









文章目录
一、PCA降维
1、降维究竟是怎样实现的
【1】降维:会减少特征,删除数据,可能使得模型受影响
【2】噪音:衡量特征之间的线性相关
【3】PCA(主成分分析)使用样本方差作为信息量衡量的指标
(在PCA当中,以信息量作为衡量标准指的就是样本方差)
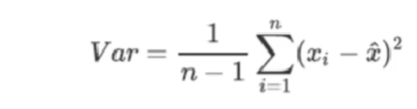
参数:
【1】Var:特征方差
【2】n:样本量
【3】xi:特征当中的样本值
【4】x^hat:列样本均值
如下图实现从二维到一维的降维过程,即通过对坐标轴进行旋转,使得样本数据落在X轴上,变成一维的数据。
当然,实际情况肯定不是通过旋转坐标轴的方式进行降维的,而是通过一定的数学分析计算实现的。(比如支持向量机SVM)
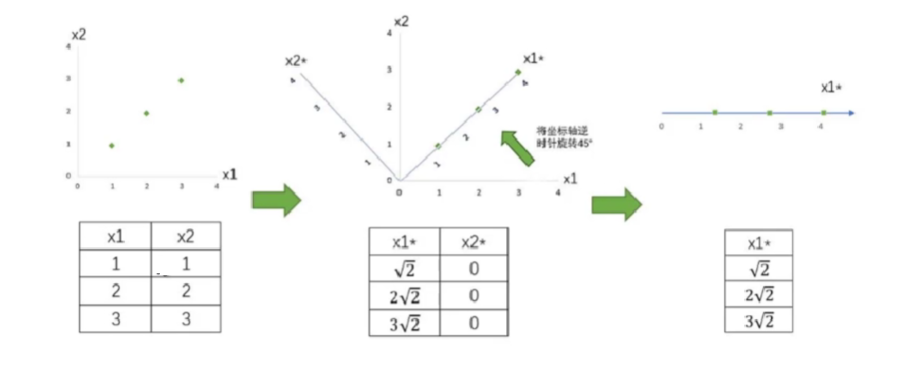
首先:去中心化(把坐标原点放在数据中心,与均值有关)
然后:找坐标系(找到方差最大的方向)
由下面这个公式可以看出,从二维降到一维,但是样本数据的方差是不变的。
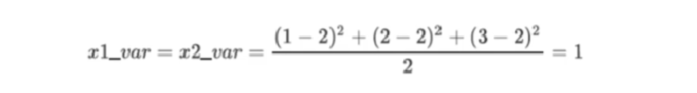
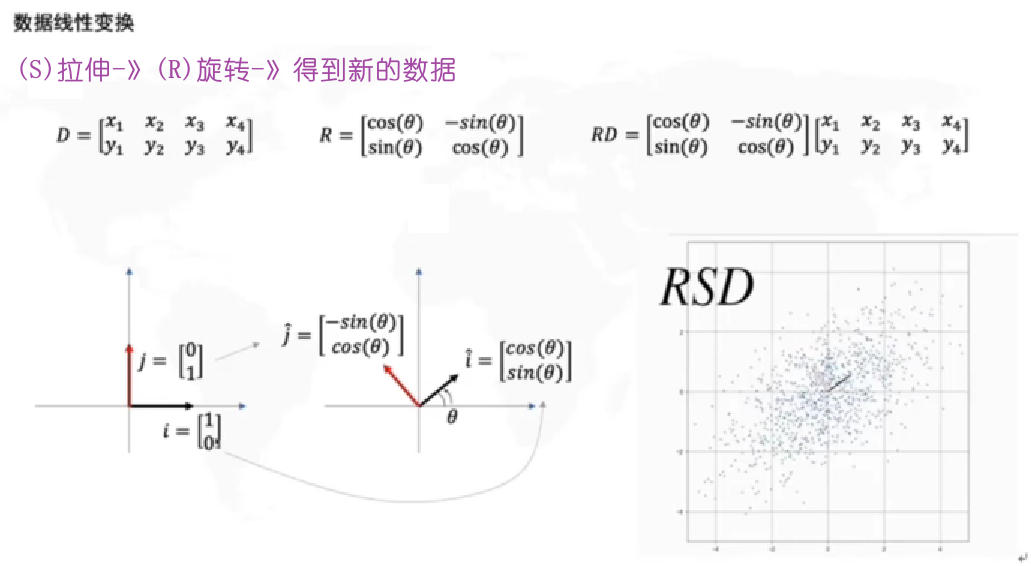
RSD定义:相对标准偏差(relative standard deviation;RSD)又叫标准偏差系数、变异系数、变动系数等,由标准偏差除以相应的平均值乘100%所得值,可在检验检测工作中分析结果的精密度。
2、二维特征矩阵降维的一般过程
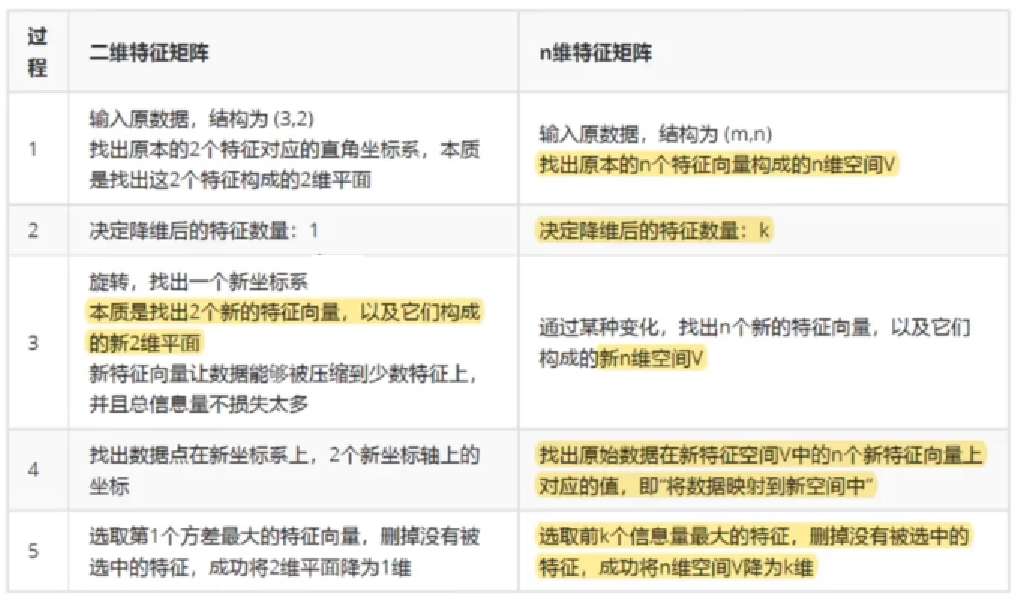
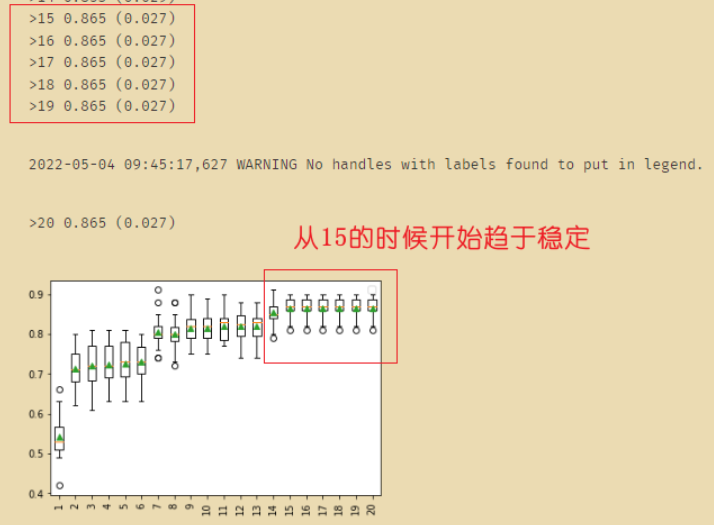
关于上图当中的n维特征矩阵的降维后的特征数量是k个,应该如何寻找?
我们可以通过学习曲线,找到当数值趋于一定的范围时会保持不变,这是就找到k值了。
比如下图当中的15就是k值:
关键步骤:找出n个新的特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解
3、PCA降维与特征选择的不同
-
特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,依然知道这个特征在原数据的哪个位置,代表着原数据上的什么含义。
-
PCA在新的特征矩阵生成之前,无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性。
-
PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,使用特征选择
二、 PCA与SVD
- PCA与SVD是两种不同的降维算法,但是他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的步骤不同,信息量衡量的指标不同。PCA使用方差作为信息量衡量的指标,并通过特征值分解来找出空间V。
- SVD包含PCA的所有功能。
- SVD使用奇异值分解找出空间V,在降维是会产生协方差矩阵,将特征矩阵X分解为三个矩阵。
注意:
- 数据预处理,只有数值型数据才能进行PCA
- 无论是PCA还是SVD都要遍历所有的特征和样本来计算信息量指标,并且在矩阵分解的过程中,会产生比原矩阵更大的矩阵,比如原数据结构是(m,n),在矩阵分解中为了找出最佳的新特征空间V,可能需要产生(n,n)(m,m)大小的矩阵,还需要产生协方差矩阵去计算更多的信息。
1、重要参数n_components
【1】降维后所需要的维度,即降维后需要保留的特征数量
【2】需要确认的K值,一般输入[0,min(X.shape)]范围中的整数。太大达不到降维效果,太小无法还原原始数据所内含的大部分信息,会丢失需要内含的参数。
2、迷你案例:高维数据的可视化(鸢尾花)
# 1. 调用库和模块
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 2. 提取数据集
iris = load_iris()
y = iris.target
X = iris.data
X.shape #二维数组

# 3. 建模
#调用PCA
pca = PCA(n_components=2) #实例化,从4维降到2维
pca = pca.fit(X) #拟合模型
pca
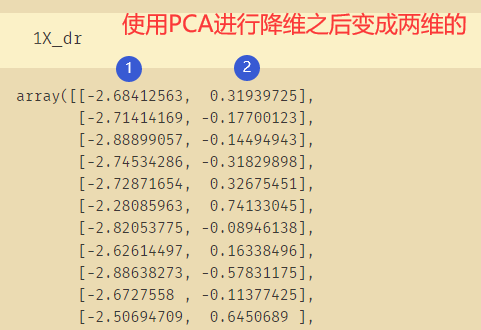
X_dr = pca.transform(X) #获取新矩阵 dimeesion reduction 降维
X_dr
- 使用PCA当中的
n_components=2参数进行降维,如果n_components=1则会降维成一维,但是数据仍然是使用二维数组的形式来表示,因为sklearn很多情况下只能使用二维以上的数据。 - 上面的建模代码可以使用下面的这句代码一部就完成,因为
fit_transform()函数相当于完成了fit和transform两步操作。
X_dr=PCA(2).fit_transform(X) #一步完成新矩阵的获取

# 4.可视化
X_dr[y==0,0]
X_dr[y==1,0]
X_dr[y==2,0]
逗号后面的0表示提取的是第一维度的特征

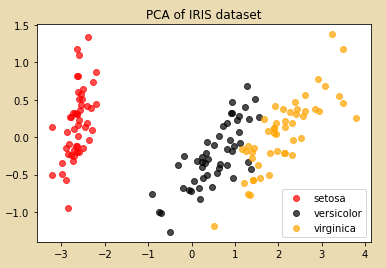
方法一:
plt.figure()
plt.scatter(X_dr[y==0, 0], X_dr[y==0, 1], c="red", label=iris.target_names[0])
plt.scatter(X_dr[y==1, 0], X_dr[y==1, 1], c="black", label=iris.target_names[1])
plt.scatter(X_dr[y==2, 0], X_dr[y==2, 1], c="orange", label=iris.target_names[2])
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()
方法二:
#等价
colors = ['red', 'black', 'orange']
iris.target_names
plt.figure()
for i in [0, 1, 2]:
plt.scatter(X_dr[y == i, 0]
,X_dr[y == i, 1]
,alpha=.7
,c=colors[i]
,label=iris.target_names[i]
)
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()
方法三:
#等价
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
colors = ['red', 'black', 'orange']
plt.figure() # 初始化一个画布
for i in [0, 1, 2]:
plt.scatter(X_dr[y == i, 0], X_dr[y == i, 1], alpha=0.7, c=colors[i], label=iris.target_names[i])
plt.legend() # 加图例
plt.title('PCA of IRIS dataset') # 加标题
plt.show()
# 6、探索降维之后的数据
# 对降维之后两个特征进行比较
pca.explained_variance_
pca.explained_variance_ratio_
【1】explained_variance :查看降维之后每个新特征向量上所带的信息量大小,可解释性的方差大小,方差越大,该特征越重要
【2】explained_variance_ratio :查看降维后每个新特征向量所占的信息量占原始数据总信息量的比例


# 7. 选择最好的n_components:累积可解释方差贡献率曲线
import numpy as np
pca_line = PCA().fit(X)
# pca_line.explained_variance_ratio_ 四个特征中每个保留信息量的百分比
plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_))
plt.xticks([1,2,3,4]) #这是为了限制坐标轴显示为整数
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()
上面代码当中的plt.plot([1,2,3,4]中的1,2,3,4本质上改变的就是参数n_components
下图X轴表示:降维之后剩下的特征个数。Y轴表示:降维后的准确率。
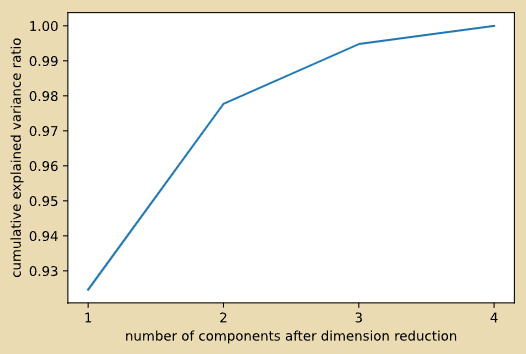
就上图而言,只有4个维度,较少,没有必要降维,但如果在维数较大的情况下,我们会选择2,因为2的正确率有转折点。
3、最大似然估计自选超参数
n_components还有哪些可选择?
-
最大似然估计:maximum likelihoodestimation mle 利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。
-
对于P(x∣θ)这个函数,输入有两个:x表示某一个具体的数据,θ表示模型的参数
-
如果θ是已知确定的, x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点 x,其出现概率是多少。
-
如果 x是已知确定的,θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现 x这个样本点的概率是多少。
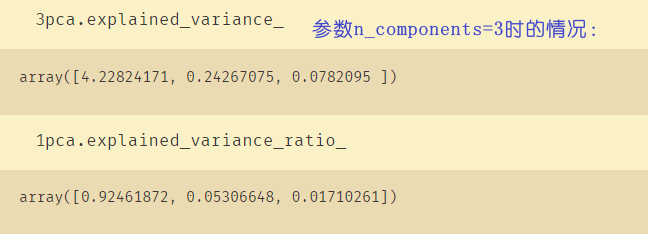
pca_mle = PCA(n_components="mle")
pca_mle = pca_mle.fit(X)
X_mle = pca_mle.transform(X)
X_mle #mle自动选择了多少个特征
# mle:自动选择了3个特征
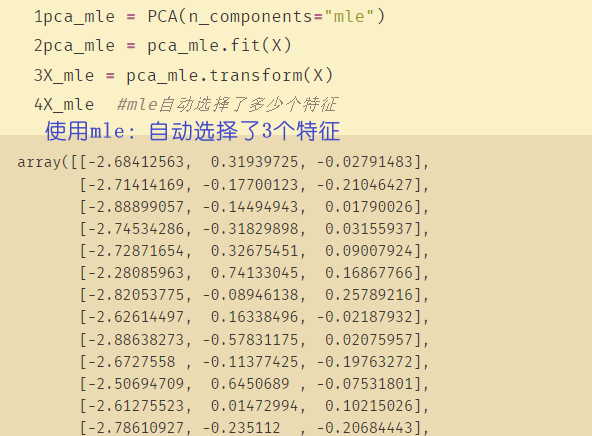
4、按信息量占比选超参数
- n_componets=0.97代表PCA会自动选出能够让保留的信息量超过97%的特征数量
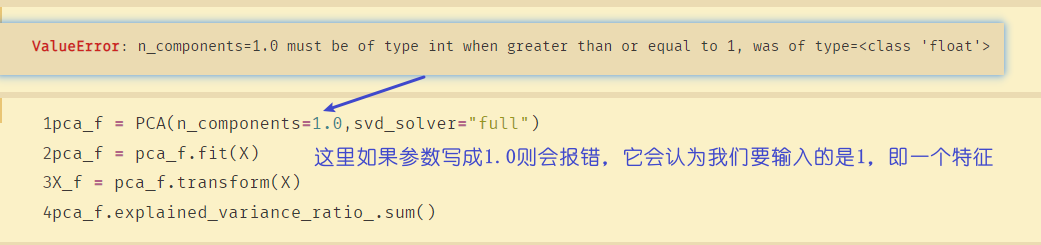
pca_f = PCA(n_components=0.97,svd_solver="full")
pca_f = pca_f.fit(X)
X_f = pca_f.transform(X)
pca_f.explained_variance_ratio_ #mle自动选择了多少个特征
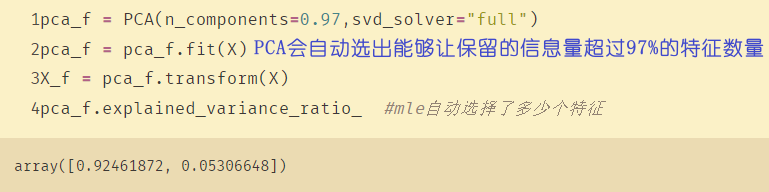
从上图可以看出,如果选择两个保留的信息量超过97%,则应该选择保留两个特征。
pca_f.explained_variance_ratio_.sum()

5、分析计算过程(以啤酒消费为例子)
def plot_vectors(vectors=[(0, 0, 1, 2),(0, 0, 3, 1)],
texts=[r'$\vec{a}$', r'$\vec{b}$', 'power vec', 'power vec2'],
texts_locs=[(0.5, 0.7), (0.2, 0.8), (0.7, 0.5), (0.5, 0.5)], text_size=18,
colors=["#2EBCE7","#00E64E", "purple", 'orange'],
xlim=(-1, 3), ylim=(-1,3), x_label='x', y_label='y',
scale=1, scale_units='xy'):
fig, ax =plt.subplots(figsize=(6,6))
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
for i, vec in enumerate(vectors):
ax.quiver(*vec, color=colors[i], angles='xy', scale_units=scale_units, scale=scale)
plt.text(*texts_locs[i], texts[i], color=colors[i], size=text_size)
# draw axes
plt.axhline(0, c='#d6d6d6', zorder=0)
plt.axvline(0, c='#d6d6d6', zorder=0)
plt.xlim(*xlim)
plt.ylim(*ylim)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.show()
return ax
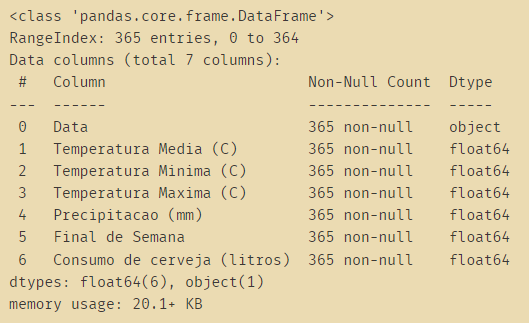
啤酒消费的数据:
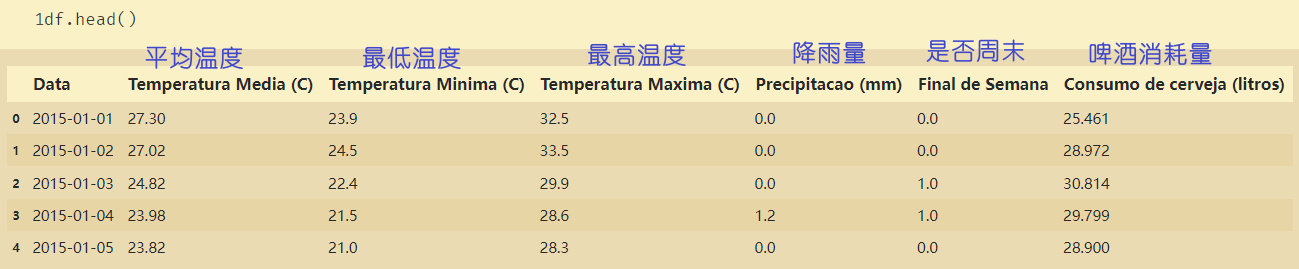
【1】‘Temperatura Media ©’:平均温
【2】‘Temperatura Minima ©’:最低温
【3】‘Temperatura Maxima ©’:最高温
【4】‘Precipitacao (mm)’:降雨量
【5】‘Final de Semana’:是否周末
【6】‘Consumo de cerveja (litros)’:相当于标签
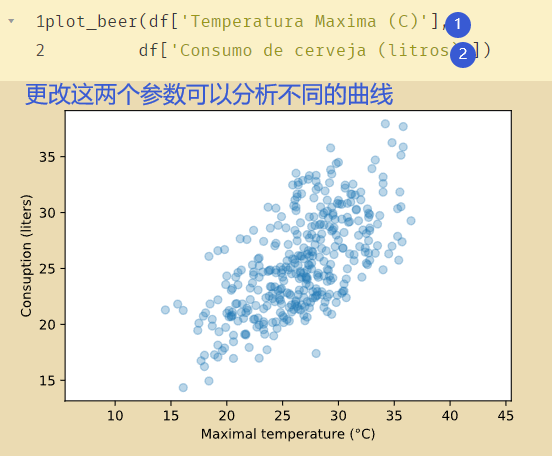
def plot_beer(x, y, x_label="Maximal temperature ($\degree$C)", y_label="Consuption (liters)",
alpha=0.3, draw_axes=False):
plt.scatter(x, y, alpha=alpha)
plt.xlabel(x_label)
plt.ylabel(y_label)
# Assure that ticks are displayed with a specific step
ax = plt.gca()
ax.xaxis.set_major_locator(ticker.MultipleLocator(5))
ax.yaxis.set_major_locator(ticker.MultipleLocator(5))
if draw_axes:
# draw axes
plt.axhline(0, c='#d6d6d6', zorder=0)
plt.axvline(0, c='#d6d6d6', zorder=0)
# assure x and y axis have the same scale
plt.axis('equal')
plt.show()

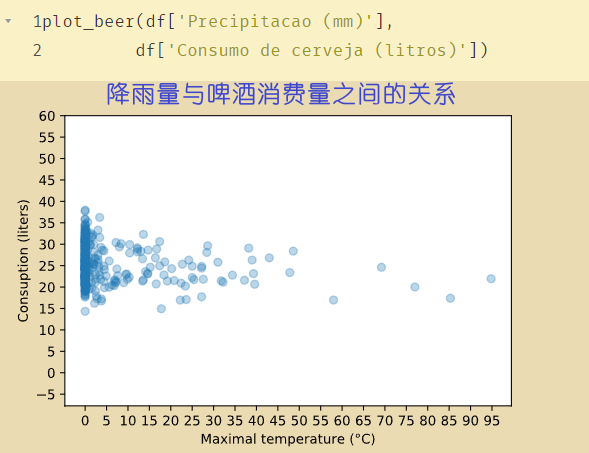
# 1、创建新的数据集
X = np.array([df['Temperatura Maxima (C)'],
df['Consumo de cerveja (litros)']]).T
# 2、计算协方差矩阵
C = np.cov(X, rowvar=False)
C
# 3、计算均值,数据中心化
X_norm=X.copy()
X_norm-=X.mean(axis=0)
# 4、定义计算特征,计算函数与SVD超级迭代函数
def eigenvalue(A, v):
val = A @ v / v
return val[0]
def svd_power_iteration(A):
n, d = A.shape
v = np.ones(d) / np.sqrt(d)
ev = eigenvalue(A, v)
while True:
Av = A @ v
v_new = Av / np.linalg.norm(Av)
ev_new = eigenvalue(A, v_new)
if np.abs(ev - ev_new) < 0.01:
break
v = v_new
ev = ev_new
return ev_new, v_new
eigen_value, eigen_vec = svd_power_iteration(C)
得到的特征值:
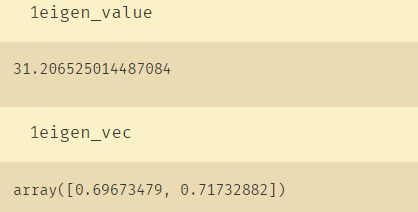
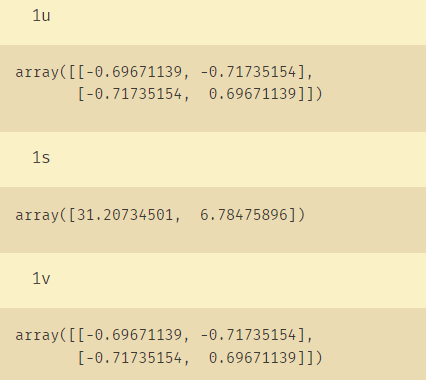
与numpy的计算功能对比:
# 与numpy的计算功能对比
u, s, v=np.linalg.svd(C, 1)
下面的三个参数是numpy中的SVD的解释:
# 寻找主要的特征向量
def plot_eigenvectors(eigen_vecs, eigen_values, colors=["#FF8177", "orange"]):
for i, eigen_vec in enumerate(eigen_vecs):
plt.quiver(0, 0,
2 * np.sqrt(eigen_values[i]) * eigen_vec[0], 2 * np.sqrt(eigen_values[i]) * eigen_vec[1],
color=colors[i], angles="xy", scale_units="xy", scale=1,
zorder=2, width=0.011)
plot_eigenvectors([eigen_vec], [eigen_value], colors=["#FF8177", "orange"])
plot_beer(X_norm[:, 0], X_norm[:, 1], draw_axes=True)
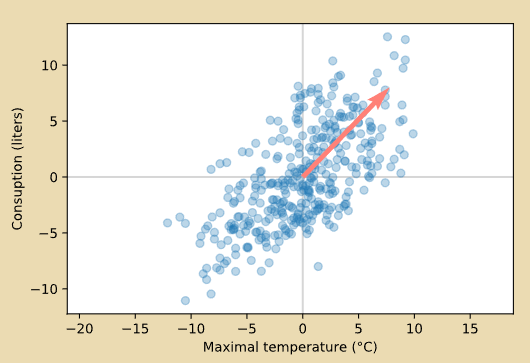
6、SVM,SVR,SVC的区别
- SVM=Support Vector Machine 是支持向量
- SVC=Support Vector Classification就是支持向量机用于分类
- SVR=Support Vector Regression.就是支持向量机用于回归分析
7、特征值与奇异值分解
#特征值分解
from scipy import linalg
import numpy as np
A=np.array([[1,2],[3,4]])
l,v=linalg.eig(A)
print(l)
print(v)
'''
[-0.37228132+0.j 5.37228132+0.j]
[[-0.82456484 -0.41597356]
[ 0.56576746 -0.90937671]]
'''
#奇异值分解
from numpy import *
data=mat([[1,2,3],[4,5,6]])
U,sigma,VT=np.linalg.svd(data)
print('U:',U)
print('SIGMA:',sigma)
print('VT:',VT)
'''
U: [[-0.3863177 0.92236578]
[-0.92236578 -0.3863177 ]]
SIGMA: [9.508032 0.77286964]
VT: [[-0.42866713 -0.56630692 -0.7039467 ]
[-0.80596391 -0.11238241 0.58119908]
[ 0.40824829 -0.81649658 0.40824829]]
'''
#奇异值分解 2
from numpy import *
data=mat([[1,2,3],[4,5,6],[7,8,9]])
U,sigma,VT=np.linalg.svd(data)
print('U:',U)
print('SIGMA:',sigma)
print('VT:',VT)
'''
U: [[-0.21483724 0.88723069 0.40824829]
[-0.52058739 0.24964395 -0.81649658]
[-0.82633754 -0.38794278 0.40824829]]
SIGMA: [1.68481034e+01 1.06836951e+00 4.41842475e-16]
VT: [[-0.47967118 -0.57236779 -0.66506441]
[-0.77669099 -0.07568647 0.62531805]
[-0.40824829 0.81649658 -0.40824829]]
'''
#奇异值分解 3
from numpy import *
data=mat([[1,2,3],[4,5,6],[7,8,9],[11,22,33]])
U,sigma,VT=np.linalg.svd(data)
print('U:',U)
print('SIGMA:',sigma)
print('VT:',VT)
'''
U: [[-0.0844147 -0.03251869 0.53753816 -0.83837308]
[-0.19452796 0.40431201 0.75055526 0.48513655]
[-0.30464122 0.84114271 -0.37527763 -0.24256827]
[-0.92856166 -0.35770557 -0.08298325 0.05416407]]
SIGMA: [4.42965582e+01 4.10060089e+00 1.49502706e-15]
VT: [[-0.29819909 -0.54195984 -0.78572058]
[ 0.86279235 0.19902982 -0.46473271]
[ 0.40824829 -0.81649658 0.40824829]]
'''
8、案例:猩猩图片处理
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
im=np.array(Image.open('hxx00.jpg')) #图片不能太大
plt.imshow(im,cmap='Greys_r')
plt.title('SRC')
plt.axis('off')

得到图片的长宽像素:为后期压缩做调整
im.shape
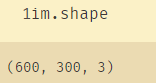
#对图像进行SVD转换
U,sigma,VT=np.linalg.svd(im)
print("前30个特征值是:\n",sigma[:30])
#对图像进行SVD转换
U,sigma,VT=np.linalg.svd(im)
print("前30个特征值是:\n",sigma[:30])
#分别使用10、50个特征值重构图像
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 读取图片
img_eg = mpimg.imread(r"hxx00.jpg") # 535,095=3*3*5*11*23*47 3*5*23=,3*11*47=517*3
print(img_eg.shape)
# 奇异值分解
img_temp = img_eg.reshape(300,600*3)
U, Sigma, VT = np.linalg.svd(img_temp)
print(Sigma)
# 奇异值分解:我们先将图片变成【400,450×3】,再做奇异值分解,并且从svd函数中得到的奇异值 sigma sigmasigma 它是从大到小排列的
# 取前10个奇异值
sval_nums = 10
img_restruct1 = (U[:,0:sval_nums]).dot(np.diag(Sigma[0:sval_nums])).dot(VT[0:sval_nums,:])
img_restruct1 = img_restruct1.reshape(600,300,3)
# 取前部分奇异值重构图片
# 1、如果处理的是一维数组,则得到的是两数组的內积。
# 2、如果是二维数组(矩阵)之间的运算,则得到的是矩阵乘法(mastrix product)。
# 3、np.diag(Sigma[0:sval_nums])对角矩阵
# 取前50个奇异值
sval_nums = 50
img_restruct2 = (U[:,0:sval_nums]).dot(np.diag(Sigma[0:sval_nums])).dot(VT[0:sval_nums,:])
img_restruct2 = img_restruct2.reshape(600,300,3) #
fig, ax = plt.subplots(1,3,figsize = (12,16))
ax[0].imshow(img_eg)
ax[0].set(title = "src")
ax[1].imshow(img_restruct1.astype(np.uint8))
ax[1].set(title = "nums of sigma = 10")
ax[2].imshow(img_restruct2.astype(np.uint8))
ax[2].set(title = "nums of sigma = 50")
plt.show()

















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











