







今天给大家分享一个这几天在研究的方案!只需 3 步,就能实现公众号文章采集及本地保存,还能自动转成方便编辑的 Markdown 格式!
主要思路参考《99%的人不知道:在微信后台这样操作,自动批量获取公众号文章链接(附完整脚本)》和《AI 编程小白必看:如何批量下载公众号文章为 Markdown 格式》
本文图示导读如下

🔥 这个工具的作用是什么?
✔ 一键批量下载,效率提升 10 倍+
✔ 自动转 Markdown,保留原文格式
✔ 离线保存图片,不怕链接失效
📌 超简单 3 步教程:
1️⃣ 准备工作
你需要在浏览器中安装 Tampermonkey 扩展,自动化的脚本是放在 Tampermonkey 里驱动的。
方式一(推荐):
从百度网盘下载 Tampermonkey-5.3.3.crx
🐳https://pan.baidu.com/s/1dykmd7TV3mrdxVYdnoV1OQ?pwd=wxai
打开浏览器设置,打开扩展程序页面,或者直接搜索 Chrome://extensions/进入。然后保持页面开发者模式的开启。找到 Tampermonkey-5.3.3.crx 文件,将其拖动到扩展程序页面,释放并同意完成安装。
方式二:
登录官方网站,点击下载就可以跳转应用商店安装(但可能因网络原因访问不了)。
🐳官方网站 https://www.tampermonkey.net/
- 准备好你的公众号后台权限
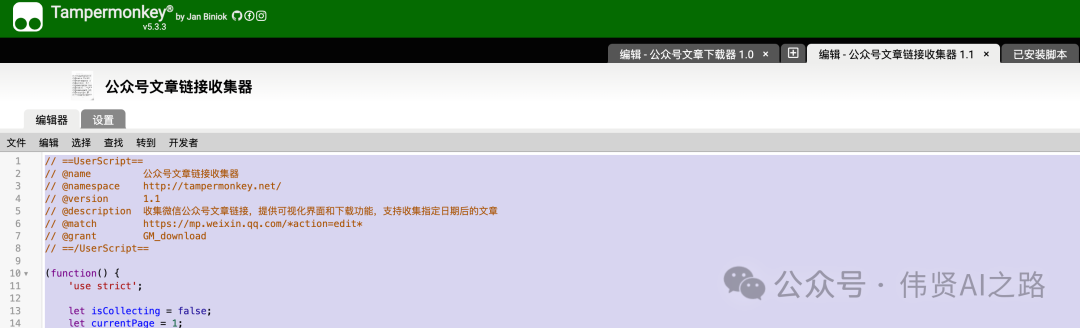
2️⃣ 安装链接收集器脚本
// ==UserScript==// @name 公众号文章链接收集器// @namespace http://tampermonkey.net/// @version 1.1// @description 收集微信公众号文章链接,提供可视化界面和下载功能,支持收集指定日期后的文章// @match https://mp.weixin.qq.com/*action=edit*// @grant GM_download// ==/UserScript==(function() {'use strict';let isCollecting = false;let currentPage = 1;let totalPages = 1;let startDate = null;const storage = {save: (value) => {try {localStorage.setItem('collectedArticles', JSON.stringify(value));return true;} catch (error) {console.error('Error saving to localStorage:', error);return false;}},load: () => {try {const value = localStorage.getItem('collectedArticles');return value ? JSON.parse(value) : [];} catch (error) {console.error('Error loading from localStorage:', error);return [];}},clear: () => {try {localStorage.removeItem('collectedArticles');return true;} catch (error) {console.error('Error clearing localStorage:', error);return false;}}};function getAccountName() {const accountElement = document.querySelector('.inner_link_account_msg');if (accountElement) {const fullText = accountElement.textContent.trim();return fullText.replace(/选择其他账号$/, '').trim();}const selectors = ['.weui-desktop-account__nickname','.account_setting_nick_name',];for (let selector of selectors) {const element = document.querySelector(selector);if (element) {const name = element.textContent.trim();if (name) return name;}}return '未知公众号';}function createUI() {const uiContainer = document.createElement('div');uiContainer.id = 'article-collector';uiContainer.style.cssText = `position: fixed;top: 10px;right: 10px;background: white;border: 1px solid #ccc;padding: 10px;z-index: 10000;font-family: Arial, sans-serif;width: 220px;`;const accountName = getAccountName();uiContainer.innerHTML = `<h3 style="margin-top: 0; margin-bottom: 10px;">文章收集器</h3><p style="margin-bottom: 10px;">当前公众号: <strong id="account-name">${accountName}</strong></p><label for="start-date" style="display: block; margin-bottom: 5px;">选择起始日期(可选):</label><input type="date" id="start-date" class="collector-date"><p style="font-size: 12px; color: #666; margin-bottom: 10px;">提示:如果选择日期,将只收集该日期之后的文章。不选择则收集所有文章。</p><button id="start-collect" class="collector-btn" disabled>开始收集</button><button id="stop-collect" class="collector-btn" style="display:none;">停止收集</button><p id="collect-status" style="margin: 10px 0;"></p><button id="download-csv" class="collector-btn" disabled>下载CSV</button><button id="clear-data" class="collector-btn">清理数据</button>`;const style = document.createElement('style');style.textContent = `.collector-btn {background-color: #07C160;color: white;border: none;padding: 8px 16px;text-align: center;text-decoration: none;display: inline-block;font-size: 14px;margin: 4px 0;cursor: pointer;border-radius: 4px;transition: background-color 0.3s;width: 100%;box-sizing: border-box;}.collector-btn:hover:not(:disabled) {background-color: #06AD56;}.collector-btn:disabled {background-color: #9ED5B9;cursor: not-allowed;}.collector-date {width: 100%;padding: 6px;margin-bottom: 10px;border: 1px solid #ccc;border-radius: 4px;box-sizing: border-box;}`;document.head.appendChild(style);document.body.appendChild(uiContainer);document.getElementById('start-collect').addEventListener('click', startCollection);document.getElementById('stop-collect').addEventListener('click', stopCollection);document.getElementById('download-csv').addEventListener('click', downloadCSV);document.getElementById('clear-data').addEventListener('click', clearCollectedData);// 定期检查是否有可收集的文章setInterval(checkForArticles, 1000);}function checkForArticles() {const articles = document.querySelectorAll('.inner_link_article_item');const startCollectBtn = document.getElementById('start-collect');const downloadCsvBtn = document.getElementById('download-csv');if (articles.length > 0 && !isCollecting) {startCollectBtn.disabled = false;} else {startCollectBtn.disabled = true;}downloadCsvBtn.disabled = storage.load().length === 0;}function updateAccountName() {const accountNameElement = document.getElementById('account-name');if (accountNameElement) {accountNameElement.textContent = getAccountName();}}function startCollection() {if (isCollecting) return;isCollecting = true;currentPage = 1;startDate = document.getElementById('start-date').value ? new Date(document.getElementById('start-date').value) : null;updateButtonStates(true);document.getElementById('collect-status').textContent = '收集中...';updateAccountName();collectArticleInfo();}function stopCollection() {isCollecting = false;updateButtonStates(false);const collectedArticles = storage.load();document.getElementById('collect-status').textContent = `收集已停止,已收集 ${collectedArticles.length} 篇文章`;console.log(`收集已停止,总共收集到 ${collectedArticles.length} 篇文章信息`);if (collectedArticles.length > 0) {console.log(collectedArticles.join('\n'));}}function updateButtonStates(collecting) {document.getElementById('start-collect').style.display = collecting ? 'none' : 'inline-block';document.getElementById('stop-collect').style.display = collecting ? 'inline-block' : 'none';document.getElementById('download-csv').disabled = storage.load().length === 0;if (!collecting) {checkForArticles(); // 在停止收集后重新检查是否有可收集的文章}}function collectArticleInfo() {if (!isCollecting) return;const articles = document.querySelectorAll('.inner_link_article_item');if (articles.length === 0) {console.log("未找到文章列表,请确保弹出框已打开。");stopCollection();return;}let shouldContinue = true;let collectedArticles = storage.load();articles.forEach(article => {if (!shouldContinue) return;const title = article.querySelector('.inner_link_article_title span:last-child').textContent.trim();const url = article.querySelector('.inner_link_article_date a').href;const dateStr = article.querySelector('.inner_link_article_date span:first-child').textContent.trim();const date = new Date(dateStr);if (startDate && date < startDate) {shouldContinue = false;return;}collectedArticles.push(`${title}|${url}|${dateStr}`);});storage.save(collectedArticles);// 获取总页数const paginationLabel = document.querySelector('.weui-desktop-pagination__num__wrp');if (paginationLabel) {const paginationText = paginationLabel.textContent;const match = paginationText.match(/(\d+)\s*\/\s*(\d+)/);if (match) {currentPage = parseInt(match[1]);totalPages = parseInt(match[2]);}}const nextPageButton = document.querySelector('.weui-desktop-pagination__nav a:last-child');if (nextPageButton && !nextPageButton.classList.contains('weui-desktop-btn_disabled') && shouldContinue) {const randomDelay = Math.floor(Math.random() * (3000 - 1000 + 1) + 1000); // 1-3秒随机延迟document.getElementById('collect-status').textContent = `收集中...第 ${currentPage}/${totalPages} 页,等待 ${randomDelay/1000} 秒`;setTimeout(() => {if (isCollecting) {nextPageButton.click();setTimeout(collectArticleInfo, 1000); // 页面加载等待时间}}, randomDelay);} else {// 最后一页或达到指定日期,结束收集const finalDelay = 5000; // 5秒延迟document.getElementById('collect-status').textContent = `收集完成,最后处理中...等待 ${finalDelay/1000} 秒`;setTimeout(finishCollection, finalDelay);}}function finishCollection() {isCollecting = false;updateButtonStates(false);const collectedArticles = storage.load();document.getElementById('collect-status').textContent = `收集完成,共 ${collectedArticles.length} 篇文章`;console.log(`总共收集到 ${collectedArticles.length} 篇文章信息`);console.log(collectedArticles.join('\n'));}function downloadCSV() {const accountName = getAccountName();const currentDate = new Date().toISOString().split('T')[0];const fileName = `${accountName}_${currentDate}.csv`;const collectedArticles = storage.load();const csvContent = "公众号,标题,链接,日期\n"+ collectedArticles.map(info => {const [title, url, date] = info.split('|');return `"${accountName}","${title}","${url}","${date}"`;}).join("\n");const blob = new Blob([csvContent], { type: 'text/csv;charset=utf-8;' });const url = URL.createObjectURL(blob);GM_download({url: url,name: fileName,onload: () => {console.log(`Downloaded: ${fileName}`);URL.revokeObjectURL(url);},onerror: (error) => {console.error(`Error downloading ${fileName}:`, error);URL.revokeObjectURL(url);}});}function clearCollectedData() {if (confirm('确定要清除所有收集的数据吗?')) {storage.clear();document.getElementById('collect-status').textContent = '数据已清除';updateButtonStates(false);}}window.addEventListener('load', createUI);const observer = new MutationObserver(() => {updateAccountName();checkForArticles();});observer.observe(document.body, { childList: true, subtree: true });})();
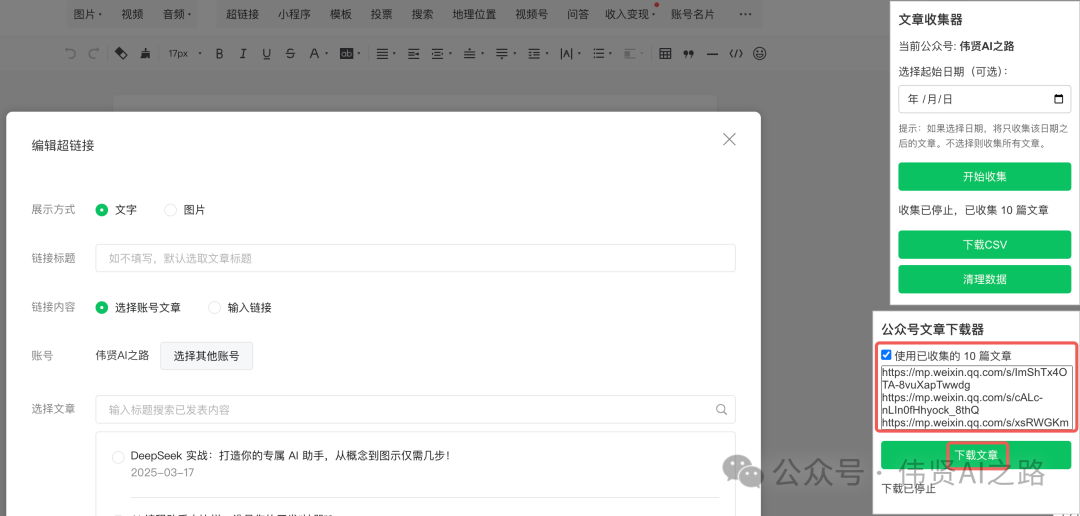
👉 操作指南:
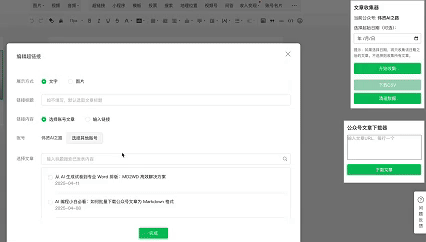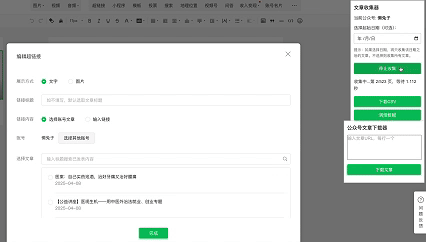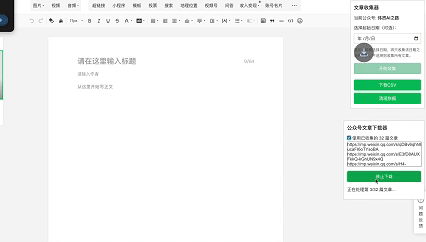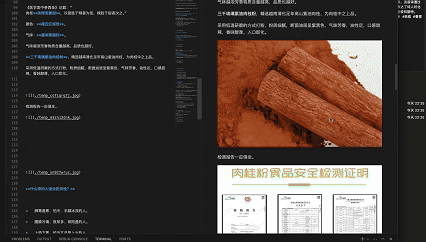
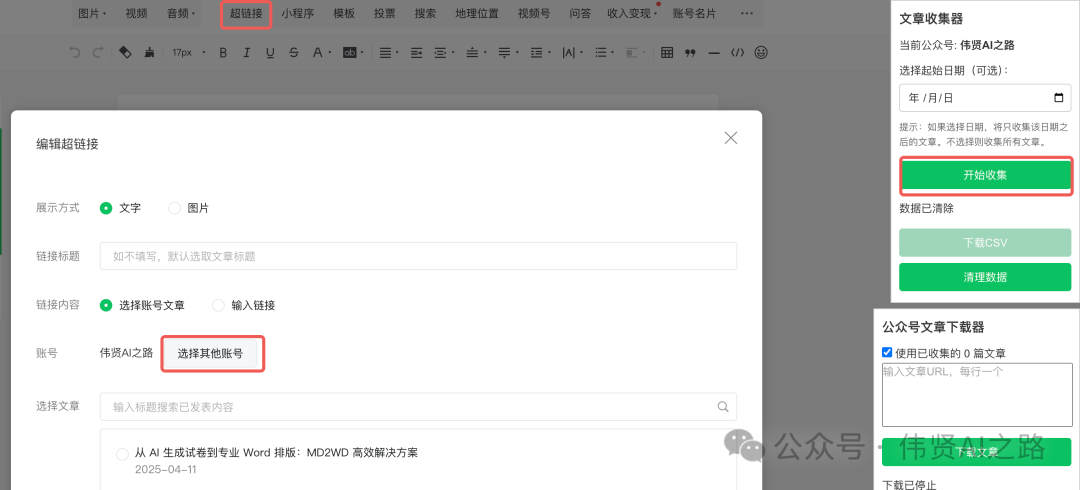
- 登录公众号后台,草稿箱中写新文章,点击“超链接”
- 点击右上角"文章收集器"
- 设置日期范围(可选)
- 一键收集所有文章链接
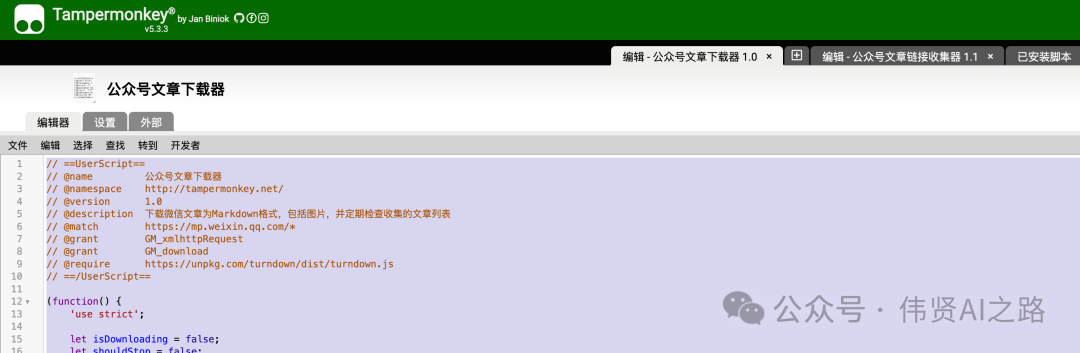
3️⃣ 安装文章下载器脚本
// ==UserScript==// @name 公众号文章下载器// @namespace http://tampermonkey.net/// @version 1.0// @description 下载微信文章为Markdown格式,包括图片,并定期检查收集的文章列表// @match https://mp.weixin.qq.com/*// @grant GM_xmlhttpRequest// @grant GM_download// @require https://unpkg.com/turndown/dist/turndown.js// ==/UserScript==(function() {'use strict';let isDownloading = false;let shouldStop = false;let checkInterval;// 创建UIfunction createUI() {const collectorUI = document.getElementById('article-collector');const uiContainer = document.createElement('div');uiContainer.id = 'article-downloader';let topPosition = '10px';let width = '300px';if (collectorUI) {topPosition = `${collectorUI.offsetTop + collectorUI.offsetHeight + 40}px`;width = `${collectorUI.offsetWidth}px`;}uiContainer.style.cssText = `position: fixed;top: ${topPosition};right: 10px;background: white;border: 1px solid #ccc;padding: 10px;z-index: 10000;font-family: Arial, sans-serif;width: ${width};`;const collectedArticles = JSON.parse(localStorage.getItem('collectedArticles') || '[]');const hasCollectedArticles = collectedArticles.length > 0;uiContainer.innerHTML = `<h3 style="margin-top: 0; margin-bottom: 10px;">公众号文章下载器</h3>${hasCollectedArticles ? `<div><input type="checkbox" id="use-collected-articles"><label for="use-collected-articles">使用已收集的 <span id="collected-count">${collectedArticles.length}</span> 篇文章</label></div>` : ''}<textarea id="article-urls" rows="5" style="width: 100%; margin-bottom: 10px;" placeholder="输入文章URL,每行一个"></textarea><button id="download-articles" class="downloader-btn">下载文章</button><p id="download-status" style="margin: 10px 0;"></p>`;const style = document.createElement('style');style.textContent = `.downloader-btn {background-color: #07C160;color: white;border: none;padding: 8px 16px;text-align: center;text-decoration: none;display: inline-block;font-size: 14px;margin: 4px 0;cursor: pointer;border-radius: 4px;transition: background-color 0.3s;width: 100%;box-sizing: border-box;}.downloader-btn:hover {background-color: #06AD56;}`;document.head.appendChild(style);document.body.appendChild(uiContainer);document.getElementById('download-articles').addEventListener('click', toggleDownload);if (hasCollectedArticles) {document.getElementById('use-collected-articles').addEventListener('change', function() {const textarea = document.getElementById('article-urls');if (this.checked) {textarea.value = collectedArticles.map(article => article.split('|')[1]).join('\n');} else {textarea.value = '';}});}// 开始定期检查startPeriodicCheck();}// 开始定期检查function startPeriodicCheck() {checkInterval = setInterval(() => {if (!isDownloading) {checkCollectedArticles();}}, 5000); // 每5秒检查一次}// 检查收集的文章function checkCollectedArticles() {const collectedArticles = JSON.parse(localStorage.getItem('collectedArticles') || '[]');const countElement = document.getElementById('collected-count');const useCollectedCheckbox = document.getElementById('use-collected-articles');if (countElement) {countElement.textContent = collectedArticles.length;}if (useCollectedCheckbox && useCollectedCheckbox.checked) {const textarea = document.getElementById('article-urls');textarea.value = collectedArticles.map(article => article.split('|')[1]).join('\n');}}// 切换下载状态function toggleDownload() {const button = document.getElementById('download-articles');if (isDownloading) {shouldStop = true;button.textContent = '停止中...';button.disabled = true;} else {shouldStop = false;isDownloading = true;button.textContent = '停止下载';startDownload();}}// 开始下载过程async function startDownload() {const urls = document.getElementById('article-urls').value.split('\n').filter(url => url.trim());const statusElement = document.getElementById('download-status');const turndownService = new TurndownService();statusElement.textContent = '准备下载...如果出现新窗口,请允许下载并关闭该窗口。';for (let i = 0; i < urls.length; i++) {if (shouldStop) {statusElement.textContent = '下载已停止';break;}const url = urls[i].trim();if (!url) continue;statusElement.textContent = `正在处理第 ${i + 1}/${urls.length} 篇文章...`;try {const { title, content, createTime } = await fetchArticleContent(url);const { markdown, images } = await processContent(url, title, createTime, content, turndownService);// 下载 Markdown 文件const fileName = `${title.replace(/[\\/:*?"<>|]/g, '')}.md`;downloadFile(new Blob([markdown], {type: 'text/markdown'}), fileName);// 下载图片for (const [imageName, imageUrl] of Object.entries(images)) {if (shouldStop) break;try {await fetchImage(imageUrl, imageName);} catch (error) {console.error(`图片 ${imageName} 下载失败:`, error);}}if (!shouldStop) {await new Promise(resolve => setTimeout(resolve, 2000)); // 2秒延迟,避免过快请求}} catch (error) {console.error(`下载文章失败: ${url}`, error);statusElement.textContent += `\n文章下载失败: ${url}`;}}isDownloading = false;const button = document.getElementById('download-articles');button.textContent = '下载文章';button.disabled = false;if (!shouldStop) {statusElement.textContent = `下载完成,共处理 ${urls.length} 篇文章。请检查您的下载文件夹。`;}}// 下载文件function downloadFile(blob, fileName) {const url = URL.createObjectURL(blob);const a = document.createElement('a');a.href = url;a.download = fileName;a.target = '_blank'; // 在新窗口中打开a.rel = 'noopener noreferrer'; // 安全考虑a.click();setTimeout(() => {URL.revokeObjectURL(url);}, 100); // 短暂延迟后释放 URL}// 获取文章内容function fetchArticleContent(url) {return new Promise((resolve, reject) => {GM_xmlhttpRequest({method: "GET",url: url,headers: {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'},onload: function(response) {if (response.status === 200) {const parser = new DOMParser();const doc = parser.parseFromString(response.responseText, "text/html");const titleElement = doc.querySelector('h1#activity-name') ||doc.querySelector('h2.rich_media_title') ||doc.querySelector('h1.article-title');const title = titleElement ? titleElement.textContent.trim() : '未知标题';const contentElement = doc.querySelector('#js_content');const content = contentElement ? contentElement.innerHTML : '';let createTime = '';const createTimeMatch = response.responseText.match(/createTime\s+=\s+'(.*)'/);if (createTimeMatch) {createTime = createTimeMatch[1];}resolve({ title, content, createTime });} else {reject(new Error(`请求失败: ${response.status}`));}},onerror: function(error) {reject(error);}});});}// 处理内容,包括准备图片下载async function processContent(url, title, createTime, content, turndownService) {const parser = new DOMParser();const doc = parser.parseFromString(content, 'text/html');const images = {};const imageMap = {};// 准备图片下载Array.from(doc.querySelectorAll('img')).forEach((img) => {const imgSrc = img.getAttribute('data-src') || img.getAttribute('src');if (!imgSrc) return;const tempFileName = "temp_" + Math.random().toString(36).substr(2, 9) + ".jpg";imageMap[imgSrc] = tempFileName;images[tempFileName] = imgSrc;// 替换图片 src 为临时文件名img.setAttribute('src', `./${tempFileName}`);});const cleanTitle = removeNonvisibleChars(title);const formattedCreateTime = createTime ? `publish_time: ${createTime}` : "publish_time: unknown";let markdownContent = turndownService.turndown(doc.body.innerHTML);// 替换 Markdown 中的图片引用markdownContent = markdownContent.replace(/!\[.*?\]\((.*?)\)/g, (match, p1) => {const tempFileName = imageMap[p1] || p1;return ``;});let markdown = `# ${cleanTitle}\n\n${formattedCreateTime}\n\nurl: ${url}\n\n${markdownContent}\n`;// 处理特殊字符markdown = markdown.replace(/\xa0{1,}/g, '\n');markdown = markdown.replace(/\]\(http([^)]*)\)/g,(match, p1) => `](http${p1.replace(/ /g, '%20')})`);return { markdown, images };}// 获取图片数据function fetchImage(url, filename) {return new Promise((resolve, reject) => {GM_download({url: url,name: filename,onload: function() {resolve();},onerror: function(error) {reject(error);}});});}// 移除不可见字符function removeNonvisibleChars(text) {return text.replace(/[\u200B-\u200D\uFEFF]/g, '');}// 在页面加载完成后创建UIwindow.addEventListener('load', createUI);})();
👉 使用技巧:
- 支持批量导入链接
- 自动下载图片资源
- 生成规范的 Markdown 文件
⚠️ 注意事项:
- 仅支持公开文章
- 请合理使用,尊重版权
- 建议个人学习使用
往期精彩
从 AI 生成试卷到专业 Word 排版:MD2WD 高效解决方案
AI 编程小白必看:如何批量下载公众号文章为 Markdown 格式
99%的人不知道:在微信后台这样操作,自动批量获取公众号文章链接(附完整脚本)

















 7082
7082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









