







SPFA算法详解
SPFA(Shortest Path Faster Algorithm)(队列优化)算法是求单源最短路径的一种算法,它还有一个重要的功能是判负环。
适用范围:给定的图存在负权边,这是类似迪杰斯特拉等算法就没有了用武之地,而Ford算法的复杂度又过高,SPFA算法就有用处了。
算法思想:设立一个队列用来保存待优化的结点,优化时每次取出队首节点u,并用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前队列中,就将v点放入队尾。这样不断从队列中取出结点进行松弛操作,直到队列为空。
它不能执行带负环图,若某个结点进入队列的次数超过n次则存在负环;
具体实现过程:
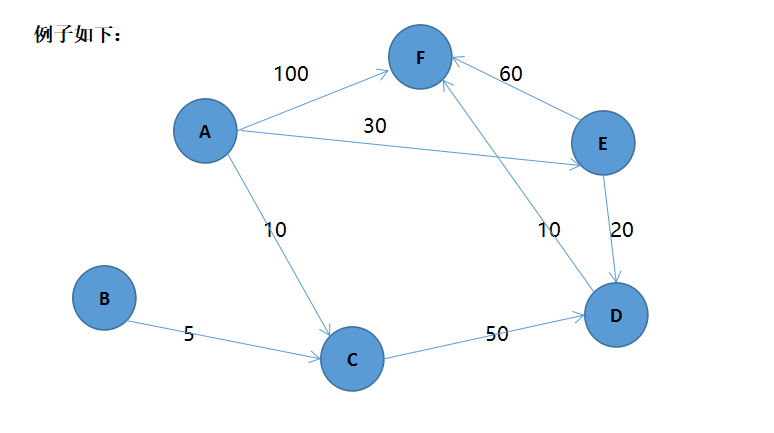
假设从A点出发,建立一个路径的表格,令A到A为0,其余为‘#’表示无穷,将A入队列,若非空
| ||||||||||||||||||||
1.首先将A出队列,对以A为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | # | 30 | 100 |
其中C,E,F边变小,入队列。队列元素为(C E F)
2.将C出队列,对以C为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | 60 | 30 | 100 |
其中D边变小,入队列。队列元素为( E F D)
3.将E出队列,对以E为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | 50 | 30 | 90 |
其中D F边变小,队列中有。队列元素为( F D)
4.将F出队列,对以F为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | 50 | 30 | 90 |
其中无边变小,不入队列。队列元素为( D)
5.将D出队列,对以D为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | 50 | 30 | 70 |
其中F变小,入队列。队列元素为( F)
5.将F出队列,对以F为起始点的所有边进行松弛操作,此时路径表格的状态为:
结点 | A | B | C | D | E | F |
距离 | 0 | # | 10 | 50 | 30 | 70 |
其中无变化,不入队列。队列元素为( ):
此时队列为空结束
void spfa(int k)
{
int v[805];//判断是否在队列
int dis[805];//保存最短路径距离
int a[805][805];//两点之间的距离
memset(v,0,sizeof(v)); //表状态,若入队列,为1,否则为0
queue<int >q; //建立队列
q.push(k); //源点入队列
v[k]=1; //在队列中值为1
for(int i=1;i<=p;i++) dis[i]=inf;
dis[k]=0; //源点到源点的路径长度为0
while(!q.empty()) //判断是否为空,若为空结束
{
int m=q.front(); //出队列
v[m]=0; //出队列后,值为 0
q.pop();
for(int i=1;i<=p;i++)
{
if(a[m][i]<inf)
{
if(dis[i]>dis[m]+a[m][i]) //判断路径长度是否减少
{
dis[i]=dis[m]+a[m][i];
if(!v[i]) //若减少,且当前元素没在队列中
{
q.push(i); //入队列
v[i]=1; //值为1
}
}
}
}
}
}














 4357
4357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









