







LFM(latent factor model)隐语义模型的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品,采取基于用户行为统计的自动聚类。
隐含语义分析技术的分类来自对用户行为的统计,代表了用户对物品分类的看法。隐含语义分析技术和ItemCF在物品分类方面的思想类似,如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。
隐含语义分析技术允许我们指定最终有多少个分类,这个数字越大,分类的粒度就会越细,反正分类粒度就越粗。
隐含语义分析技术会计算出物品属于每个类的权重,因此每个物品都不是硬性地被分到某一个类中。
隐含语义分析技术给出的每个分类都不是同一个维度的,它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给出的类也是相同的维度。
隐含语义分析技术可以通过统计用户行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个
物品在这个类中的权重就可能比较高。
LFM通过如下公式计算用户u对物品i的兴趣:
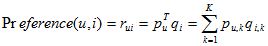
这个公式中p(u,k)和q(i,k)是模型的参数,其中p(u,k)度量了用户u的兴趣和第k个隐类的关系,而q(i,k)度量了第k个隐类和物品i之间的关系。这两个参数是从数据集中计算出来的。要计算这两个参数,需要一个训练集,对于每个用户u,训练集里都包含了用户u喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模型参数。推荐系统的用户行为分为显性反馈和隐性反馈。LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。不过这里主要讨论的是隐性反馈数据集,这种数据集的特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。对负样本采样时应该遵循以下原则:
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
下面的Python代码实现了负样本采样过程:
def RandomSelectNegativeSample(self, items):
ret = dict()
for i in items.keys():
ret[i] = 1
n = 0
for i in range(0, len(items) * 3):
item = items_pool[random.randint(0, len(items_pool) - 1)]
if item in ret:
continue
ret[item] = 0
n + = 1
if n > len(items):
break
return ret
items_pool维护了候选物品的列表,在这个列表中,物品i出现的次数和物品i的流行度成正比。items是一个dict,它维护了用户已经有过行为的物品的集合。因此,上面的代码按照物品的流行度采样出了那些热门的、但用户却没有过行为的物品。经过采样,可以得到一个用户—物品集K= {(u,i)},其中如果(u, i)是正样本,则有r(ui)=1,否则有r(ui)=0 ,r(ui,hat)是推荐系统给出的用户u对物品i的兴趣。然后。需要优化如下的损失函数来找到最合适的参数p和q:
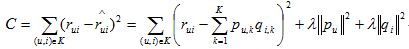
这里,||pu||和||qi||是用来防止过拟合的正则化项,λ可以通过实验获得。要最小化上面的损失函数,可以利用随机梯度下降法算法。
随机梯度下降法需要首先对它们分别求偏导数,可以得到:

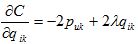
然后,根据随机梯度下降法,需要将参数沿着最速下降方向向前推进,因此可以得到如下递推公式,其中a是学习率。
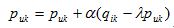
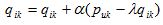
def LatentFactorModel(user_items, F, N, alpha, lambda):
[P, Q] = InitModel(user_items, F)
for step in range(0,N):
for user, items in user_items.items():
samples = RandSelectNegativeSamples(items)
for item, rui in samples.items():
eui = rui - Predict(user, item)
for f in range(0, F):
P[user][f] += alpha * (eui * Q[item][f] - lambda * P[user][f])
Q[item][f] += alpha * (eui * P[user][f] - lambda * Q[item][f])
alpha *= 0.9
def Recommend(user, P, Q):
rank = dict()
for f, puf in P[user].items():
for i, qfi in Q[f].items():
if i not in rank:
rank[i] += puf * qfi
return rank综上在LFM中,重要的参数有4个:隐特征的个数F;学习速率alpha;正则化参数lambda;负样本/正样本比例 ratio。通过实验发现,ratio参数对LFM的性能影响最大。














 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









