







提示:转载请注明出处,若文本无意侵犯到您的合法权益,请及时与作者联系。
莫烦Python代码实践(六)——Actor-Critic算法框架工程化解析
声明
本文是作者学习莫烦Python的代码笔记总结,如想深入可移步莫烦Python的该课程。
在之前我们已经介绍了以DQN系列为代表的Value-Based算法和REINFORCE为代表的Policy-Based算法,前者具有处理连续动作等不足,后者虽然可以处理连续动作但是最初的REINFORCE算法却是一个回合更新机制,学习效率太低,所以研究人员就考虑将两类算法优势互补,提出了Actor-Critic算法,与其说这是一种算法,不如说这是一种算法框架,因为目前实际应用最广泛的算法大都基于这种AC算法思想,所以本文之后将都直接称之为Actor-Critic框架。
一、Actor-Critic框架的特点
Actor-Critic框架是一种单步更新算法,其具备两个网络模型,分别是策略网络Actor和价值网络Critic,两个网络的特点如下:
| 网络类型 | 阶段 | 输入 | 输出 | 作用 |
| 策略网络Actor | 使用 | s | P(s,a) | 指导Agent选择动作 |
| 训练 | s,a,TD-Error | P(s,a) | ||
| 价值网络Critic | 使用 | s | V(s) | 评估Agent动作好坏 |
| 训练 | s,r,s_ | V(s),TD-Error |
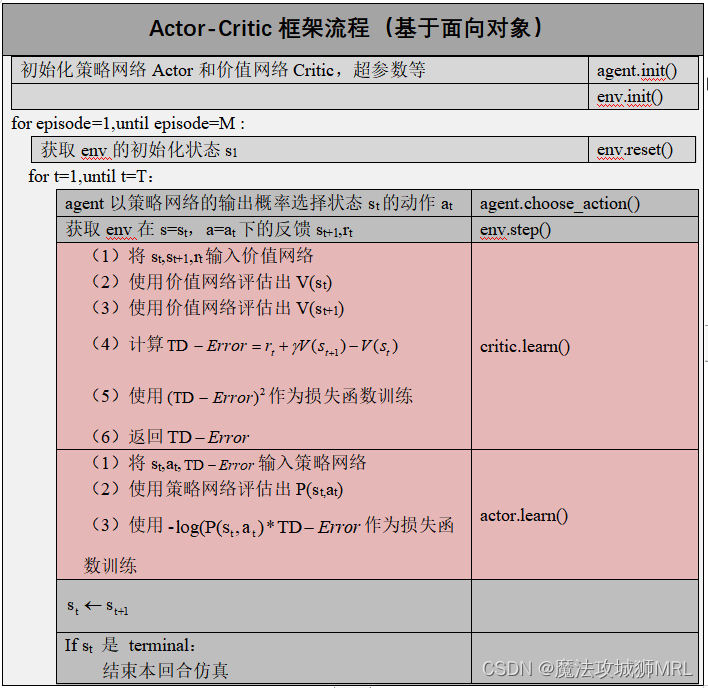
二、Actor-Critic框架流程
接下来我们直接给出基于面向对象的框架流程:
三、Actor-Critic框架代码实现
1、框架算法的整体训练流程
假设我们已经有Actor和Critic,首先初始化环境和Actor和Critic,然后开始训练:
# 创建环境
env = gym.make(TEST_ENV_NAME)
env.seed(1)
env = env.unwrapped
# 获取环境的状态空间和动作空间信息
N_F = env.observation_space.shape[0]
N_A = env.action_space.n
# 创建actor及critic
sess = tf.Session()
actor = Actor(sess,
n_features=N_F,
n_actions=N_A,
lr=LR_A)
critic = Critic(sess,
n_features=N_F,
lr=LR_C)
sess.run(tf.global_variables_initializer())
# 开始仿真训练
train(MAX_EPISODE,RENDER)
接下来看train方法的主要内容:
for i_episode in range(num_episode):
t_step = 0 # step计数器
s = env.reset() # 初始化环境状态
while True:
a = actor.choose_action(s) # 选择动作
s_, r, done, info = env.step(a)# 获取环境反馈
if done: r = -20 # 如果游戏失败,严厉惩罚
# 单步学习
td_error = critic.learn(s, r, s_)
actor.learn(s, a, td_error)
# 切换状态
s = s_
t_step += 1
# 如果游戏失败或者超过最大step数
if done or t_step >= MAX_EP_STEPS:
print("episode:", i_episode)
break
2、构建和运用策略网络Actor
我们的策略网络依旧使用两个最简单的全连接层,由于过于简单,不再讲解每行代码:
(1)定义网络的输入信息
self.s = tf.placeholder(tf.float32, [1, self.n_features], "state")
self.a = tf.placeholder(tf.int32, None, "act")
self.td_error = tf.placeholder(tf.float32, None, "td_error")
(2)定义网络的两个全连接层
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs=self.s,
units=20,
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=self.n_actions,
activation=tf.nn.softmax,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='acts_prob'
)
(3)定义网络的损失函数
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error)
(4)定义网络的优化器
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(-self.exp_v)
(5)定义网络的训练方法learn()
def learn(self, s, a, td):
s = s[np.newaxis, :] # 升维,从一维变为二维
# 训练网络
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
(6)定义网络的使用方法choose_action()
def choose_action(self, s):
s = s[np.newaxis, :] # 升维,从一维变为二维
# 运行网络,获取动作概率shape=(1,n_actions)
probs = self.sess.run(self.acts_prob, {self.s: s})
action = np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())
return action
3、构建和运用价值网络Critic
同样,我们的价值网络依旧使用两个最简单的全连接层,也不再讲解每行代码:
(1)定义网络的输入信息
self.s = tf.placeholder(tf.float32, [1, self.n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
self.r = tf.placeholder(tf.float32, None, 'r')
(2)定义网络的两个全连接层
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=20,
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1,
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1),
bias_initializer=tf.constant_initializer(0.1),
name='V'
)
(3)定义网络的损失函数
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + self.gamma * self.v_ - self.v
self.loss = tf.square(self.td_error)
(4)定义网络的优化器
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss)
(5)定义网络的训练方法learn()
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_}) # 用自身策略网络来估计v_
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
















 5893
5893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











