







原文:免费也能用得爽!即梦AI与通义万相、可灵AI的全面对比!
不同的 AI 工具在功能、速度和用户体验上各有千秋。我最近在做古诗的视频,所以用得比较多 AI 工具,以下是对国内可灵、通义万相和即梦 AI 的全面对比,帮助你选择最适合的 AI 工具。
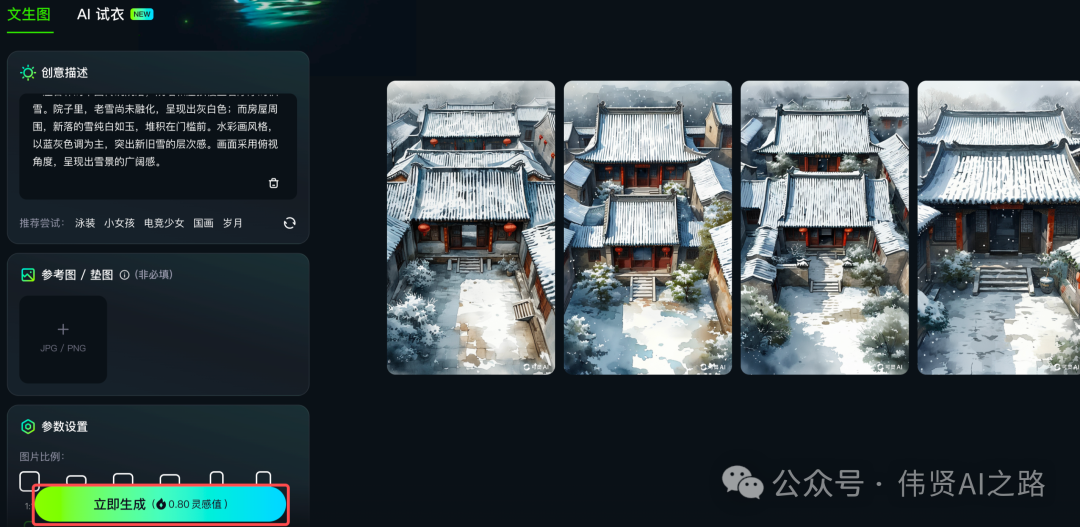
可灵AI(不充值无法用)
- 功能限制:不充值的话,很多功能都无法使用,这在一定程度上限制了创作体验的自由
- 文生图速度:生成速度尚可,但生成高清图需要开通会员,且有水印,影响最终效果
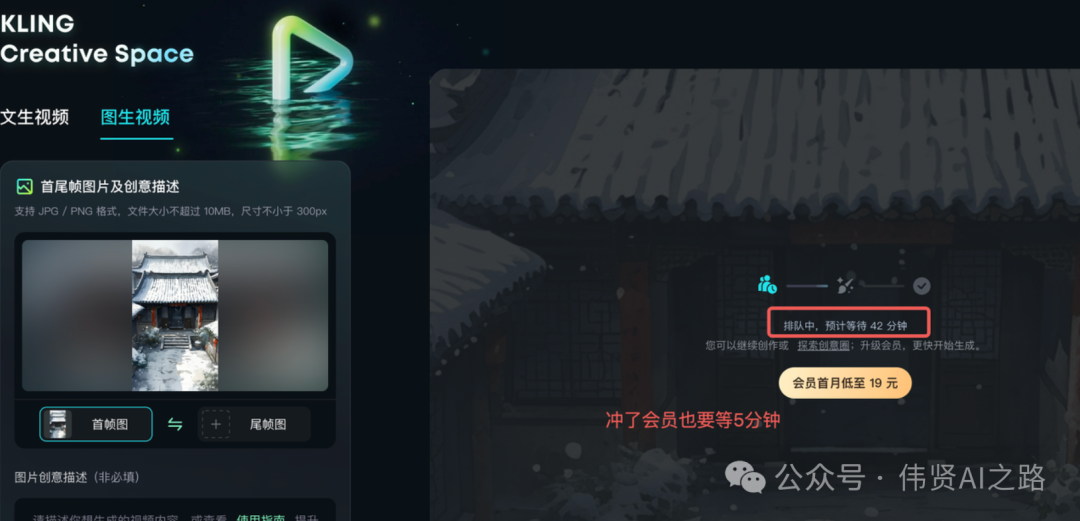
- 图生视频速度:速度较慢,不充值时需要 40 分钟以上,即使充值后也需要 5 分钟,且需要排队等待,不太适合需要快速生成视频的用户
- 用户体验:整体体验一般,功能受限和等待时间较长是主要问题
💡
可灵的文生图功能
https://klingai.kuaishou.com/
图生视频比较慢,要 40 分钟以上,充会员后也还需要 5 分钟,真的是蛮慢的。
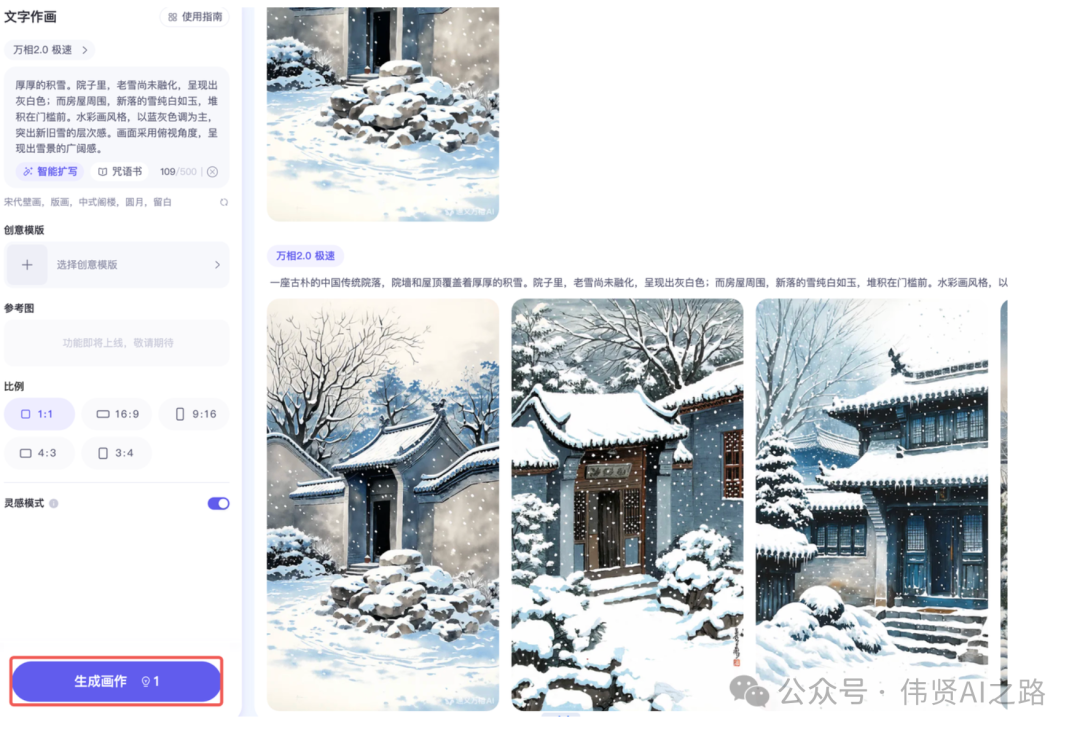
通义万相(免费-勉强用用)
- 免费使用:虽然可以免费使用,但体验较为勉强
- 文生图速度:速度时快时慢,有时会卡在 97%,需要重新刷新页面才能完成,影响创作效率
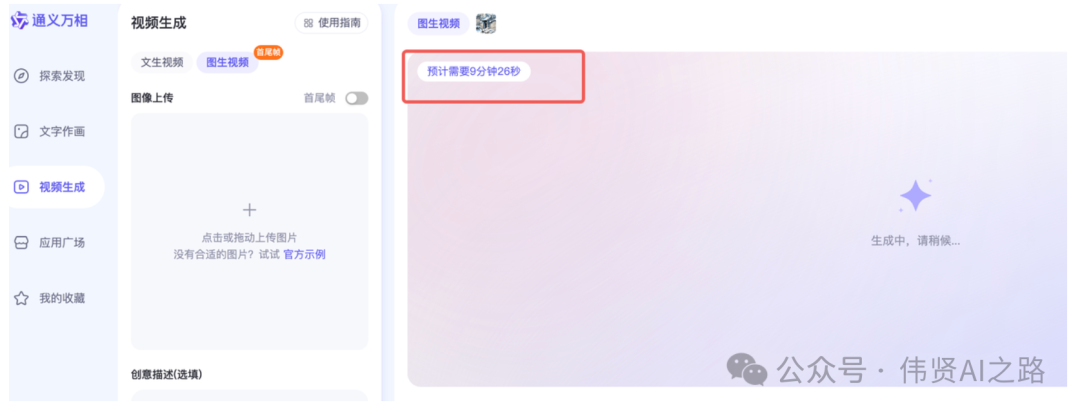
- 图生视频速度:10 分钟左右,速度尚可
- 用户体验:操作体验较差,页面跳转频繁,信息需要重新填写,给用户带来不便
💡
通义万相的文生图
https://tongyi.aliyun.com/wanxiang/creation
可以直接根据放大后图片生成视频,但是跳到新页面。
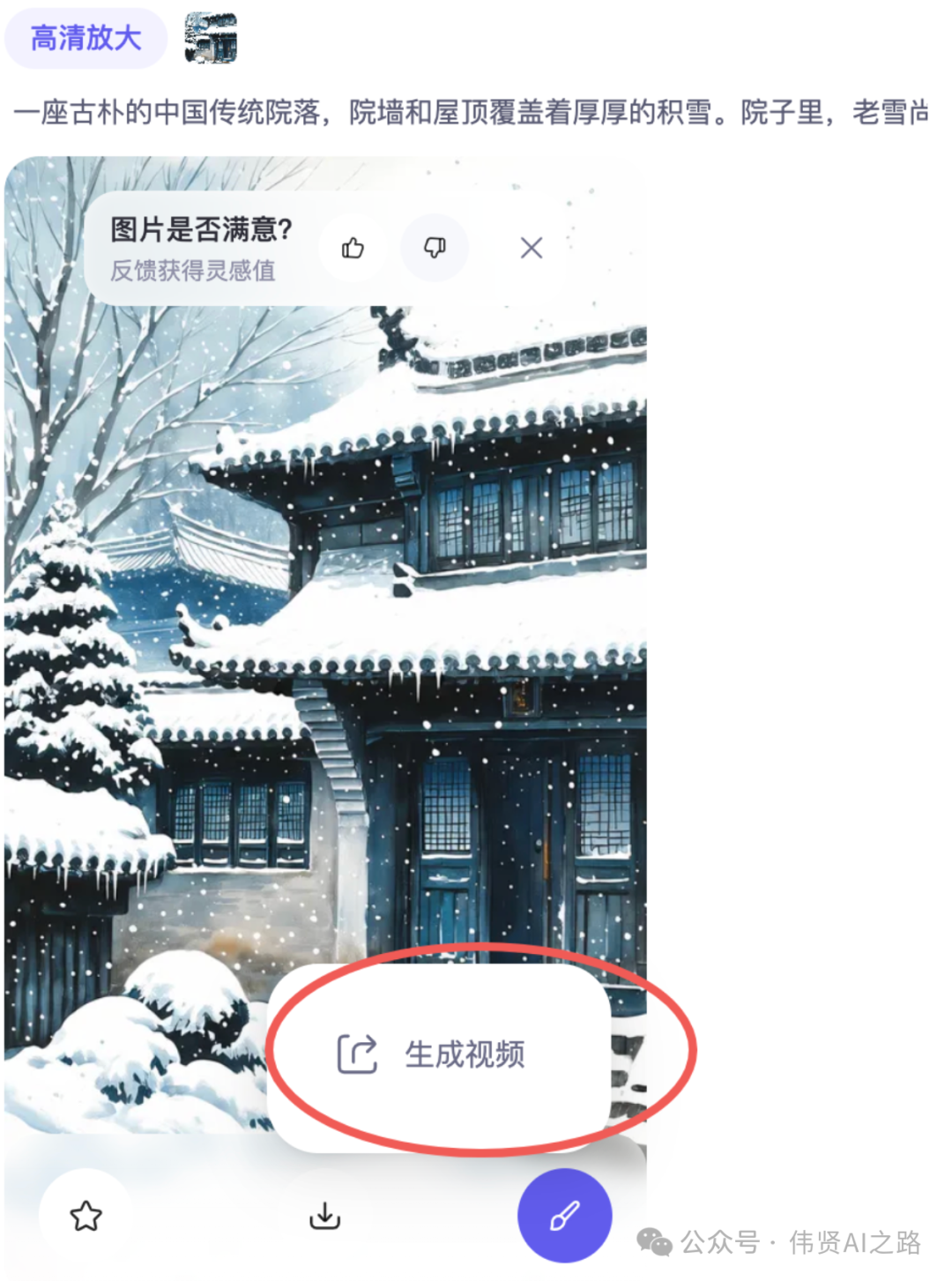
图生视频的速度 10 几分钟,只能免费用用。
操作体验比较差,各种跳转,然后信息都要重新填过。
即梦AI(免费-推荐使用)
- 免费且功能丰富:即使不充值也能使用许多功能,非常适合普通用户
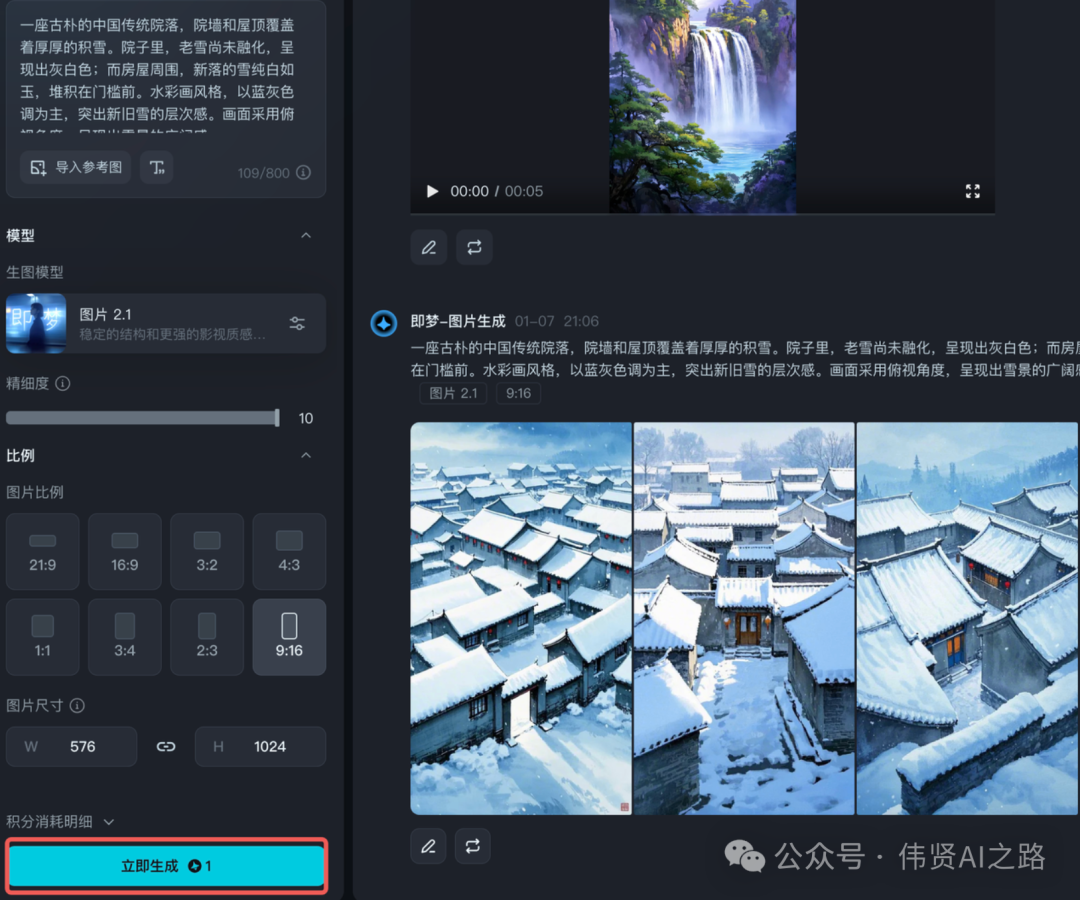
- 文生图速度:速度非常快,网页查看的图都是无水印的,生成高清图也是免费的,让你的创作更加高效
- 图生视频速度:速度同样很快,质量不错,满足了用户对视频生成的需求
- 用户体验:文生图和图生视频都在同一个页面,操作体验非常友好,无需频繁跳转和重复填写信息
- 特色功能:特别喜欢“消除笔”功能,可以轻松清除局部不喜欢的图像,让创作更加灵活
💡
即梦的文生图
https://jimeng.jianying.com/ai-tool/image/generate
我比较喜欢的功能是“消除笔”这个功能,可以把局部不喜欢的图清掉。

图生视频的速度也是很快,而且质量不错,我的古诗视频基本都是即梦AI生成的。文生图和图生视频都在同一个页面,批量操作体验比较友好。
总结
综合来看,【即梦 AI】在免费使用的情况下,功能丰富且生成速度快,网站操作体验也非常友好,非常适合普通用户。相比之下,【通义万相】虽然免费,但在操作体验和生成速度上都不如即梦 AI。而【可灵 AI】在不充值的情况下功能受限,即使充值后图生视频的速度也需要等待,不太适合追求高效创作的用户。
因此,如果你是普通用户,希望在不充值的情况下也能享受到高效、便捷的创作体验,【即梦 AI】 无疑是最佳选择。
其它精彩:

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









