







1、zip函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
2、案例演示
关于电影票房的数据我是在艺恩-数据智能服务商-年度票房中找的,给大家一个参考链接艺恩-数据智能服务商-年度票房
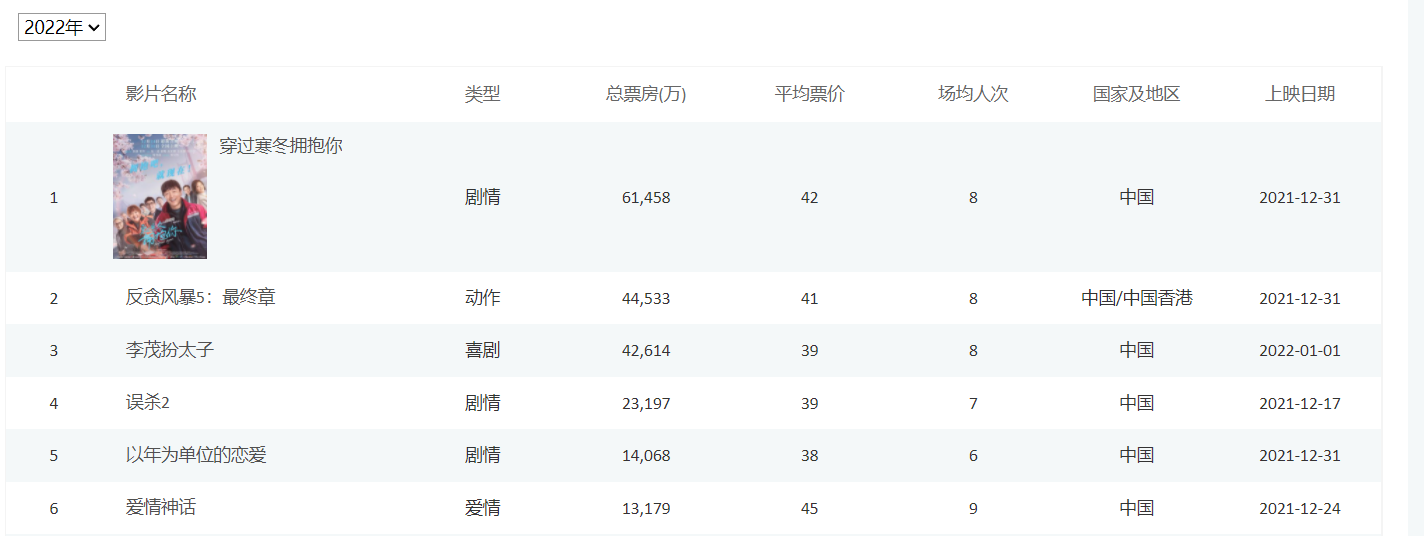
str='''
1
穿过寒冬拥抱你
剧情 61,181 42 9 中国 2021-12-31
2
反贪风暴5:最终章
动作 44,303 41 8 中国/中国香港 2021-12-31
3
李茂扮太子
喜剧 42,439 39 8 中国 2022-01-01
4
误杀2
剧情 22,984 39 8 中国 2021-12-17
5
以年为单位的恋爱
剧情 13,979 38 6 中国 2021-12-31
6
爱情神话
爱情 13,179 45 9 中国 2021-12-24
7
黑客帝国:矩阵重启
动作 7,479 38 3 美国 2022-01-14
8
雄狮少年
动画 7,441 40 8 中国 2021-12-17
9
魔法满屋
动画 6,095 38 6 美国 2022-01-07
10
汪汪队立大功大电影
动画 5,068 32 5 美国 2022-01-14
'''
我选了10个数据,经过自己稍作整理:
filmnames=['穿过寒冬拥抱你','反贪风暴5:最终章','李茂扮太子','误杀2','以年为单位的恋爱','爱情神话','黑客帝国:矩阵重启','雄狮少年','魔法满屋','汪汪队立大功大电影']
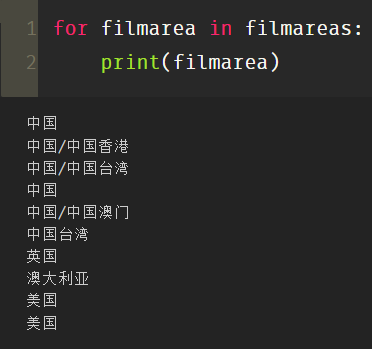
filmareas=['中国','中国/中国香港','中国/中国台湾','中国','中国/中国澳门','中国台湾','英国','澳大利亚','美国','美国']
filmboos=['61,181','44,303','42,439','22,984','13,979','13,179','7,479','7,441','6,095','5,068']
filmtypes=['剧情','动作','喜剧','剧情','剧情','爱情','动作','动画','动画','动画']
先写一个循环看看:
for filmname in filmnames:
print(filmname)
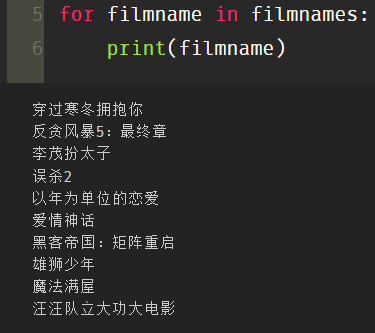
for filmboo in filmboos:
print(filmboo)
for filmarea in filmareas:
print(filmarea)
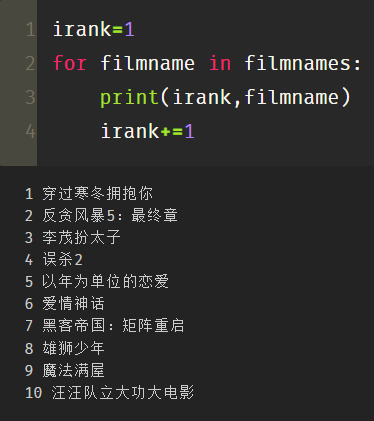
使用循环,创建变量irank加上序号:
irank=1
for filmname in filmnames:
print(irank,filmname)
irank+=1
使用打包函数zip:
for index,filmname,filmarea,filmtype,filmboo in zip(range(10),filmnames,filmareas,filmtypes,filmboos):
print(index+1,filmname,filmarea,filmtype,' 当前电影票房:',filmboo)

变化一下格式,使之更加美观:
for index,filmname,filmarea,filmtype,filmboo in zip(range(10),filmnames,filmareas,filmtypes,filmboos):
print(f"{index+1}. 《{filmname}》上映地区:{filmarea},电影类型:{filmtype},当前电影票房:{filmboo}" )

还可以将zip()函数与np结合输出:
import numpy as np
for irank,filmname,filmarea,filmtype,filmboo in zip(np.arange(1,len(filmnames)+1),filmnames,filmareas,filmtypes,filmboos):
print(f"{irank}. 《{filmname}》上映地区:{filmarea},电影类型:{filmtype},当前电影票房:{filmboo}" )
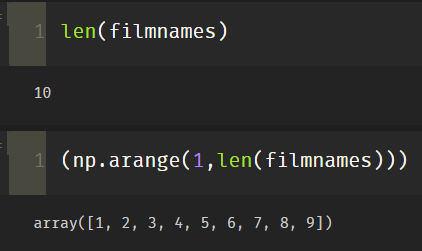
注意:这里是len(filmnames)+1,即要加1,因为:
np.arange(1,len(filmnames))得到的结果只有9,因此10部电影要+1
除了zip()函数之外,还可以使用枚举函数 enumerate()
enumerate()不仅可以将对应的可迭代对象进行提取,并且将对应的索引进行提取- 使用
enumerate的前提是电影票房,上映地区等等都要一一对应
for idex,filmname in enumerate(filmnames): #枚举函数的作用
print(idex+1,filmname)

for index,filmname in enumerate(filmnames):
print(f"{index+1}. 《{filmname}》上映地区:{filmareas[index]},电影类型:{filmtypes[index]},当前电影票房:{filmboos[index]}" )

















 3276
3276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











