







一、前言
本文介绍机器学习中经典的算法,基本的决策树实现,参考地址:https://zhuanlan.zhihu.com/p/20794583
二、算法原理
决策树可以用来预测和分类,主要流程包含:特征选择,决策树生成,决策树剪枝;
(1)特征选择
熵:信息论中用于度量随机变量的不确定性的程度,越大表示不确定性越大;
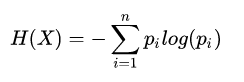
条件熵:随机变量给定的条件下,随机变量
的条件熵定义为:
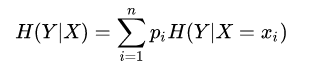
其中的 =
(
=
)
信息增益:用在ID3算法中,表示在已知特征的信息的情况下,使得类
的不确定性减少的程度,越大越好;
具体的定义如下:特征A对训练数据集D的信息增益定义为,集合D的经验熵(D)与特征A给定条件下D的经验条件熵
(D|A)之差,即

特征选择根据信息增益来确定:对于训练集D,计算每个特征的信息增益,信息增益较大的作为选择的特征;
信息增益具体的计算方法:假设训练集D中包含K个类别,包含A个特征,每个特征包含n个不同的取值;
第一步计算:经验熵,其中||代表类别为
的样本个数;

第二步计算:计算特征A关于数据集的条件经验熵,||代表
的样本个数,|
|代表子集
中属于
的样本个数;
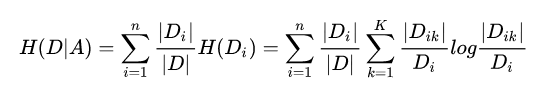
第三步:计算信息增益比
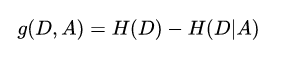
信息增益比:C4.5算法用于特征选择的条件;
和信息增益的优势,可以避免信息增益偏向于选择特征数量较多的特征,定义为:信息增益与特征A关于训练集D的熵之比;
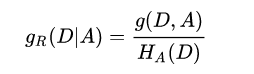
其中:
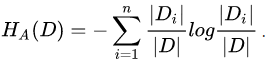
(2)决策树生成
决策树生成包含三种方式:ID3算法,C4.5,CART;
ID3算法:采用信息增益比来判定特征的选择;

C4.5算法:采用的是信息增益比来作为特征选择的标准;
CART:分类和回归树(classification and regression tree),其中分类采用的是基尼系数最小化准则,回归树采用的是平方误差最小化准则,CART是一个二叉树,通过递归的二分每个特征,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布。
平方误差最小化准则(公式太难打)

基尼系数
分类问题中,假设有K个类别,样本点属于第K类的概率为,则概率分布的基尼指数定义为:

(3)决策树剪枝
如果对训练集建立完整的决策树,会使得模型过于针对训练数据,拟合了大部分的噪声,即出现过度拟合的现象。为了避免这个问题,有两种解决的办法:
- 当熵减少的数量小于某一个阈值时,就停止分支的创建。这是一种贪心算法。
- 先创建完整的决策树,然后再尝试消除多余的节点,也就是采用减枝的方法。
方法1存在一个潜在的问题:有可能某一次分支的创建不会令熵有太大的下降,但是随后的子分支却有可能会使得熵大幅降低。因此,我们更倾向于采用剪枝的方法。
决策树的剪枝通过极小化决策树整体的损失函数来实现。在提高信息增益的基础上,通过对模型的复杂度T施加惩罚,便得到了损失函数的定义:
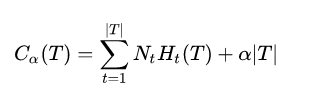
的大小反映了对模型训练集拟合度和模型复杂度的折衷考虑。剪枝的过程就是当
确定时,选择损失函数最小的模型。
具体的算法如下:
1. 计算每个节点的经验熵;
2. 递归地从树的叶节点向上回缩,如果将某一个父节点的所有叶节点合并,能够使得其损失函数减小,则进行剪枝,将父节点变成新的叶节点;
3. 返回2,直到不能继续合并。
三、代码实现
my_data=[['slashdot','USA','yes',18,'None'],
['google','France','yes',23,'Premium'],
['digg','USA','yes',24,'Basic'],
['kiwitobes','France','yes',23,'Basic'],
['google','UK','no',21,'Premium'],
['(direct)','New Zealand','no',12,'None'],
['(direct)','UK','no',21,'Basic'],
['google','USA','no',24,'Premium'],
['slashdot','France','yes',19,'None'],
['digg','USA','no',18,'None'],
['google','UK','no',18,'None'],
['kiwitobes','UK','no',19,'None'],
['digg','New Zealand','yes',12,'Basic'],
['slashdot','UK','no',21,'None'],
['google','UK','yes',18,'Basic'],
['kiwitobes','France','yes',19,'Basic']]
# test
def uniquecounts(rows):
results = {}
for row in rows:
#计数结果在最后一列
r = row[len(row)-1]
if r not in results:results[r] = 0
results[r]+=1
return results # 返回一个字典
def entropy(rows):
from math import log
log2 = lambda x:log(x)/log(2)
results = uniquecounts(rows)
#开始计算熵的值
ent = 0.0
for r in results.keys():
p = float(results[r])/len(rows)
ent = ent - p*log2(p)
return ent
#定义节点的属性
class decisionnode:
def __init__(self,col = -1,value = None, results = None, tb = None,fb = None):
self.col = col # col是待检验的判断条件所对应的列索引值
self.value = value # value对应于为了使结果为True,当前列必须匹配的值
self.results = results #保存的是针对当前分支的结果,它是一个字典
self.tb = tb ## desision node,对应于结果为true时,树上相对于当前节点的子树上的节点
self.fb = fb ## desision node,对应于结果为false时,树上相对于当前节点的子树上的节点
# 基尼不纯度
# 随机放置的数据项出现于错误分类中的概率
def giniimpurity(rows):
total = len(rows)
counts = uniquecounts(rows)
imp =0
for k1 in counts:
p1 = float(counts[k1])/total
for k2 in counts: # 这个循环是否可以用(1-p1)替换?
if k1 == k2: continue
p2 = float(counts[k2])/total
imp+=p1*p2
return imp
# 改进giniimpurity
def giniimpurity_2(rows):
total = len(rows)
counts = uniquecounts(rows)
imp = 0
for k1 in counts.keys():
p1 = float(counts[k1])/total
imp+= p1*(1-p1)
return imp
#在某一列上对数据集进行拆分。可应用于数值型或因子型变量
def divideset(rows,column,value):
#定义一个函数,判断当前数据行属于第一组还是第二组
split_function = None
if isinstance(value,int) or isinstance(value,float):
split_function = lambda row:row[column] >= value
else:
split_function = lambda row:row[column]==value
# 将数据集拆分成两个集合,并返回
set1 = [row for row in rows if split_function(row)]
set2 = [row for row in rows if not split_function(row)]
return(set1,set2)
# 以递归方式构造树
def buildtree(rows,scoref = entropy):
if len(rows)==0 : return decisionnode()
current_score = scoref(rows)
# 定义一些变量以记录最佳拆分条件
best_gain = 0.0
best_criteria = None
best_sets = None
column_count = len(rows[0]) - 1
for col in range(0,column_count):
#在当前列中生成一个由不同值构成的序列
column_values = {}
for row in rows:
column_values[row[col]] = 1 # 初始化
#根据这一列中的每个值,尝试对数据集进行拆分
for value in column_values.keys():
(set1,set2) = divideset(rows,col,value)
# 信息增益
p = float(len(set1))/len(rows)
gain = current_score - p*scoref(set1) - (1-p)*scoref(set2)
if gain>best_gain and len(set1)>0 and len(set2)>0:
best_gain = gain
best_criteria = (col,value)
best_sets = (set1,set2)
#创建子分支
if best_gain>0:
trueBranch = buildtree(best_sets[0]) #递归调用
falseBranch = buildtree(best_sets[1])
return decisionnode(col = best_criteria[0],value = best_criteria[1],
tb = trueBranch,fb = falseBranch)
else:
return decisionnode(results = uniquecounts(rows))
# 决策树的显示
def printtree(tree,indent = ''):
# 是否是叶节点
if tree.results!=None:
print(str(tree.results))
else:
# 打印判断条件
print (str(tree.col)+":"+str(tree.value)+"? ")
#打印分支
print(indent+"T->",)
printtree(tree.tb,indent+" ")
print(indent+"F->",)
printtree(tree.fb,indent+" ")
# 对新的观测数据进行分类
def classify(observation,tree):
if tree.results!= None:
return tree.results
else:
v = observation[tree.col]
branch = None
if isinstance(v,int) or isinstance(v,float):
if v>= tree.value: branch = tree.tb
else: branch = tree.fb
else:
if v==tree.value : branch = tree.tb
else: branch = tree.fb
return classify(observation,branch)
divideset(my_data,2,'yes')
giniimpurity(my_data)
giniimpurity_2(my_data)
tree = buildtree(my_data)
printtree(tree = tree)
classify(['(direct)','USA','yes',5],tree)
# 决策树的剪枝
def prune(tree,mingain):
# 如果分支不是叶节点,则对其进行剪枝
if tree.tb.results == None:
prune(tree.tb,mingain)
if tree.fb.results == None:
prune(tree.fb,mingain)
# 如果两个子分支都是叶节点,判断是否能够合并
if tree.tb.results !=None and tree.fb.results !=None:
#构造合并后的数据集
tb,fb = [],[]
for v,c in tree.tb.results.items():
tb+=[[v]]*c
for v,c in tree.fb.results.items():
fb+=[[v]]*c
#检查熵的减少量
delta = entropy(tb+fb)-(entropy(tb)+entropy(fb)/2)
if delta < mingain:
# 合并分支
tree.tb,tree.fb = None,None
tree.results = uniquecounts(tb+fb)
# test
tree = buildtree(my_data,scoref = giniimpurity)
prune(tree,0.1)
printtree(tree)四、决策树的优缺点分析
优点
- - 易于理解和解释,甚至比线性回归更直观;
- - 与人类做决策思考的思维习惯契合;
- - 模型可以通过树的形式进行可视化展示;
- - 可以直接处理非数值型数据,不需要进行哑变量的转化,甚至可以直接处理含缺失值的数据;
缺点
- - 对于有大量数值型输入和输出的问题,决策树未必是一个好的选择;
- - 特别是当数值型变量之间存在许多错综复杂的关系,如金融数据分析;
- - 决定分类的因素取决于更多变量的复杂组合时;
- - 模型不够稳健,某一个节点的小小变化可能导致整个树会有很大的不同。
六. 深入学习
- - Bagging
- - 随机森林(Random Forest)
- - Boosting















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









