







Actor Critic
结合Policy Gradient(Actor)和Function Approximation(Critic)的方法。Actor:基于概率选取行为,Critic基于Actor选取的星期进行打分,Actor根据Critic的评分进行修改选行为的概率。
优势:可以进行单步更新,比传统的PL要快 缺点:取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛。
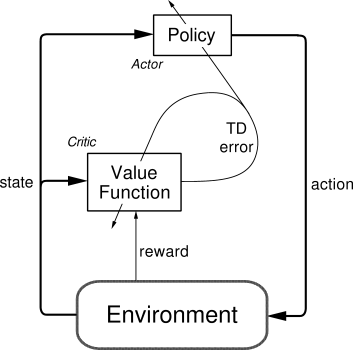
Actor 网络图: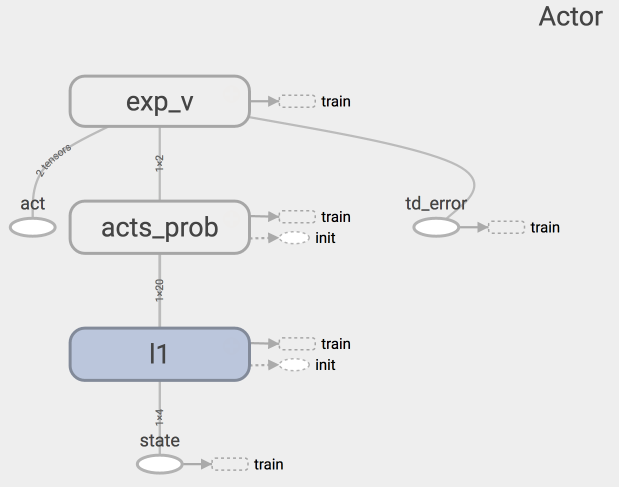
Actor网络的代码结构:
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
# 用 tensorflow 建立 Actor 神经网络,
# 搭建好训练的 Graph.
def learn(self, s, a, td):
# s, a 用于产生 Gradient ascent 的方向,
# td 来自 Critic, 用于告诉 Actor 这方向对不对.
def choose_action(self, s):
# 根据 s 选 行为 a
Critic网络图: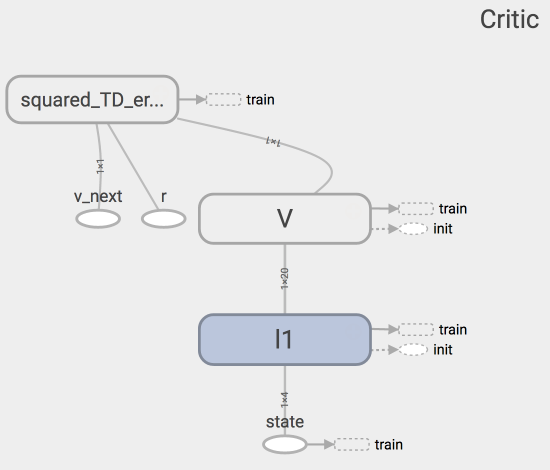
Critic代码结构:
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
# 用 tensorflow 建立 Critic 神经网络,
# 搭建好训练的 Graph.
def learn(self, s, r, s_):
# 学习 状态的价值 (state value), 不是行为的价值 (action value),
# 计算 TD_error = (r + v_) - v,
# 用 TD_error 评判这一步的行为有没有带来比平时更好的结果,
# 可以把它看做 Advantage
return # 学习时产生的 TD_error
整体代码:
'''
一句话概括 Actor Critic 方法:
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法.
Actor 基于概率选行为,
Critic 基于 Actor 的行为评判行为的得分,
Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快.
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新,
就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
不过那个是要以 Actor Critic 为基础, 懂了 Actor Critic, 后面那个就好懂了.
'''
#Actor 修改行为时就像蒙着眼睛一直向前开车, Critic 就是那个扶方向盘改变 Actor 开车方向的
#Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他
#这次的 Gradient ascent 是不是一次正确的 ascent, 如果这次的得分不好, 那么就不要 ascent 那么多
import numpy as np
import tensorflow.compat.v1 as tf
import gym
tf.compat.v1.disable_eager_execution()
np.random.seed(2)
tf.set_random_seed(2)
#超参数
OUTPUT_GRAPH = True
MAX_EPISODE = 3000
DISPLAY_REWARD_THRESHOLD = 200 #阈值 :如果奖励总奖励更大,则渲染环境较大,则此阈值
MAX_EP_STEPS = 1000 #最大迭代
RENDER = False #rendering wastes time
GAMMA = 0.9 # reward discount in TD error TD错误中的奖励折扣
LR_A = 0.001 #actor的学习率
LR_C = 0.01 #critic的学习率
env = gym.make('CartPole-v0')
env.seed(1)
env = env.unwrapped
N_F = env.observation_space.shape[0] #n_features 的值
N_A = env.action_space.n #n_actions 的值
#构建Actor网络
class Actor:
def __init__(self,sess, n_features, n_actions, lr=0.01):
# 用 tensorflow 建立 Actor 神经网络,
# 搭建好训练的 Graph
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features],'state')
self.a = tf.placeholder(tf.int32, None, 'act')
self.td_error = tf.placeholder(tf.float32, None, 'td_error')
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs = self.s,
units = 20,
activation = tf.nn.relu,
kernel_initializer = tf.random_normal_initializer(0., .1),
bias_initializer = tf.constant_initializer(0.1),
name = 'l1'
)
self.acts_prob = tf.layers.dense(
inputs = l1,
units = n_actions,
activation = tf.nn.softmax,
kernel_initializer = tf.random_normal_initializer(0.,.1),
bias_initializer = tf.constant_initializer(0.1),
name = 'acts_prob'
)
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
def learn(self, s, a, td):
# s, a 用于产生 Gradient ascent 的方向,
# td 来自 Critic, 用于告诉 Actor 这方向对不对.
s = s[np.newaxis, :]
feed_dict = {self.s : s, self.a : a, self.td_error : td}
_, exp_v = self.sess.run([self.train_op, self.exp_v],feed_dict)
return exp_v
def choose_action(self, s):
# 根据 s 选 行为 a
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s:s}) #获取所有操作的概率
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())
#构建Critic网络
class Critic:
def __init__(self, sess, n_features, lr=0.01):
# 用 tensorflow 建立 Critic 神经网络,
# 搭建好训练的 Graph.
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
self.r = tf.placeholder(tf.float32, None, 'r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs = self.s,
units = 20,
# have to be linear to make sure the convergence of actor. 必须是线性的,以确保演员的融合。
# But linear approximator seems hardly learns the correct Q.但线性近似器似乎几乎没有学习正确的Q.
kernel_initializer = tf.random_normal_initializer(0., .1),
bias_initializer = tf.constant_initializer(0.1),
name = 'l1'
)
self.v = tf.layers.dense(
inputs = l1,
units = 1, #输出点数
activation = None,
kernel_initializer = tf.random_normal_initializer(0., .1),
bias_initializer = tf.constant_initializer(0.1),
name = 'V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v # TD_error = (r+gamma*V_next) - V_eval
self.loss = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
#学习状态的价值(state value),不是行为的价值(action value)
#计算TD_error = (r + v_) - v
#用TD_error 评判这一步的行为有没有带来比平时更好的结果
#相当于Advantage
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error#学习时产生的TD_error
sess = tf.Session()
actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A)
critic = Critic(sess, n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER: env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
if done:
r = -20
track_r.append(r)
td_error = critic.learn(s, r, s_)
actor.learn(s, a, td_error)
s = s_
t += 1
if done or t >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
运行AC代码:
from Ac import Actor
from Ac import Critic
import numpy as np
import tensorflow as tf
import gym
#超参数
OUTPUT_GRAPH = True
MAX_EPISODE = 3000
DISPLAY_REWARD_THRESHOLD = 200 #阈值 :如果奖励总奖励更大,则渲染环境较大,则此阈值
MAX_EP_STEPS = 1000 #最大迭代
RENDER = False #rendering wastes time
GAMMA = 0.9 # reward discount in TD error TD错误中的奖励折扣
LR_A = 0.001 #actor的学习率
LR_C = 0.01 #critic的学习率
env = gym.make('CartPole-v0')
env.seed(1)
env = env.unwrapped
N_F = env.observation_space.shape[0] #n_features 的值
N_A = env.action_space.n #n_actions 的值
sess = tf.compat.v1.Session()
actor = Actor(sess, n_features = N_F,n_actions = N_A, lr = LR_A)
critic = Critic(sess, n_features = N_F, lr = LR_C)
sess.run(tf.compat.v1.global_variables_initializer())
if OUTPUT_GRAPH:
tf.compat.v1.summary.FileWriter('logs/',sess.graph)
Asynchronous Advantage Actor-Critic(A3C)
平行训练:

A3C采用一种平行训练,类似于多进程、多线程,采用Actor-Critic形式训练,当训练一对AC时将其复制成多份进行多核训练,然后将每部分的经验进行分享,综合多个经验进行选择。
简而言之,A3C是一种解决 Actor-Critic 不收敛问题的算法, 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数.。并行中的 agent 们互不干扰,,而主结构的参数更新受到副结构提交更新的不连续性干扰,所以更新的相关性被降低,,收敛性提高。
算法伪代码:

为了实现A3C,需要两个体系,中央大脑拥有 global net 和他的参数, 每个环境 worker 有一个 global net 的副本 local net, 可以定时向 global net 推送更新, 然后定时从 global net 那获取综合版的更新。
神经网络图: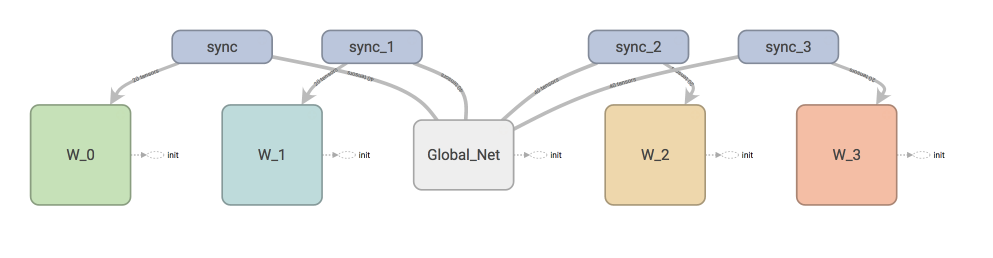
W_0 就是第0个 worker, 每个 worker 都可以分享 global_net
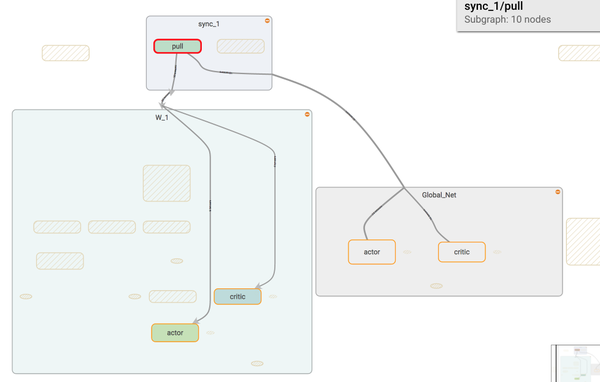
如果我们调用 sync 中的 pull, 这个 worker 就会从 global_net 中获取到最新的参数
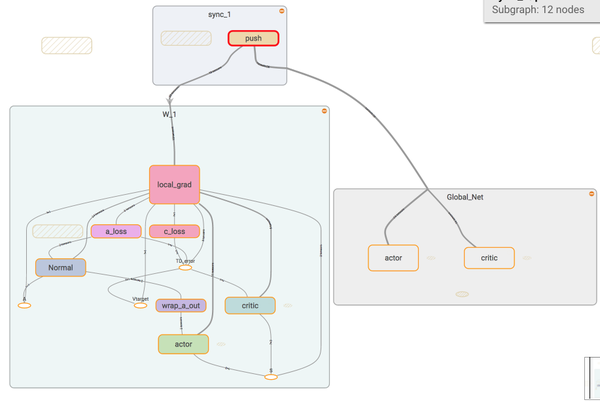
如果我们调用 sync 中的 push, 这个 worker 就会将自己的个人更新推送去 global_net。
主结构:
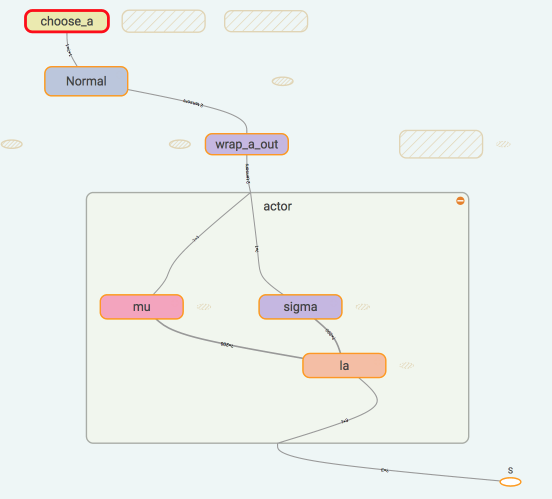
使用了 Normal distribution 来选择动作, 所以在搭建神经网络的时候, actor 这边要输出动作的均值和方差. 然后放入 Normal distribution 去选择动作. 计算 actor loss 的时候我们还需要使用到 critic 提供的 TD error 作为 gradient ascent 的导向。
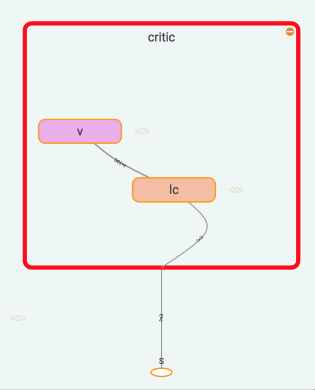
critic 只需要得到他对于 state 的价值就好了.,用于计算 TD error
Actor Critic 网络代码
import tensorflow as tf
import numpy as np
import gym
tf.compat.v1.disable_eager_execution()
import matplotlib.pyplot as plt
import threading
import multiprocessing
import os
import shutil
GAME = 'Pendulum-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 2000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.01
LR_A = 0.0001
LR_C = 0.001
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
# 这个 class 可以被调用生成一个 global net.
# 也能被调用生成一个 worker 的 net, 因为他们的结构是一样的,
# 所以这个 class 可以被重复利用.
class ACNet(object):
def __init__(self, scope, globalAC=None):
# 当创建 worker 网络的时候, 我们传入之前创建的 globalAC 给这个 worker
if scope == GLOBAL_NET_SCOPE:
with tf.compat.v1.variable_scope(scope):
self.s = tf.compat.v1.placeholder(tf.float32, [None, N_S], '5')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else:
#建立 local net
with tf.compat.v1.variable_scope(scope):
self.s = tf.compat.v1.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.compat.v1.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.compat.v1.placeholder(tf.float32, [None, 1],'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4 #二次分布
normal_dist = tf.compat.v1.distributions.Normal(mu, sigma) #标准正态分布
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td) #期望的动作值
entropy = normal_dist.entropy() #增加随机度
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'):
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0,1]), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_gard'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
# 接着计算 critic loss 和 actor loss
# 用这两个 loss 计算要推送的 gradients
with tf.name_scope('sync'): #同步
with tf.name_scope('pull'):
# 更新 global 参数
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
# 获取最新 global 参数
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
# 在这里搭建 Actor 和 Critic 的网络
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.compat.v1.variable_scope('actor'):
l_a = tf.compat.v1.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.compat.v1.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.compat.v1.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.compat.v1.variable_scope('critic'):
l_c = tf.compat.v1.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.compat.v1.layers.dense(l_c, 1, kernel_initializer=w_init, name='v')
a_params = tf.compat.v1.get_collection(tf.compat.v1.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.compat.v1.get_collection(tf.compat.v1.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
def update_global(self, feed_dict):
SESS.run([self.pull_a_params_op, self.pull_c_params_op],feed_dict)
def pull_global(self):
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s):
s = s[np.newaxis,:]
return SESS.run(self.A, {self.s : s})
Worker代码
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
# s, a, r 的缓存, 用于 n_steps 更新
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
for ep_t in range(MAX_EP_STEP):
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
done = True if ep_t == MAX_EP_STEP - 1 else False
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
# 每 UPDATE_GLOBAL_ITER 步 或者回合完了, 进行 sync 操作
if total_step % UPDATE_GLOBAL_ITER == 0 or done:
#计算TD_error 的下一 state的 value
if done:
v_s_ = 0
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s : s_[np.newaxis, :]})[0,0]
buffer_v_target = [] #下一state的value的缓存 用于计算TD
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s : buffer_s,
self.AC.a_his : buffer_a,
self.AC.v_target : buffer_v_target,
}
self.AC.update_global(feed_dict) #推送更新去globalAC
buffer_s, buffer_a, buffer_r = [], [], [] #清空缓存
self.AC.pull_global() #获取 globalAC的最新参数
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
运行主代码:
if __name__ == '__main__':
SESS = tf.compat.v1.Session()
with tf.device('/cpu:0'): #worker 并行工作 重点
OPT_A = tf.compat.v1.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.compat.v1.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) #只需要参数
workers = []
for i in range(N_WORKERS): # 创建 worker, 之后在并行
i_names = 'W_%i' % i
workers.append(Worker(i_names, GLOBAL_AC)) # 每个 worker 都有共享这个 global AC
COORD = tf.train.Coordinator() # Tensorflow 用于并行的工具
SESS.run(tf.compat.v1.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.compat.v1.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job) #添加一个工作线程
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.compat.v1.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job) #添加一个工作线程
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











