






大家好,这里是小琳AI课堂!今天我们要继续深入探讨k-means算法,这是一种在数据科学和机器学习中非常流行的聚类方法。🤖✨
k-means的四大步骤
- 随机启动:先随便挑k个数据点当老大(簇中心)。
- 分配小弟:每个数据点看看离哪个老大最近,然后加入那个团队。
- 老大换人:每个团队重新算算中心位置,换个新老大。
- 重复搞事:一直重复分配小弟和换老大的步骤,直到老大们换得差不多了或者到了预定的次数。
k-means的闪光点和小瑕疵
- 优点:
- 简单易懂:就像小朋友分组玩游戏。
- 效率高:处理大数据也很快。
- 结果清晰:分组结果容易看懂。
- 缺点:
- 得先知道k值(分多少组),这个有时候不好确定。
- 老大的初始选择很重要,选不好可能导致结果不太理想。
- 对异常值比较敏感。
- 假设簇是凸形的,有些奇形怪状的数据就不太适合。
k-means的实际应用
k-means在好多领域都能大显身手,比如:
- 市场细分:根据消费者的行为分群。
- 图像处理:在图像分割中把像素点分组。
- 文档聚类:在文本挖掘中把文档分组。
示例代码:Python小试牛刀
我们用Python和scikit-learn库来个小演示,用k-means把数据点分成两组。
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
np.random.seed(0)
X = np.random.rand(100, 2)
# 用k-means聚类
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(X)
# 获取结果
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# 绘图展示
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', marker='x')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
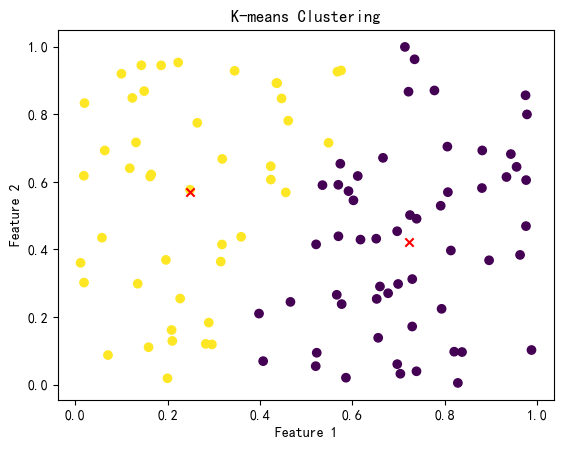
看这个图,我们就用k-means把数据点分成了两组。不同颜色代表不同组,红色“X”是每组的老大(中心)。
这个小例子展示了k-means的基本原理。实际中,k-means能处理更复杂的数据,维数更高也没问题。但要注意,k-means的效果很大程度上取决于初始中心和k值的选择。实际用的时候,可能需要多试几个k值,多跑几次算法,才能找到最佳结果。
如果你对k-means有更多疑问,或者想深入了解,随时问我哦!🌟👩💻🤖
本期的小琳AI课堂就到这里,我们下期再见!















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









