






目录
一、介绍
搭建自己的神经网络涉及几个关键步骤,包括定义网络结构、准备数据、训练网络以及测试网络性能。以下是基于我的个人习惯进行的网络设置和数据准备。里面一些相关的其他概念会有所涉及。本文不讨论前期基础的环境设置以及理论性的知识,值在于实践。这是我在做的一个项目的视觉分支,记录一下以免以后忘记。本文使用的是pytorch。
(此段内容可以忽略) 最开始是打算使用C++的torchscript结合python的pytorch进行的,后续发现在C++上部署比较麻烦(个人比较懒),因此暂时没有在C++上进行深入。项目的目的是设计新的足球机器人视觉系统。我们采用的是全景相机+kinect,沿用之前的视觉,在此基础上打算融入深度学习进行障碍物跟踪。考虑过使用多相机进行视觉融合,但是这样就失去了在近处的视野。综合实际的应用,打算保留全景。
二、搭建网络
1. 使用 nn.Sequential
对于相对简单的网络,可以使用 torch.nn.Sequential 来快速定义一个连续的层序列。这种方法简洁明了,非常适合没有复杂分支或自定义操作的网络。
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
2*. 继承 nn.Module
对于更复杂的网络,或者当需要更多的自定义行为时,可以通过继承 nn.Module 并定义 forward 方法来创建自己的模型。这种方法提供了更多的灵活性。
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * (128//8) * (128//8), 64),
nn.ReLU(),
nn.Linear(64, 4),
nn.ReLU() # 确保输出为非负数
)
def forward(self,x):
# for layer in self.model:
# x = layer(x)
# print(x)
x = self.model(x)
return x2.1 CNN 类定义
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
这段代码定义了一个名为 CNN 的类,该类继承自 nn.Module,这是所有神经网络模型的基类。在 __init__ 方法中,通过调用 super().__init__() 初始化基类。
2.2 网络层定义
接下来,网络层在 nn.Sequential 中定义。nn.Sequential 是一个特殊的模块,它按照它们添加的顺序执行包含的子模块。
1. nn.Conv2d(3, 32, 5, 1, 2): 2D 卷积层。参数意义如下:
- 输入通道数:3(假设输入是RGB图像)
- 输出通道数:32
- 卷积核大小:5x5
- 步长(stride):1
- 填充(padding):2
2. nn.BatchNorm2d(32): 2D 批量归一化层。参数为特征数量,这里是32
3. nn.ReLU(): 激活函数,使用 ReLU
4.nn.MaxPool2d(2): 最大池化层,使用2x2窗口
以上模式重复三次,每次都有卷积层、批量归一化、ReLU激活和最大池化。卷积层的输出通道数和卷积核数量从32增加到64。
5. nn.Flatten(): 展平层,将多维输入一维化,用于准备连接全连接层
6. nn.Linear(64 * (128//8) * (128//8), 64): 全连接层。参数为:
- 输入特征数:根据前面层的输出计算得出
- 输出特征数:64
7. 第二个 nn.Linear(64, 4): 另一个全连接层,将64维特征映射到4维输出。
2.3 参数设置
在代码中,使用了 64 * (128//8) * (128//8) 来计算这个数值,这里 (128//8) 实际上是对 16 的计算,因为 128 / 2 / 2 / 2 = 16。这就是全连接层的输入特征数。
因此,nn.Linear(64 * (128//8) * (128//8), 64) 的意思是:将经过卷积和池化层处理后得到的 16384(即 64 * 16 * 16)个特征作为输入,映射到64个输出特征上。
2.3.1 计算公式
但是,不同的池化层设置也会导致不同的计算,这里无法举例所有的参数,下面给出计算公式:
- 卷积层和全连接层的参数需要根据具体任务和输入数据的形状来调整。例如,卷积层的输出通道数(32, 64等)和全连接层的输入/输出特征数。
- 最大池化层的窗口大小(
nn.MaxPool2d(2))通常设置为2或3,这取决于希望减少多少特征维度。 - 最后一个全连接层的输出特征数(在这里是4)应该匹配任务需求,例如分类任务中的类别数。
- **全连接层nn.Linear()中输入特征数的计算和设置:输入特征数是根据前一个卷积层或池化层的输出特征图的尺寸计算出来的。这个计算需要考虑到输入图像经过每个卷积层和池化层后尺寸的变化。
假设原始输入图像的尺寸是(高度, 宽度) = (128, 128),并且经过了多个层(卷积层和池化层),其中每个池化层都将特征图的高度和宽度减半(假设池化层是nn.MaxPool2d(2),即使用 2x2 的窗口)。在上述的网络结构中,有三个这样的池化层。
原理解释: - 卷积层:在上述模型中,最后一个卷积层的输出通道数是 64。因此,该层每个特征图的深度为 64。
- 池化层:每经过一个
nn.MaxPool2d(2)池化层,特征图的高度和宽度都会减半。
计算: - 输入图像的尺寸是
(128, 128)。 - 经过三次池化,尺寸变为
128 / 2 / 2 / 2 = 16(高度和宽度都是这样计算)。 - 因此,经过最后一个卷积层和池化层后,特征图的尺寸是
(64, 16, 16)(64 是深度,16x16 是空间维度)。 - 当这个特征图被展平(Flatten)后,总的特征数量是
64 * 16 * 16。
1. 卷积层输出尺寸公式
对于卷积层,输出尺寸(宽度和高度)可以使用以下公式计算:

其中:
- 输入尺寸:输入特征图的宽度或高度。
- 核大小:卷积核的宽度或高度。
- 步长:卷积时的步长。
- 填充:在输入特征图边缘添加的零的层数。
2. 池化层输出尺寸公式
池化层(如最大池化、平均池化)的输出尺寸也可以使用类似的公式计算:

池化层的参数与卷积层类似,但通常没有填充(或很少使用填充)。
3. 全连接层输入特征数公式
在神经网络中,nn.Linear 层(也称为全连接层或密集层)的输入特征数取决于前一层的输出。在典型的卷积神经网络中,当将一个多维特征图(例如,来自卷积层或池化层的输出)传递到一个全连接层时,这个特征图首先需要被展平(Flatten)成一个一维向量。nn.Linear 层的输入特征数就是这个一维向量的长度。
如果前一层是一个卷积层或池化层,可以使用以下公式来计算 nn.Linear 层的输入特征数:

- 特征图深度:前一层输出的通道数(即卷积层或池化层输出的深度)。
- 特征图高度和宽度:使用上面提供的公式计算得出的特征图的尺寸。
2.4 向前传播定义
def forward(self, x):
x = self.model(x)
return x
在 forward 方法中定义了数据如何通过网络流动。x = self.model(x) 语句使得输入数据 x 通过之前定义的 nn.Sequential 中的所有层。这是模型的前向传播过程。
3. 使用预训练模型
使用预训练的模型,如 ResNet,是深度学习中的一种常见做法,尤其是在计算机视觉领域。预训练模型是指已经在大型数据集(如 ImageNet)上训练过的模型,能够作为一个很好的特征提取器或作为新任务的起点。PyTorch 提供了方便的接口来下载和使用这些预训练模型,即在torchvision.models中。
import torch
from torchvision import models
# 定义一个继承自torch.nn.Module的自定义类
class CustomResNet50(torch.nn.Module):
def __init__(self):
# 调用父类的构造函数
super(CustomResNet50, self).__init__()
# 加载预训练的ResNet-50模型
# 注意:这里pretrained设置为False,表示不使用预训练的权重
self.base_model = models.resnet50(pretrained=False)
# 获取ResNet-50最后一个全连接层的输入特征数量
num_features = self.base_model.fc.in_features
# 替换ResNet-50的最后一个全连接层
# 新的全连接层的输出特征数设置为4(可根据具体任务调整)
self.base_model.fc = torch.nn.Linear(num_features, 4)
# 定义前向传播过程
def forward(self, x):
# 将输入数据x传递给模型
return self.base_model(x)
在这个类中:
1. __init__ 方法初始化了模型。首先加载了一个不带预训练权重的 ResNet-50 模型。
2. 通过 self.base_model.fc.in_features 获取了 ResNet-50 模型中最后一个全连接层的输入特征数量。
3. 替换了原始 ResNet-50 模型中的最后一个全连接层(fc),将输出特征数量设置为 4。这对于适应不同于原始模型(通常是1000个类别的ImageNet分类)的任务是必要的。
4. 在 forward 方法中定义了数据的前向传播过程。这里,数据 x 通过 self.base_model,即自定义后的 ResNet-50 模型进行前向传播。
5. 自定义模型的方式在迁移学习中非常常见,特别是当想利用已有的架构,如ResNet,但需要针对新的特定任务(例如,分类任务中类别数不同于原始任务)进行调整时。
三、准备数据
一下是进行图片处理的个人习惯。使用到了pytorch提供的DataLoader, Dataset, transform, random_split 等。
import torch
import pandas as pd
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from torchvision import transforms
from torch.utils.data import random_split as rsplit
#图像预处理器
transform = transforms.Compose([
transforms.Resize((128,128)), #图片大小的设置
transforms.ToTensor(), #转化为tensor格式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
#创建数据集
class SoccerDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir #存放图片路径的csv文件的路径
self.dataframe = pd.read_csv(self.data_dir, header=None) #读取csv文件
self.transform = transform #获得数据处理器
def __len__(self):
return len(self.dataframe) - 1 #获得数据的长度
def __getitem__(self, idx):
img_path = self.dataframe.iloc[idx+1,0] #得到图片路径
image = Image.open(img_path).convert('RGB') #以RGB格式读取图片
#一下都是其余数据的处理
parameter = []
parameter1 = float(self.dataframe.iloc[idx+1, 1])
parameter2 = float(self.dataframe.iloc[idx+1, 2])
parameter3 = float(self.dataframe.iloc[idx+1, 3])
parameter4 = float(self.dataframe.iloc[idx+1, 4])
torch.tensor(parameter1)
torch.tensor(parameter2)
torch.tensor(parameter3)
torch.tensor(parameter4)
parameter.append(parameter1)
parameter.append(parameter2)
parameter.append(parameter3)
parameter.append(parameter4)
# print("parameter:", parameter)
parameter = torch.tensor(parameter, dtype=torch.float32)
# print(parameter)
if self.transform:
image = self.transform(image)
return image, parameter #返回图片以及对应的参数,即一个“图片-需要电脑知道的数据”对
data_path = 'soccer_data.csv' #存放图片路径的csv文件的路径
soccer = SoccerDataset(data_path, transform) #创建数据
#划分数据集
soccer_train_size = int(0.8* len(soccer)) #训练数据集的大小 0。8权重
soccer_test_size = len(soccer) - soccer_train_size #测试数据集的大小
#分割数据集
soccer_train, soccer_test = rsplit(soccer,[soccer_train_size,soccer_test_size])
#按照16(batch_size = 16)个数据为一组加载数据集
train_loader = DataLoader(soccer_train,batch_size=16,shuffle=True)
test_loader = DataLoader(soccer_test,batch_size=16,shuffle=True)这里面提到的csv文件是我的习惯,我一般将图片集的路径存放在一个csv文件中,对应的是这个图片中的一些需要去训练的参数。可以把图片作为输入量x,而其余的参数作为输出量y。使用神经网络进行万能函数拟合得到一个 y = f(x) 的映射,当你使用这个网络,即输入 x 后, 网络会根据这个映射输出 y。

这个是csv文件的预览图,其中的格式如图。image是图片路径,parameter1-4是我需要给网络学习的参数。
这里同样给出我处理图片数据的代码,但是不做过多的解释:
import os
import pandas as pd
image_list = []
label_list = []
def getPicturePath(path):
# path为指定的路径
# 返回指定路径的文件夹名称
dirs = os.listdir(path)
# 循环遍历目录下的照片
for dir in dirs:
image_path = os.path.join(path, dir)
image_list.append(image_path)
def CreateData(path):
getPicturePath(path)
length = len(image_list)
parameter1 = []
parameter2 = []
parameter3 = []
parameter4 = []
for i in range(length):
img_path = image_list[i]
label_path = img_path.replace('jpg', 'txt')
label_path = label_path.replace('images', 'labels') #得到label的地址
label_txt = pd.read_csv(label_path, header=None)
label_txt = label_txt.iloc[0, 0]
label_list = label_txt.split()
label = []
for i in label_list:
if i is '0':
continue
else:
label.append(float(i))
print(label)
parameter1.append(label[0])
parameter2.append(label[1])
parameter3.append(label[2])
parameter4.append(label[3])
# print(parameter1)
df = pd.DataFrame({'image': image_list, 'parameter1': parameter1, 'parameter2': parameter2, 'parameter3': parameter3,
'parameter4': parameter4})
df = df.reset_index(drop=True)
df.to_csv('soccer_data.csv', index=False)
print(df)
print("数据文件已创建")
if __name__ == '__main__':
CreateData("../data/images")
四、训练神经网络
这里我习惯把训练,验证以及保存网络放在一起进行。
#加载模型
model = CNN()
#损失函数
# criterion = nn.CrossEntropyLoss()
criterion = torch.nn.MSELoss()
#优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
#循环次数
epochs = 20
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
for i in range(epochs):
print(f"第 {i + 1} 轮训练开始")
model.train() #设置为训练模式
for step in range(epochs):
for inputs, labels in train_loader:
#这里没有使用gpu训练是因为我当前电脑没有gpu(苦笑)
# inputs = inputs.float().cuda()
# labels = labels.float().cuda()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 梯度清零
optimizer.zero_grad()
# 反向传播和优化
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
# 只有当训练到整百数的时候才输出,减少输出的次数
if total_train_step % 100 == 0:
print(f"训练次数: {total_train_step}, loss: {loss}")
# 测试步骤开始
model.eval() #设置为评估模式
total_test_loss = 0
total_accuracy = 0
total_mse = 0
total_mae = 0
num_samples = 0
with torch.no_grad(): # 没训练完成一次进行一次测试,这个代码是防止对模型参数进行改动
for data in test_loader:
imgs, targets = data
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = model(imgs)
loss = criterion(outputs, targets)
total_test_loss = total_test_loss + loss.item()
mse = torch.mean((outputs - targets) ** 2)
mae = torch.mean(torch.abs(outputs - targets))
total_mse += mse.item()
total_mae += mae.item()
num_samples += targets.size(0)
print(f"整体测试集上的loss: {total_test_loss}")
print(f"平均均方误差 (MSE): {total_mse / num_samples}",end=" ")
print(f"平均绝对误差 (MAE): {total_mae / num_samples}")
total_train_step = total_train_step + 1
torch.save(model, f"soccer_cpu_cnn.pth")
print("模型已经保存")五、使用模型
from torchvision import transforms
import torch
from PIL import Image
import cv2
# 图像预处理
#对于输入的图片,要保持和训练时图片相同的形式
transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
model = torch.load('soccer_cpu_cnn.pth')
model = model.eval() # 设置为评估模式
# 加载图像并进行预处理
img_path = 'save_img\\22.jpg' #图片存放的路径
image = Image.open(img_path).convert('RGB')
image = transform(image) # 应用与训练相同的转换
image = image.unsqueeze(0) # 添加一个批次维度,读取的图片是三维的,而要求输入的是四维
with torch.no_grad(): # 关闭梯度计算
output = model(image) #输出的结果
#对输出结果的处理,可以忽略
predicted_values = output.cpu().numpy() # 将Tensor转换为numpy数组
predicted_values = [item for sublist in predicted_values for item in sublist]项目总体代码
本项目模块只是一个小的视觉分支,是我进行的一个尝试。使用了labelimg对图片进行的标注,对图片和4个标注信息(也就是上面提到的parameter1-4)进行训练。实现对足球的识别和跟踪。
1.网络 Module.py
import torch
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * (128//8) * (128//8), 64),
nn.ReLU(),
nn.Linear(64, 4),
nn.ReLU() # 确保输出为非负数
)
def forward(self,x):
# for layer in self.model:
# x = layer(x)
# print(x)
x = self.model(x)
return x2. CSV创建 dataset.py
import os
import pandas as pd
image_list = []
label_list = []
def getPicturePath(path):
# path为指定的路径
# 返回指定路径的文件夹名称
dirs = os.listdir(path)
# 循环遍历目录下的照片
for dir in dirs:
image_path = os.path.join(path, dir)
image_list.append(image_path)
def CreateData(path):
getPicturePath(path)
length = len(image_list)
parameter1 = []
parameter2 = []
parameter3 = []
parameter4 = []
for i in range(length):
img_path = image_list[i]
label_path = img_path.replace('jpg', 'txt')
label_path = label_path.replace('images', 'labels') #得到label的地址
label_txt = pd.read_csv(label_path, header=None)
label_txt = label_txt.iloc[0, 0]
label_list = label_txt.split()
label = []
for i in label_list:
if i is '0':
continue
else:
label.append(float(i))
print(label)
parameter1.append(label[0])
parameter2.append(label[1])
parameter3.append(label[2])
parameter4.append(label[3])
# print(parameter1)
df = pd.DataFrame({'image': image_list, 'parameter1': parameter1, 'parameter2': parameter2, 'parameter3': parameter3,
'parameter4': parameter4})
df = df.reset_index(drop=True)
df.to_csv('soccer_data.csv', index=False)
print(df)
print("数据文件已创建")
if __name__ == '__main__':
CreateData("../data/images")
3. 模型训练 train_cpu.py
我这里使用的是resnet50预训练模型,应为我的足球图片数据比较少
import torch
import pandas as pd
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from torchvision import transforms, models
import numpy as np
import os
from dataset import CreateData
from torch.utils.data import random_split as rsplit
import cv2
#图像预处理
transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
#创建数据集
class SoccerDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.dataframe = pd.read_csv(self.data_dir, header=None)
self.transform = transform
def __len__(self):
# print(len(self.dataframe))
return len(self.dataframe) - 1
def __getitem__(self, idx):
# print(self.dataframe)
img_path = self.dataframe.iloc[idx+1,0] #得到图片路径
# print("img_path:",img_path)
# print("dataframe", self.dataframe)
# print(img_path)
# print("label_path:", label_path) #测试标签路径
image = Image.open(img_path).convert('RGB')
# print("label_txt: ", label_txt)
parameter = []
# print("parameter:", parameter)
parameter1 = float(self.dataframe.iloc[idx+1, 1])
parameter2 = float(self.dataframe.iloc[idx+1, 2])
parameter3 = float(self.dataframe.iloc[idx+1, 3])
parameter4 = float(self.dataframe.iloc[idx+1, 4])
# print("type of parameter1: ",type(parameter1))
torch.tensor(parameter1)
torch.tensor(parameter2)
torch.tensor(parameter3)
torch.tensor(parameter4)
parameter.append(parameter1)
parameter.append(parameter2)
parameter.append(parameter3)
parameter.append(parameter4)
# print("parameter:", parameter)
parameter = torch.tensor(parameter, dtype=torch.float32)
# print(parameter)
if self.transform:
image = self.transform(image)
return image, parameter
data_path = 'soccer_data.csv'
soccer = SoccerDataset(data_path, transform)
#划分数据集
soccer_train_size = int(0.8* len(soccer))
soccer_test_size = len(soccer) - soccer_train_size
soccer_train, soccer_test = rsplit(soccer,[soccer_train_size,soccer_test_size])
train_loader = DataLoader(soccer_train,batch_size=16,shuffle=True)
test_loader = DataLoader(soccer_test,batch_size=16,shuffle=True)
#加载预训练模型
model = models.resnet50(pretrained=True)
# 冻结模型的所有参数
for param in model.parameters():
param.requires_grad = False
# 替换模型的最后一层(全连接层)以适应新的分类任务
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, 4) #输出一个新的列表
#损失函数
# criterion = nn.CrossEntropyLoss()
criterion = torch.nn.MSELoss()
#优化器
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
# if torch.cuda.is_available():
# print("GPU可以使用")
# model = model.cuda()
# else:
# print("GPU不可使用")
# quit()
epochs = 20
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
for i in range(epochs):
print(f"第 {i + 1} 轮训练开始")
model.train()
for step in range(epochs):
for inputs, labels in train_loader:
# inputs = inputs.float().cuda()
# labels = labels.float().cuda()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 梯度清零
optimizer.zero_grad()
# 反向传播和优化
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
# 只有当训练到整百数的时候才输出,减少输出的次数
if total_train_step % 100 == 0:
print(f"训练次数: {total_train_step}, loss: {loss}")
# 测试步骤开始
model.eval()
total_test_loss = 0
total_accuracy = 0
total_mse = 0
total_mae = 0
num_samples = 0
with torch.no_grad(): # 没训练完成一次进行一次测试,这个代码是防止对模型参数进行改动
for data in test_loader:
imgs, targets = data
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = model(imgs)
loss = criterion(outputs, targets)
total_test_loss = total_test_loss + loss.item()
mse = torch.mean((outputs - targets) ** 2)
mae = torch.mean(torch.abs(outputs - targets))
total_mse += mse.item()
total_mae += mae.item()
num_samples += targets.size(0)
print(f"整体测试集上的loss: {total_test_loss}")
print(f"平均均方误差 (MSE): {total_mse / num_samples}",end=" ")
print(f"平均绝对误差 (MAE): {total_mae / num_samples}")
total_train_step = total_train_step + 1
torch.save(model, f"soccer_cpu_rest50.pth")
print("模型已经保存")
4. 进行预测 predict.py
from torchvision import transforms
import torch
from PIL import Image
import cv2
# 图像预处理
#对于输入的图片,要保持和训练时图片相同的形式
transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
model = torch.load('soccer_cpu_cnn.pth')
model = model.eval() # 设置为评估模式
# 加载图像并进行预处理
img_path = 'test1.jpg' #图片存放的路径
image = Image.open(img_path).convert('RGB')
image = transform(image) # 应用与训练相同的转换
image = image.unsqueeze(0) # 添加一个批次维度,读取的图片是三维的,而要求输入的是四维
with torch.no_grad(): # 关闭梯度计算
output = model(image)
predicted_values = output.cpu().numpy() # 将Tensor转换为numpy数组
predicted_values = [item for sublist in predicted_values for item in sublist]
img = cv2.imread(img_path)
if img is None:
print("[Error]: 图片无法加载")
exit()
else:
resized_img = cv2.imread(img_path)
x, y, width, height = predicted_values[0], predicted_values[1], predicted_values[2], predicted_values[3]
img_height, img_width = img.shape[:2]
# img_height = 1280 #1280
# img_width = 1706 #1706
print("img_width:", img_width, end=" ")
print("img_height:", img_height, end=" ")
#这里需要注意的是,labelimg标注的yolo中的x和y是中心点的坐标,因此这里需要进行坐标的转换
width = int(img_width * width)
height = int(img_height * height)
x = int( img_width * x - width/2)
y = int(img_height * y - height/2)
print("Predicted values:", predicted_values)
# 绘制矩形
# 这里 (0, 255, 0) 定义了矩形的颜色(绿色),2 是矩形边框的厚度
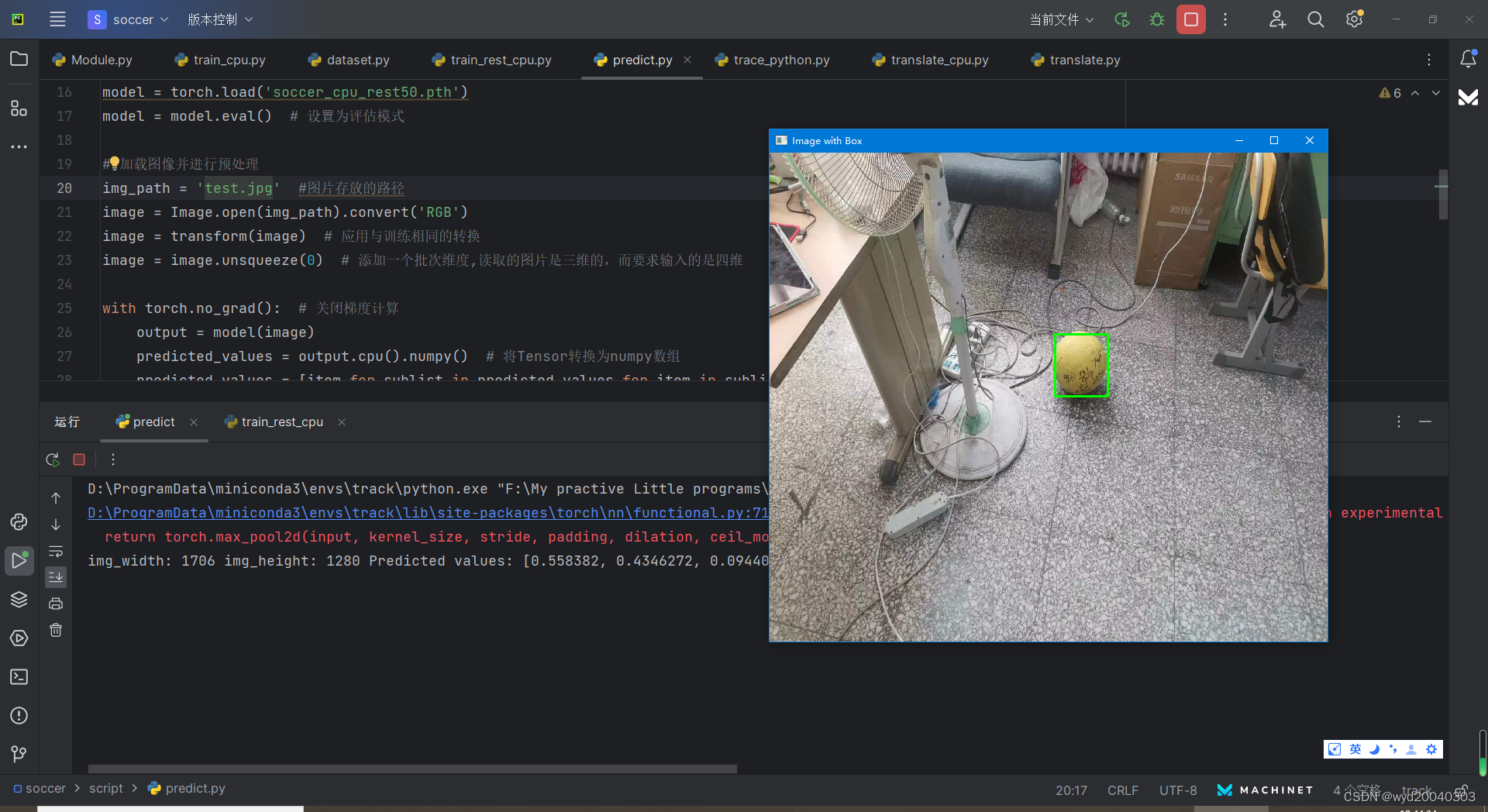
cv2.rectangle(resized_img, (x, y), (x + width, y + height), (0, 255, 0), 5)
cv2.namedWindow('Image with Box', cv2.WINDOW_NORMAL)
cv2.imshow('Image with Box', resized_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
5. 预测结果展示















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









