







本章将采用两个不同的数据集评测基于标签的物品推荐算法。一个是Delicious数据集,另一个是CiteULike数据集。Delicious数据集中包含用户对网页的标签记录。它每一行由4部分组成,即时间、用户ID、网页URL、标签。本章只抽取了其中用户对一些著名博客网站网页(Wordpress、BlogSpot、TechCrunch)的标签记录。CiteULike数据集包含用户对论文的标签记录,它每行也由4部分组成,即物品ID、用户ID、时间、标签,本章选取了其中稠密的部分。
基础算法
拿到了用户标签行为数据,一个最简单的个性化推荐算法如下所示:统计每个用户最常用的标签;对于每个标签,统计被打过这个标签次数最多的物品;对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
对于上面的算法,用户u对物品i的兴趣公式如下:其中B(u)是用户u打过的标签集合,B(i)是物品i被打过的标签集合,n(u,b)是用户u打过标签b的次数,n(b,i)是物品i被打过标签b的次数。我们用SimpleTagBased标记这个算法。
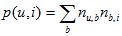
在Python中,用 records 存储标签数据的三元组,其中records[i] = [user, item, tag];用 user_tags 存储n(u,b),其中user_tags[u][b] = n(u,b); 用 tag_items存储n(b,i),其中tag_items[b][i] = n(b,i)。如下程序可以从records中统计出user_tags和tag_items:
def InitStat(records):
user_tags = dict()
tag_items = dict()
user_items = dict()
for user, item, tag in records.items():
addValueToMat(user_tags, user, tag, 1)
addValueToMat(tag_items, tag, item, 1)
addValueToMat(user_items, user, item, 1)统计出user_tags和tag_items之后,我们可以通过如下程序对用户进行个性化推荐:
def Recommend(user):
recommend_items = dict()
tagged_items = user_items[user]
for tag, wut in user_tags[user].items():
for item, wti in tag_items[tag].items():
#if items have been tagged, do not recommend them
if item in tagged_items:
continue
if item not in recommend_items:
recommend_items[item] = wut * wti
else:
recommend_items[item] += wut * wti
return recommend_items算法的改进
1. TF-IDF
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给用户,从而降低推荐结果的新颖性。另外,这个公式利用用户的标签向量对用户兴趣建模,其中每个标签都是用户使用过的标签,而标签的权重是用户使用该标签的次数。这种建模方法的缺点是给热门标签过大的权重,从而不能反应用户个性化的兴趣。这里我们可以借鉴TF-IDF的思想,
对这一公式进行改进,这里, n(b,(u)) 记录了标签b被多少个不同的用户使用过。这个算法记为TagBasedTFIDF。
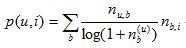
同理,我们也可以借鉴TF-IDF的思想对热门物品进行惩罚,从而得到如下公式,其中,n(i,(u))记录了物品i被多少个不同的用户打过标签。这个算法记为TagBasedTFIDF++。
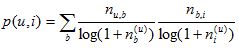
通过比较实验结果,可以看出适当惩罚热门标签和热门物品,在增进推荐结果个性化的同时并不会降低推荐结果的离线精度。
2. 数据稀疏性
在前面的算法中,用户兴趣和物品的联系是通过B(u)交B(i)集合中的标签建立的。但是,对于新用户或者新物品,这个集合(B(u)交B(i))中的标签数量会很少。为了提高推荐的准确率,我们可能要对标签集合做扩展,标签扩展的本质是对每个标签找到和它相似的标签,也就是计算标签之间的相似度。
如果认为同一个物品上的不同标签具有某种相似度,那么当两个标签同时出现在很多物品的标签集合中时,我们就可以认为这两个标签具有较大的相似度。对于标签b,令N(b)为有标签b的物品的集合,n_{b,i}为给物品i打上标签b的用户数,我们可以通过如下余弦相似度公式计算标签b和标签b'的相似度:
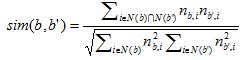
3. 标签清理
不是所有标签都能反应用户的兴趣。比如,在一个视频网站中,用户可能对一个视频打了一个表示情绪的标签,比如“不好笑”,但我们不能因此认为用户对“不好笑”有兴趣,并且给用户推荐其他具有“不好笑”这个标签的视频。相反,如果用户对视频打过“成龙”这个标签,我们可以据此认为用户对成龙的电影感兴趣,从而给用户推荐成龙其他的电影。同时,标签系统里经常出现词形不同、词义相同的标签,比如recommender system和recommendation engine就是两个同义词。
标签清理的另一个重要意义在于将标签作为推荐解释。如果我们要把标签呈现给用户,将其作为给用户推荐某一个物品的解释,对标签的质量要求就很高。首先,这些标签不能包含没有意义的停止词或者表示情绪的词,其次这些推荐解释里不能包含很多意义相同的词语。
一般来说有如下标签清理方法:去除词频很高的停止词;去除因词根不同造成的同义词,比如 recommender system和recommendation system;去除因分隔符造成的同义词,比如 collaborative_filtering和collaborative-filtering。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









