







residual/ResNet
众所周知,网络的性能与深度息息相关。如果在一个浅层网络A上叠加几层layer形成网络B,如果这些新添加的layer是Identity mapping(权值矩阵全是单位矩阵?),那么网络B性能至少不会比A差。但是实际实验结果却显示网络越深,性能越差,所以作者猜测solver 对于学习单位映射比较困难。既然学习单位映射比较麻烦,那干脆直接给它加上一个shortcut,直接给这个模块输出叠加上输入。实际情况中,单位映射x并不是最优解H(x),最优解在单位映射附近,这个最优解与单位映射之间的差就叫做residual F(x)。
两个relu之间的+就是residual connection了
注:实际运用中,DRN中的shortcut有些是带有参数的,因为有的模块有降维操作,输入输出的维度不一样用bn,不用dropout。
ResNet并不是第一个利用近路连接,Highway Networks引入门控近路连接的。ResNet可以被认为是Highway Networks的一种特殊情况,且性能更好。
各种变种
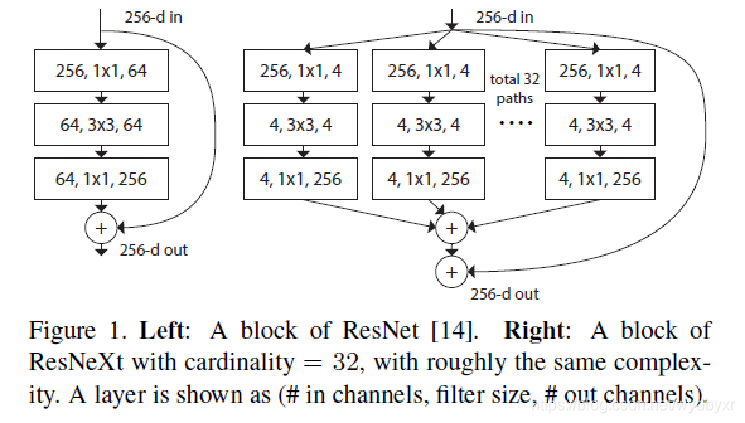
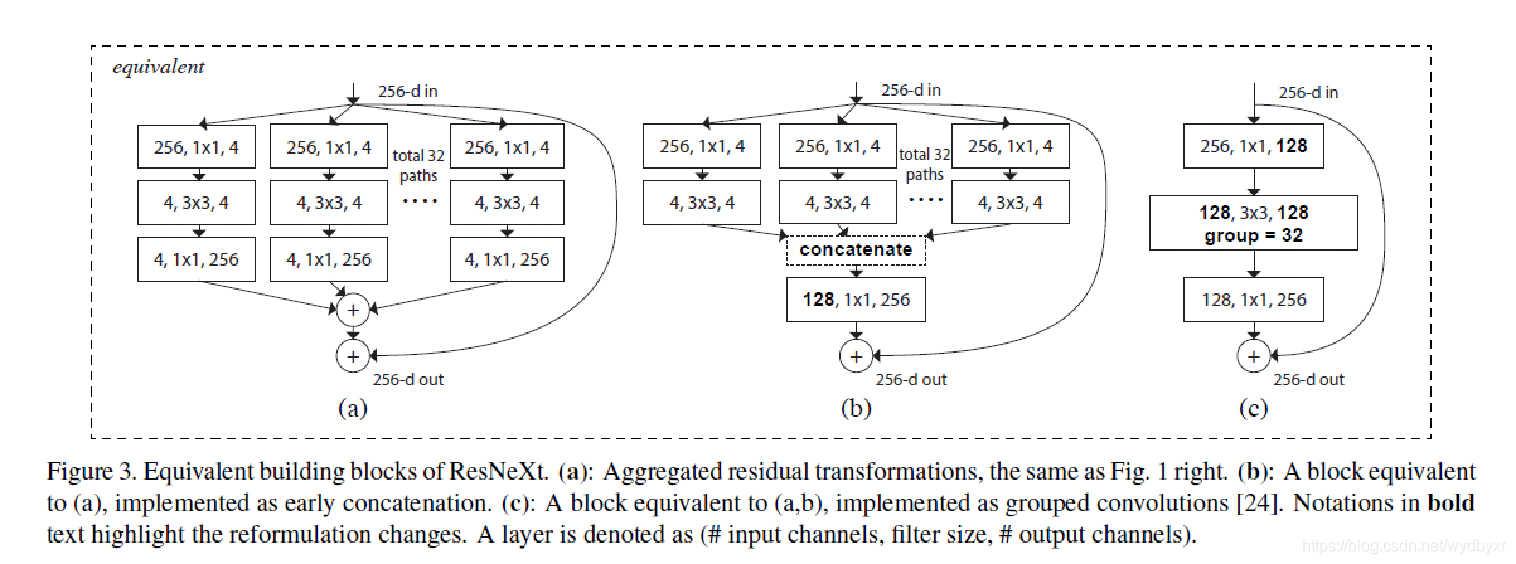
1)ResNeXt
它非常类似于Inception模块,两者都遵循“拆分-转换-合并”范式。但较于inception的优势是提出了“基数(cardinality)”的超参数——独立路径的数量,以提供调整模型容量的新方式。
实验表明,可以通过增加基数,而不是深度或宽度,来更加有效地获得准确度。作者指出,与Inception相比,这种新颖的架构更容易适应新的数据集/任务,因为它具有一个简单的范式,且只有一个超参数被调整,而Inception却具有许多超参数(如每个路径中卷积层内核大小)待调整。
2)DenseNet
在这种结构中,每层的输入由所有较早层的特征映射组成,其输出传递给每个后续层。特征映射与深度级联聚合。
训练技巧drop-path
尽管ResNet在许多应用中已被证明很强大,但它的主要的缺点是,更深层的网络通常需要几周的时间进行训练,而这在实际应用中几乎不可行。为了解决这个问题,引入了一种在训练过程中随机丢弃图层的反直觉方法,同时使用完整的网络进行推理。
作者使用残差块作为其网络的构建块,因此,在训练期间,当特定残差块被启用时,它的输入在身份近路和权重层流动,否则,输入只在身份近路流动。在训练时间内,每层都有“生存概率”,随机下降。在测试时间内,所有的块都保持活动状态,并在测试期间根据其生存概率进行重新校准。
类似于Dropout,训练具有随机深度的深层网络可以被视为训练许多较小ResNets的合集。不同之处在于,该方法随机丢弃整个图层,而Dropout在训练期间仅将一部分隐藏单元下降。
大大降低了训练时间。甚至我们可以在训练完成后,删除部分layer,同时还不影响精度。















 1964
1964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









