数据所在的block,读出数据。
note:
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项的找,效率就不高了。于是,保存目录的格式改成哈希表,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。Linux 系统的 ext 文件系统就是采用了哈希表,来保存目录的内容,这种方法的优点是查找非常迅速,插入和删除也较简单,不过需要一些预备措施来避免哈希冲突。
五、进程与文件:
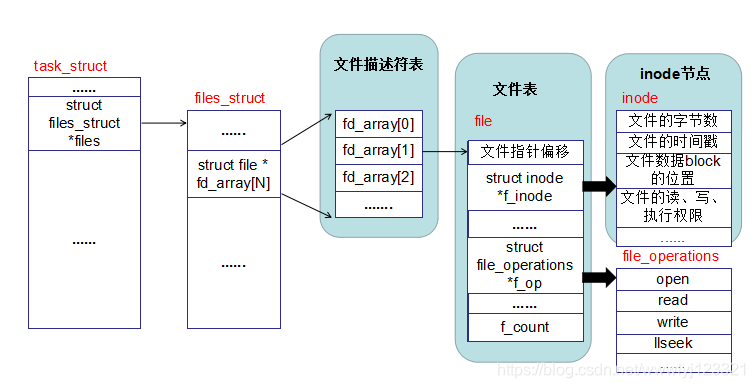
5.1、文件描述符表
(1) 每个进程在Linux内核中都有一个task_struct结构体来维护进程相关的信息,称为进程描述符(Process Descriptor),而在操作系统理论中称为进程控制块 (PCB,Process Control Block)。
struct task_struct {
...
/* open file information */
struct files_struct *files;
...
};task_struct中有一个指针(struct files_struct *files)指向files_struct结构体(如下所示),称为文件描述符表(我认为这个定义不确切,暂时还没找到这个说法的来源),记录该进程打开的所有文件。该表中有一个域(struct file * fd_array[NR_OPEN_DEFAULT]),为数组,该数组的每个元素指向已打开的文件的指针(已打开的文件在内核中用file 结构体表示,文件描述符表中的指针指向file 结构体)。
struct files_struct
{
atomic_t count; //引用计数 累加
struct fdtable *fdt;
struct fdtable fdtab;
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT]; //文件描述符数组
};struct file
{
mode_t f_mode;//表示文件是否可读或可写,FMODE_READ或FMODE_WRITE
dev_ t f_rdev ;// 用于/dev/tty
off_t f_ops;//当前文件位移
unsigned short f_flags;//文件标志,O_RDONLY,O_NONBLOCK和O_SYNC
unsigned short f_count;//打开的文件数目
unsigned short f_reada;
struct inode *f_inode;//指向inode的结构指针
struct file_operations *f_op;//文件操作索引指针
}(2) 用户程序不能直接访问内核中的文件描述符表,而只能使用文件描述符表的索引 (即0、1、2、3这些数字),这些索引就称为文件描述符(File Descriptor),用int 型变量保存。
- 文件描述符(本质上是个数字)是open系统调用内部由操作系统自动分配的,操作系统分配这个fd时也不是随意分配,操作系统规定,fd从0开始依次增加。linux中文件描述符表是个数组(不是链表),所以这个文件描述符表其实就是一个数组,fd是index,文件表指针是value
- 当我们去open时,内核会从文件描述符表中挑选一个最小的未被使用的数字给我们返回。也就是说如果之前fd已经占满了0-9,那么我们下次open得到的一定是10.(但是如果上一个fd得到的是9,下一个不一定是10,这是因为可能前面更小的一个fd已经被close释放掉了)
- fd中0、1、2已经默认被系统占用了,因此用户进程得到的最小的fd就是3了。
- linux内核占用了0、1、2这三个fd是有用的,当我们运行一个程序得到一个进程时,内部就默认已经打开了3个文件,这三个文件对应的fd就是0、1、2。这三个文件分别叫stdin(标准输入)、stdout(标准输出)、stderr(标准错误)。标准输入一般对应的是键盘,标准输出一般是LCD显示器(可以理解为:1对应LCD的设备文件)
- printf函数其实就是默认输出到标准输出stdout上了。stdio中还有一个函数叫fpirntf,这个函数就可以指定输出到哪个文件描述符中。
5.2、文件表
struct file
{
mode_t f_mode;//表示文件是否可读或可写,FMODE_READ或FMODE_WRITE
dev_ t f_rdev ;// 用于/dev/tty
off_t f_ops;//当前文件位移
unsigned short f_flags;//文件标志,O_RDONLY,O_NONBLOCK和O_SYNC
unsigned short f_count;//打开的文件数目
unsigned short f_reada;
struct inode *f_inode;//指向inode的结构指针
struct file_operations *f_op;//文件索引指针
}
内核为所有打开文件维护一张文件表项,每个文件表项包含内容可以由以上结构体看出,其中比较重要的内容有:
a. 文件状态(读 写 添写 同步 非阻塞等)
b. 当前文件偏移量
c. 指向该文件i节点(i节点)的指针
d. 指向该文件操作的指针(file_operations )
file_operations 结构体在linux内核2.6.5定义如下所示:
struct file_operations
{
struct module *owner;
loff_t(*llseek) (struct file *, loff_t, int);
ssize_t(*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t(*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t(*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t(*aio_write) (struct kiocb *, const char __user *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t(*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t(*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t(*sendfile) (struct file *, loff_t *, size_t, read_actor_t, void __user *);
ssize_t(*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area) (struct file *, unsigned long,
unsigned long, unsigned long,
unsigned long);
};总结:
https://www.cnblogs.com/xiaolincoding/p/13499209.html
鸟哥的 Linux 私房菜 -- Linux 磁盘与文件系统管理
https://blog.51cto.com/13574131/2064574
https://www.cnblogs.com/how-are-you/p/5699257.html
文件描述符表、文件表、索引结点表_文件系统带索引结点-CSDN博客
https://www.cnblogs.com/wanghetao/archive/2012/05/28/2521675.html
Linux驱动程序中的file,inode,file_operations三大结构体_linux中file结构体叫什么-CSDN博客

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









