







在运营公众号的过程中,收集优质文章链接是一项重要且繁琐的工作。今天,就来给大家分享一个高效收集微信公众号文章链接的小技巧,让你轻松搞定这项任务!
本文快速导读
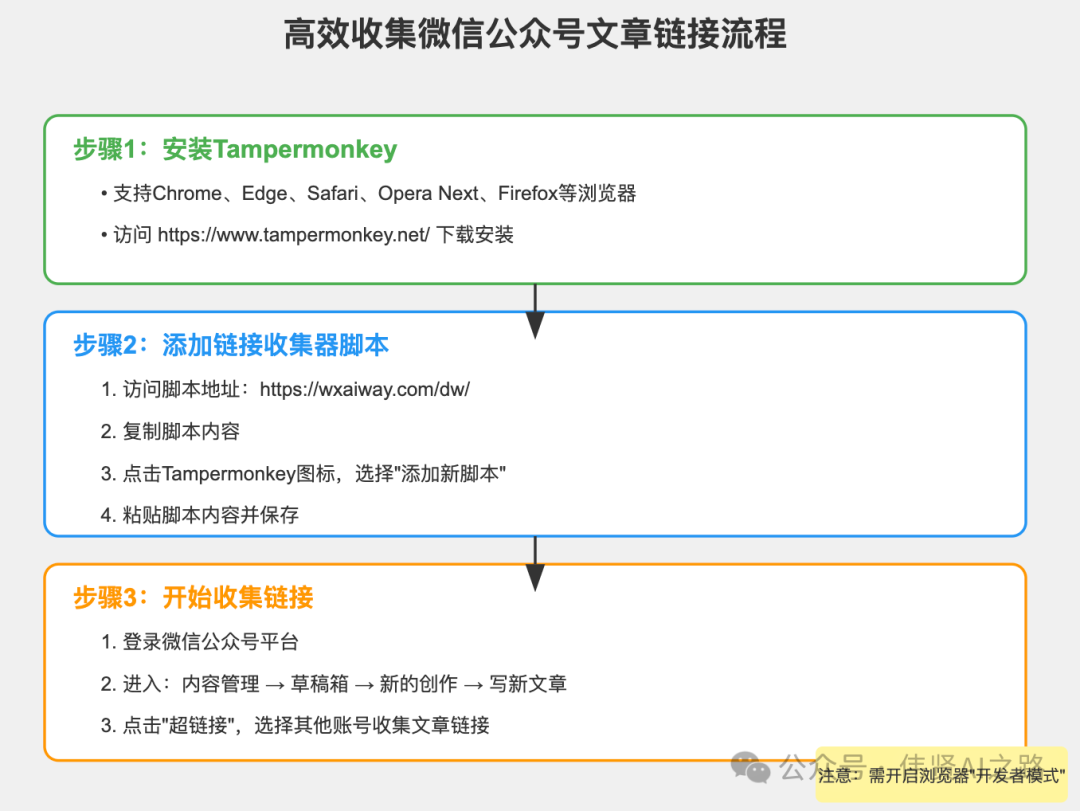
一、安装 Tampermonkey
首先,我们需要安装一个强大的浏览器扩展——Tampermonkey。它是一款广受欢迎的浏览器扩展,支持 Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox 等主流浏览器,能够帮助我们自定义和增强网页的功能。
打开 Tampermonkey 官方网站,根据你所使用的浏览器类型,选择对应的应用商店进行下载并安装。
🐳https://www.tampermonkey.net/
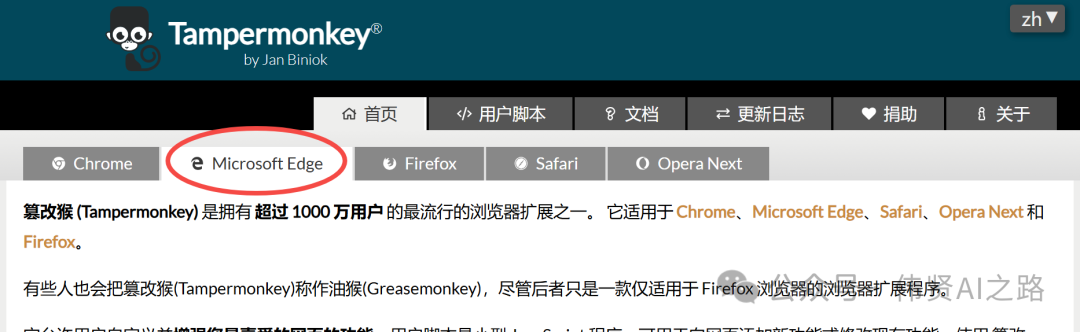
例如,如果你使用的是 Edge 浏览器,安装完成后,可以选择将其固定在工具栏上,方便随时使用。
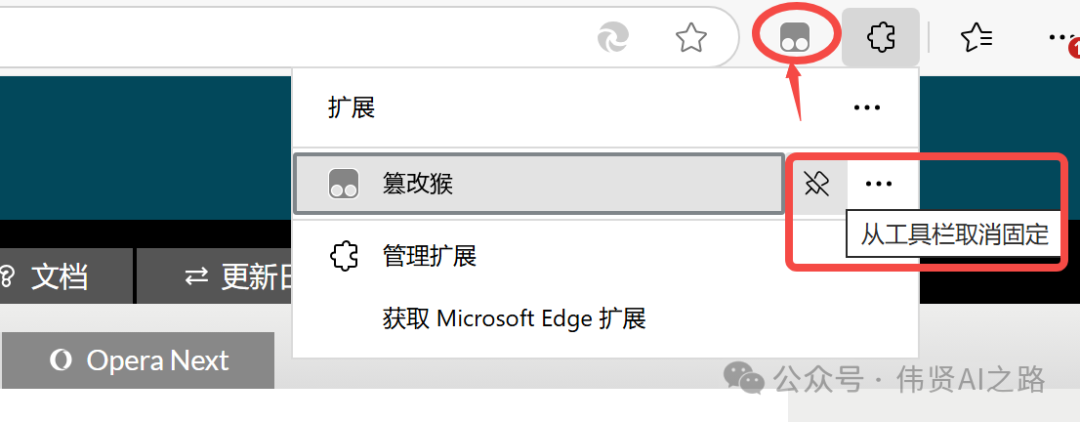
二、添加链接收集器脚本
接下来,我们需要添加公众号链接收集器的脚本。访问 公众号链接收集器的脚本地址,找到最新的脚本内容,将其全选并复制下来。
如果不能使用,请留言说明。
🐳https://wxaiway.com/dw/
然后,点击浏览器工具栏上的 Tampermonkey 小图标,选择“添加新脚本”,将刚才复制的脚本粘贴进去,点击“保存”。
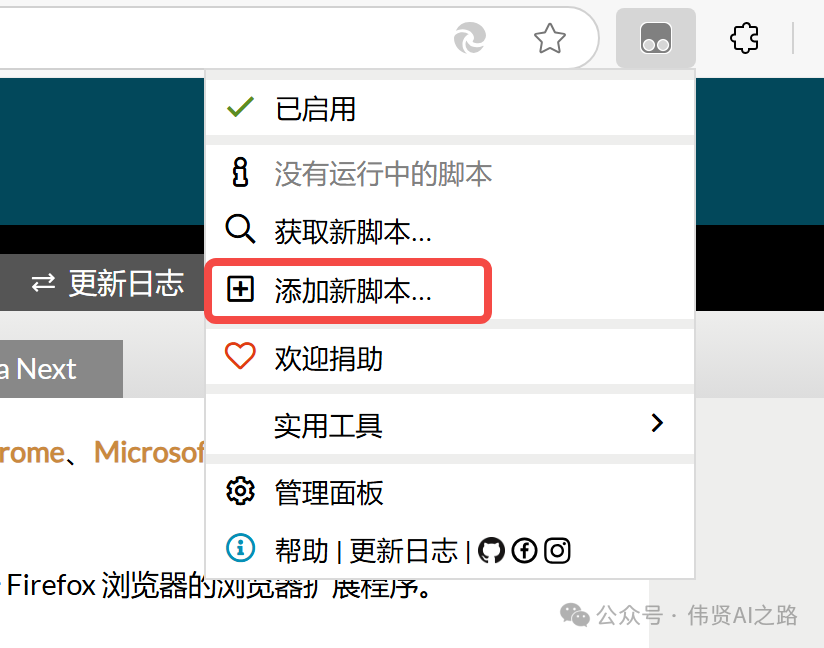
这样你就可以在“已安装脚本”中看到已经启动的脚本了。

同样地,我们还需要添加公众号文章下载器的脚本。访问其脚本地址 https://wxaiway.com/dw/,按照上述方法添加并启动脚本。

需要注意的是,在添加脚本之前,你需要打开“开发者模式”。以 Edge 浏览器为例,打开 edge://extensions/,勾选“开发者模式”选项。
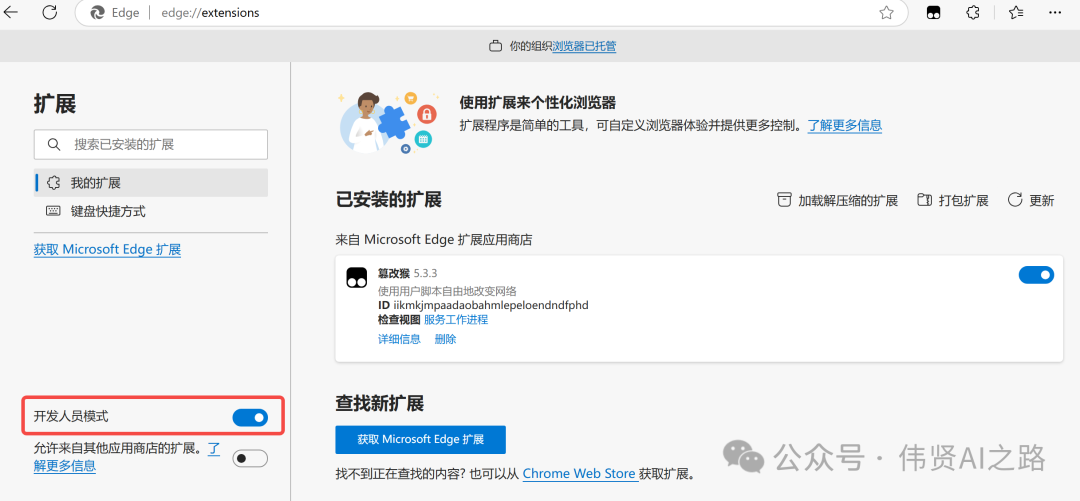
最终效果
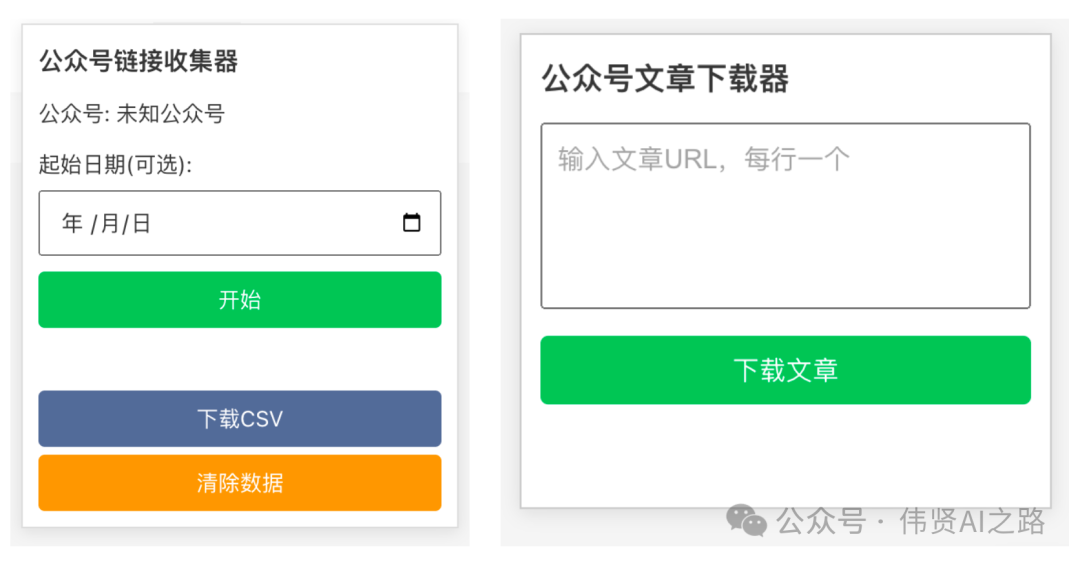
三、开始收集链接
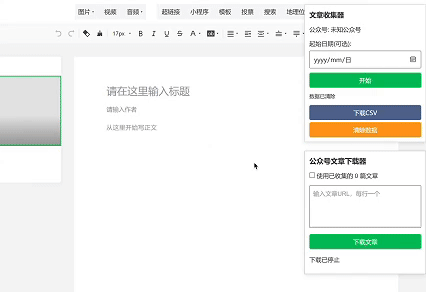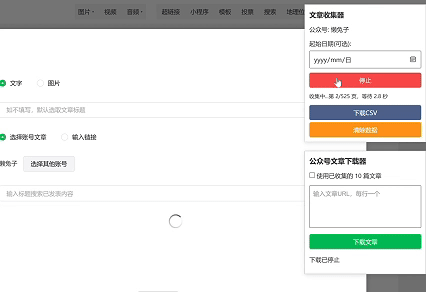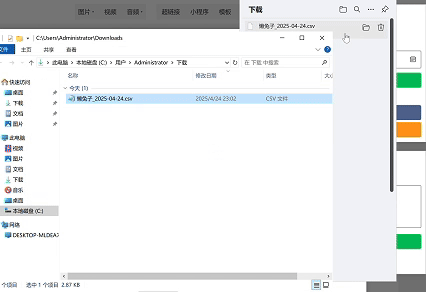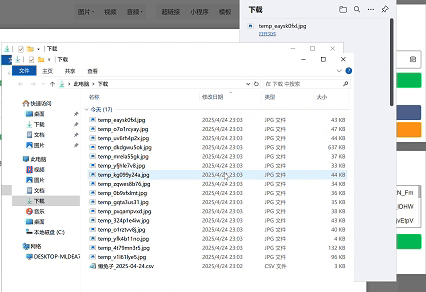
一切准备就绪后,就可以开始收集公众号文章链接了。打开微信公众号平台,登录你的账号,进入“内容管理”-“草稿箱”-“新的创作”-“写新文章”,此时你就会看到公众号链接收集器的界面。
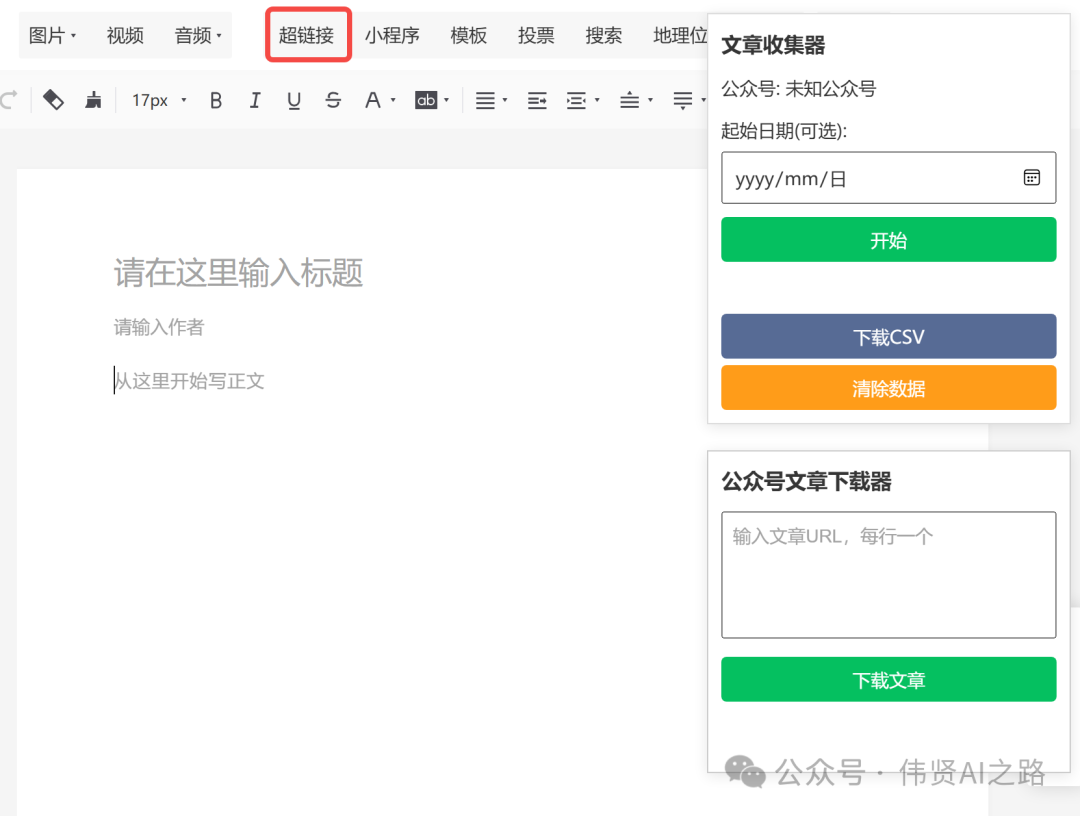
点击“超链接”,就可以选择其他账号进行收集公众号文章链接了。你可以轻松地将感兴趣的公众号文章链接添加到你的收藏列表中,方便后续进行进一步的整理和分析。
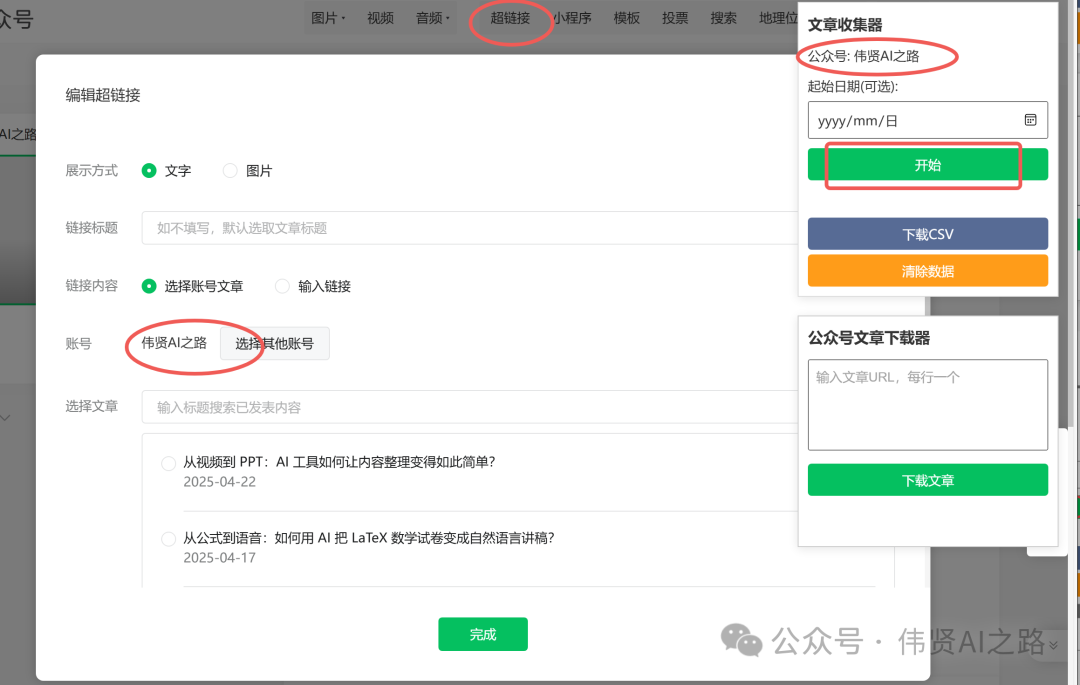
下载文章还有一个办法是参考《AI 编程小白必看:如何批量下载公众号文章为 Markdown 格式》文章,使用 python 来实现批量下载。
四、核心逻辑
链接收集器工作原理
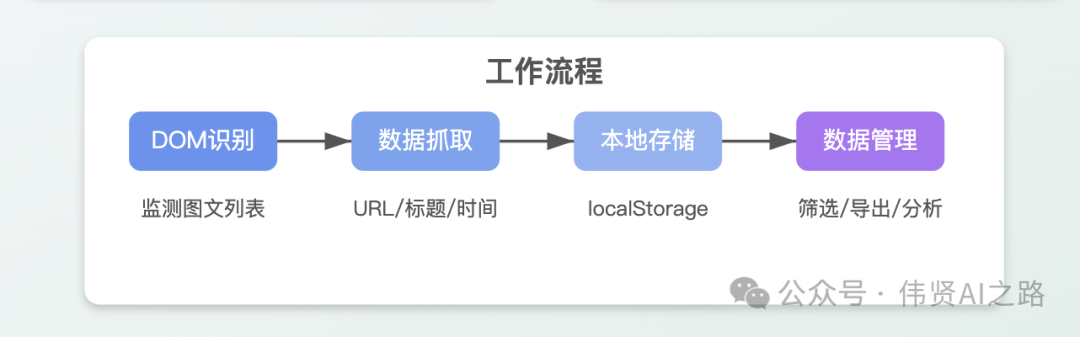
- 🕵️♂️ 智能识别:通过 DOM 解析实时监测公众号后台的图文列表
- 🔍 数据抓取:自动提取每篇文章的:
- 完整 URL 链接
- 文章标题
- 发布时间
- 📦 本地存储:使用 localStorage 保存数据(支持 3000+条记录)
文章下载器工作原理
-
1. 链接输入:
- 手动粘贴 URL
- 自动同步链接收集器的数据
- 支持批量导入(每行一个链接)
-
2. 内容下载:
- 🌐 模拟浏览器请求获取完整 HTML
- 🖼️ 自动识别内嵌图片/视频
- 📄 正文内容提取(支持付费文章预览)
-
3. 格式转换:
- 使用 Turndown.js 将 HTML 转为 Markdown
- 保持排版结构(标题/列表/表格等)
- 图片本地化(自动重命名存储)
通过以上简单的几步操作,你就可以高效地收集微信公众号文章链接了。希望这个小技巧能够帮助你在公众号运营的道路上更加得心应手,轻松发现更多优质的内容资源!
往期精彩
从公式到语音:如何用 AI 把 LaTeX 数学试卷变成自然语言讲稿?
从 AI 生成试卷到专业 Word 排版:MD2WD 高效解决方案


















 3846
3846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









